







在多模态大模型(MLLMs)的研究中,如何将视觉理解能力与语言模型相结合,以实现更精细的区域描述和推理,是一个重要的研究方向。先前的工作如Ferret模型,通过整合区域理解能力,提升了模型在对话中的指代能力。然而,这些方法通常基于粗糙的图像级对齐,缺乏对细节的精细理解。为了解决这一问题,研究者们开始探索如何提升MLLMs在详细视觉理解任务中的表现。

Ferret-v2在识别小区域内的对象和文本方面相较于Ferret的优越性。图中放大了特定区域以便更清晰地展示
(b) Quantitative Result
展示了Ferret-v2在需要详细区域和全局推理理解的任务上的显著性能提升,所有模型均使用7B参数规模
方法
Ferret模型的设计原则集中在自然图像中空间参照和定位的能力上。它通过开发混合区域表示方法,能够处理包括点、框或自由形状在内的各种类型的区域。Ferret使用离散坐标标记和连续区域特征,以及在可用时的区域名称,来表示每个区域。这种表示方法使得Ferret在多样化和详细程度不同的自然图像中表现出色。
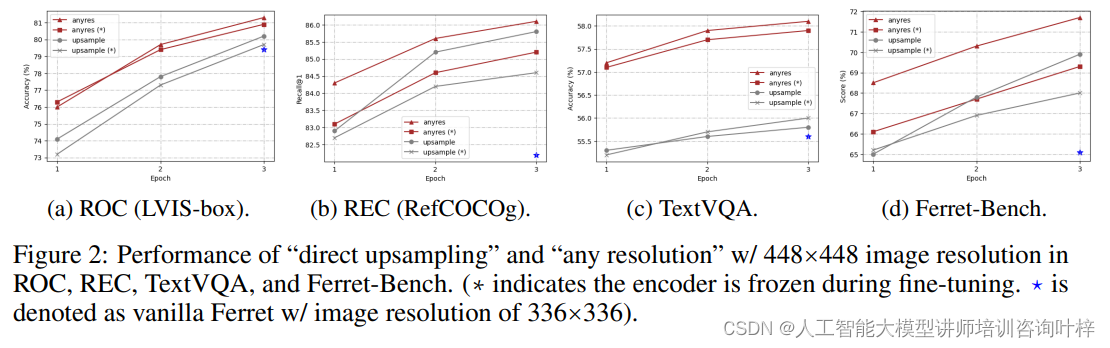
为了克服预训练固定视觉编码器的分辨率限制,Ferret-v2对高分辨率扩展方法进行了深入研究。通过对比“直接上采样”和“任意分辨率”两种方法,研究者们评估了它们在视觉细节分析、分辨率关键的OCR任务以及推理MLLM基准上的表现。研究发现,“任意分辨率”方法在利用图像细节的同时,更好地保留了预训练期间获得的知识,为有效扩展提供了优势。
Ferret-v2的模型架构包括以下几个关键技术:
多粒度视觉编码:Ferret-v2采用CLIP编码器处理全局图像,同时使用DINOv2编码器处理局部分割图像。这种设计利用了CLIP在图像级语义捕捉上的优势,以及DINOv2在局部对象细节捕捉上的能力。此外,为两种视觉编码器配备独立的MLP投影器,以更全面地理解和表示全局和细粒度的视觉信息。
任意分辨率参照:Ferret-v2通过融合全局图像特征和局部细节特征,提高了对高分辨率图像中小物体的识别能力。通过空间感知视觉采样器提取连续区域特征,结合离散坐标,形成混合区域表示,以指代图像中的任何区域。
任意分辨率定位:模型结合全局图像和局部子图像的视觉嵌入,更有效地揭示高分辨率中的视觉细节,并桥接语义信息,实现精确的区域定位。
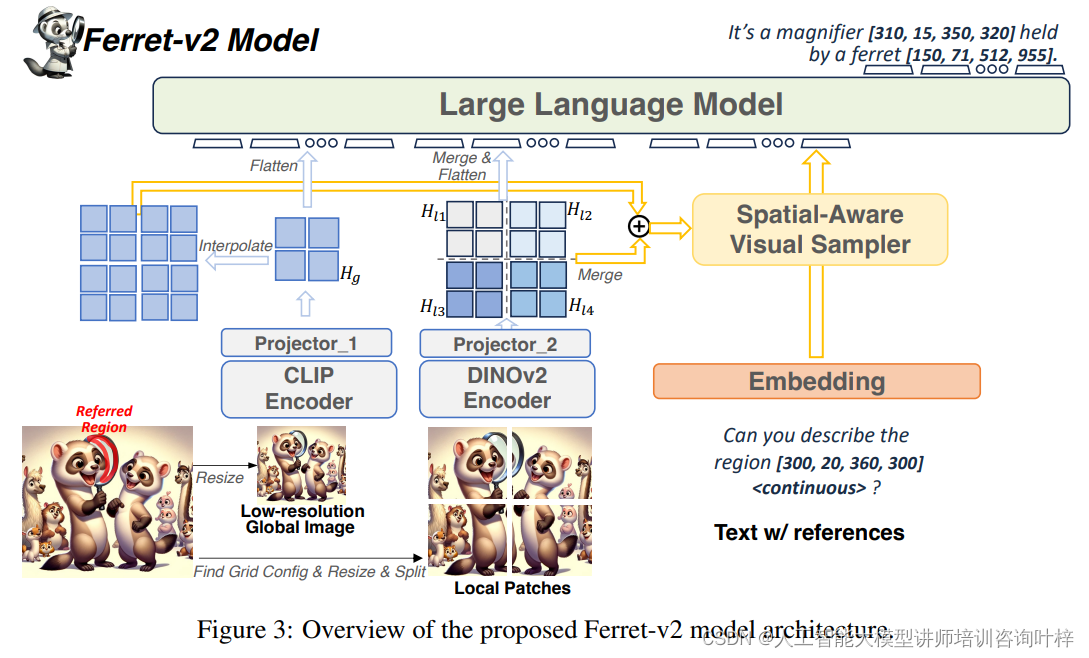
图3提供了Ferret-v2模型架构的概览。这个架构图展示了模型如何通过不同的组件和步骤来处理视觉和语言信息,以实现高效的指代和定位能力。
输入层:Ferret-v2模型的输入包括图像和相关的文本引用。图像首先被分割成多个局部区域(patches),这些局部区域以及整个低分辨率的全局图像都将被送入模型。
图像分割:为了处理任意分辨率的图像,Ferret-v2将高分辨率的图像分割成多个小的图像块,这些图像块将分别被编码以捕获局部细节。
CLIP和DINOv2编码器:模型使用两种视觉编码器。CLIP编码器处理低分辨率的全局图像,以捕获整体场景的上下文信息。DINOv2编码器则处理分割出来的局部图像块,以识别局部区域的细节,如形状或纹理。
MLP投影器:对于每种类型的编码器,都有一个与之对应的多层感知器(MLP)投影器。这些投影器将编码器的输出映射到一个共同的特征空间,使得全局和局部特征可以被进一步合并和处理。
特征融合:局部图像块的特征图在空间上重新排列并合并成一个大的特征图,然后通过上采样将全局图像的特征图与局部特征图对齐,以便在相同的分辨率下进行特征融合。
空间感知视觉采样器:Ferret-v2利用空间感知视觉采样器来提取连续的区域特征,这些特征随后与离散坐标结合,形成混合区域表示,以便于模型进行精确的区域指代。
任意分辨率指代和定位:模型能够处理任意分辨率的图像,并准确地指代和定位图像中的特定区域。这是通过融合全局和局部特征来实现的,以提供丰富的语义信息和对细节的敏感性。
语言模型:所有视觉特征最终被输入到一个大型语言模型(LLM)中,该模型负责理解和生成与视觉信息相关的文本输出。
训练过程:模型训练遵循“粗到细”的策略,从低分辨率的图像-标题对齐开始,逐步过渡到高分辨率的密集对齐,最后进行指令微调,以提高对用户意图的理解。
Ferret-v2模型的训练遵循一个“从粗到细”(Coarse-to-Fine)的多阶段训练策略,这种策略确保了模型能够逐步学习并掌握从全局到局部的复杂视觉和语言任务。图4展示了这一训练范式的概览,其中包括三个主要阶段,并且在每个阶段中,某些模块(用雪花符号表示)是冻结的,即它们的参数不会在训练过程中更新。
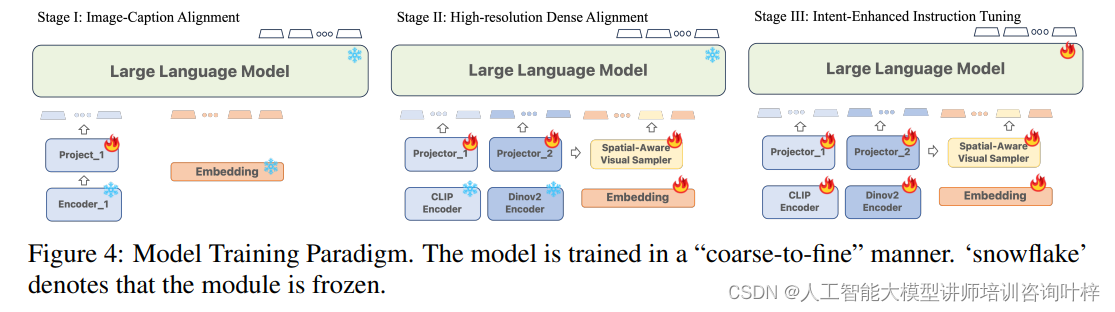
第一阶段:图像-标题对齐 (Image-Caption Alignment)
在这个阶段,模型使用大量的图像-文本对来学习视觉和语言之间的基本对应关系。此阶段的目的是将预训练的CLIP编码器与大型语言模型(LLM)进行对齐,以便它们可以共同处理图像和文本信息。在这个阶段,图像编码器和LLM的参数是冻结的,只有投影器(Projector)是可训练的。这有助于模型在保持计算效率的同时学习图像和文本之间的初步对应。
第二阶段:高分辨率密集对齐 (High-resolution Dense Alignment)
第二阶段旨在弥合图像-标题对齐和指令微调阶段之间的差距。在这个阶段,模型被训练以识别图像中每个可能的局部对象,并与详细的语义信息进行对齐。这包括密集指代和密集检测任务,模型需要对图像中的所有对象进行分类和定位。为了实现这一点,研究者们采用了DINOv2编码器来处理局部区域,同时CLIP编码器继续处理全局图像。在这个阶段,只有投影器和视觉采样器是可训练的,而两个视觉编码器和LLM的参数保持冻结。
第三阶段:意图增强指令调整 (Intent-Enhanced Instruction Tuning)
最后一个阶段的目标是在保持高分辨率视觉感知能力的同时,增强模型遵循用户指令的能力。在这个阶段,所有的组件——包括编码器、投影器、区域采样器和LLM本身——都是可训练的。模型使用特定的数据集进行训练,这些数据集包括VQA和OCR任务的伪标签数据,以及通过特殊提示增强的指令。这个阶段的训练进一步细化了模型对用户指令的理解和执行能力。
训练范式的创新点:
-
逐步解锁:通过逐步解锁模型的不同部分进行训练,Ferret-v2能够在学习过程中逐步构建更为复杂和精细的表征能力。
-
多阶段学习:每个训练阶段专注于不同的学习目标,从基础的图像-文本对齐到复杂的高分辨率密集对齐,最终实现对用户指令的精确理解和执行。
-
冻结与微调:在训练过程中,适当地冻结某些模块有助于稳定学习过程,同时微调其他模块以适应特定的训练目标。
通过这三个阶段的训练,Ferret-v2不仅提升了对高分辨率图像的处理能力,还增强了对用户指令的理解和执行,使其在多模态任务中表现出色。
实验
Ferret-v2在参照对象分类(Referring Object Classification, ROC)任务中的表现通过其准确识别查询中提到的图像区域中的对象来评估。实验使用了LVIS数据集的验证分割,该数据集涵盖了1000多个对象类别,并且大多数是“领域内”图像。为了进一步展示Ferret-v2在引用更小对象方面的改进能力,研究者们还使用SA-1B的部分图像和AS-human中的对象注释创建了一个“野外”评估集,该评估集包含高分辨率图像、开放词汇表对象和精确的掩膜。
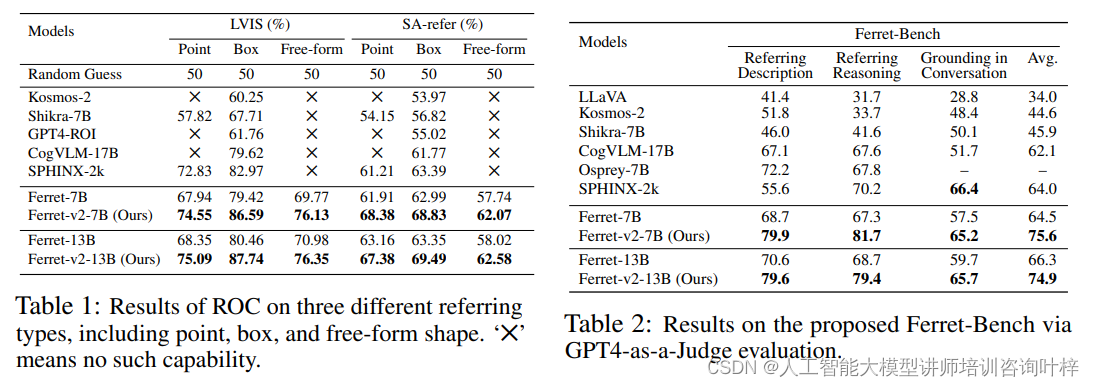
Table 2:评估了Ferret-v2在多模态对话模型中的细粒度能力。在Ferret-Bench基准测试上的评估结果,包括参照、grounding、描述、推理和对话等任务的平均性能
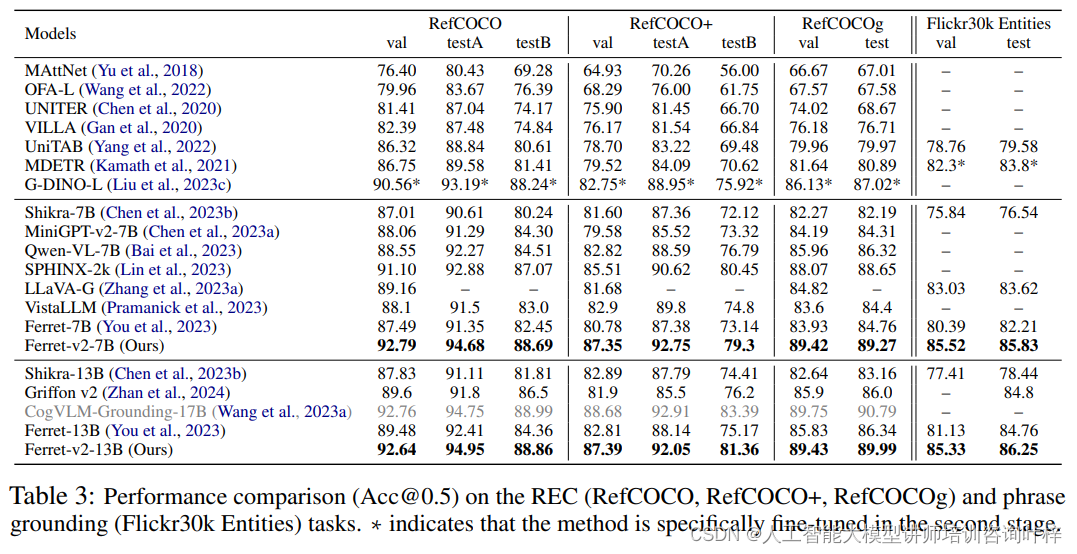
在视觉grounding方面,Ferret-v2旨在将语言查询定位到图像中的对应区域。实验在包括RefCOCO、RefCOCO+和RefCOCOg在内的著名benchmark上进行,以及使用Flickr30k Entities数据集进行短语grounding任务。Ferret-v2通过使用高分辨率输入图像,显著提高了性能,并在大多数现有模型上取得了更好的结果。
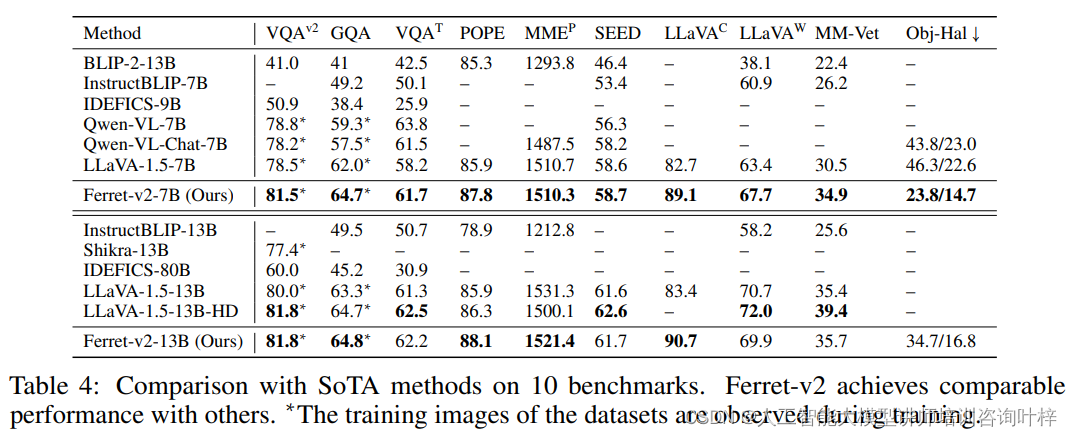
为了测试Ferret-v2在更广泛的任务上的适用性,研究者们将其与现有的多模态大型语言模型(MLLMs)在多个基准测试上进行了比较。这些基准测试包括VQAv2、TextVQA、GQA、POPE、MMEP、SEED、LLaVAC、LLaVAW、MM-Vet和Obj-Hal等。Ferret-v2在这些基准测试上的表现与最新的技术相当,特别是在需要精确空间信息以准确响应的任务上表现出色。
Ferret-v2还在Ferret-Bench上进行了评估,这是一个专门设计用于评估和基准测试多模态对话模型的细粒度能力的测试,特别是在图像中引用、描述和推理特定区域的能力。Ferret-v2在所有类型的任务中都展示了其优越的性能,表明了模型在空间理解和常识推理方面的强大能力。
实验结果表明,Ferret-v2在指代和定位任务上取得了显著的性能提升。这主要归功于其高分辨率处理能力、细粒度视觉编码和三阶段训练方法。与现有技术相比,Ferret-v2不仅在特定任务上表现出色,而且在更广泛的基准测试中也展现了其强大的多模态理解能力。这些结果证明了Ferret-v2在多模态AI领域的潜力,并为未来的研究和应用提供了新的方向。
消融研究
为了深入理解Ferret-v2模型中各个组件的作用和重要性,研究者们进行了一系列的消融研究。这些研究旨在评估任意分辨率的grounding和referring技术,以及多粒度视觉编码和第二阶段预训练对模型性能的具体影响。
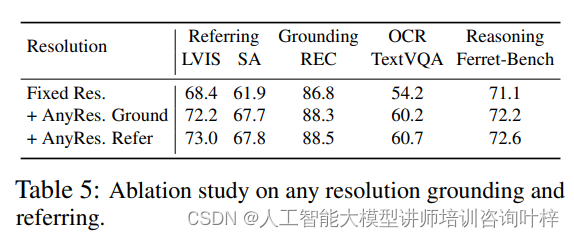
通过对比固定分辨率和任意分辨率的方法,研究者们评估了处理更高分辨率图像的能力对于模型性能的影响。结果显示,任意分辨率的方法在LVIS和SA数据集上的referring任务中显著提高了精度,这表明了在需要理解更高分辨率细节的任务中,任意分辨率的方法能够提供更精确的区域识别。消融研究还发现,任意分辨率的方法在grounding任务上也有小幅提升,这暗示了在Ferret-v2的框架内,grounding和referring能力可以相互受益。
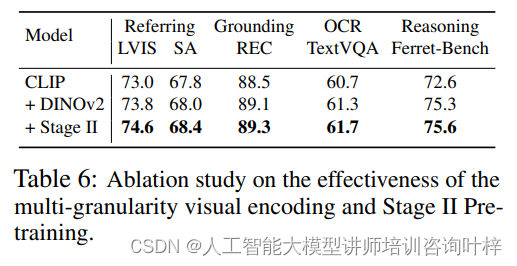
进一步的消融研究集中在多粒度视觉编码的有效性上,特别是集成了DINOv2编码器来处理高分辨率图像补丁。研究者们使用CLIP的投影器权重作为初始化,并在第三阶段进行微调。结果显示,仅使用视觉粒度编码就显著提高了referring和grounding的性能。
引入第二阶段预训练,即高分辨率密集对齐阶段,也在所有评估指标上带来了性能提升。这表明通过在预训练过程中增加这一阶段,模型能够更有效地学习细粒度的语义信息,从而在下游任务中表现更好。
Ferret-v2作为Ferret模型的重要升级版,通过先进的任意分辨率处理能力、多粒度视觉编码和创新的三阶段训练流程,在图像处理和理解方面实现了显著的性能提升。尽管如此,Ferret-v2仍有可能产生有害或错误的事实性回应,这是未来工作中需要进一步解决的问题。
论文链接:https://arxiv.org/abs/2404.07973















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









