









文章目录
- 问题是什么
- 论文合集
- 2020
问题是什么
尽管在CNN的端到端表示学习帮助下,re-ID的性能得到了显著提升,但是还有两个问题没有解决。
两个没有解决的问题:
-
第一个问题是判别特征学习。
作为一个实例级识别任务,在不相交的摄像机视图下重新识别人需要克服类内变化大和类间模糊两大困难。 -
第二个问题是通用特征学习。
由于光线条件、背景、视点等方面的差异造成的re-ID数据集之间存在固有的区域差距(见图1),直接将在源数据集上训练的re-ID模型应用到不可见的目标数据集上,通常会导致的性能大幅下降 (所以需要域适应)。
这表明所学习的re-ID特性严重地过拟合标记数据,并且不能进行区域泛化。

在图1(a)中,相机之间的视角变化(从正面到背面)给背包区域带来了较大的外观变化,使对同一个人的匹配变得具有挑战性。此外,从远处看,就像在监控视频中常见的那样,人们看起来非常相似,如图1中的错误匹配就是一个例子。这需要使用re-ID特性来捕获细微的细节(例如,图1(d)中的太阳眼镜),用以区分具有相似外表的人。
论文合集
1、OSNet : Learning Generalisable Omni-Scale Representations for Person Re-Identification (一种通用全尺度表示方法)
有效的行人再识别模型应该学习特征表示,这些特征表示既可以用于区别外观相似的人员,又可以在无需任务调整下用于跨数据集部署。
全尺度网络(OSNet)的CNN来学习特征,它不仅可以捕捉不同的空间尺度,而且可以封装多个尺度的协同组合,即全尺度特征。
基本构建块由多个卷积流组成,每个卷积流检测一定范围内的特征。对于全尺度特征学习,提出了一种统一的聚合门,将多尺度特征与信道权值动态融合。
OSNet是轻量级的,因为它的构建块包含分解卷积。
为了改进通用特征学习,我们在OSNet中引入实例规范化层来处理跨数据集的差异。为了确定这些层在体系结构中的最佳位置,我们提出了一种有效的可微体系结构搜索算法。
解决 跨数据集准确性、 类内变化、类间模糊
要消除图1(b)(右)中的冒名顶替者,需要在前面具有特定标识的白色T恤上添加一些特征。
如果没有白色T恤作为背景,它可能会与许多其他图案混淆。同样,白色T恤在夏天随处可见(如图1(a))。它是独特的组合,由跨越小(标志尺寸)和中(上身尺寸)尺度的异构特性捕获,这使得这些特性最有效。
由不同re-ID数据集造成的差距,我们注意到这些差距通常反映在不同的图像样式,如亮度、颜色温度和角度(参见图1)。这些风格差异是由不同的照明条件和相机/设置在不同的摄像机网络特征。
现有的工作使用无监督域适应(UDA)方法解决了这个问题。这些需要未标记的目标域数据来进行模型调整。
相反,我们将其视为一个更一般的域泛化问题,而不使用任何目标域数据。通过消除给定新目标域的数据收集和模型更新的繁琐过程,使用我们的方法,可以对任何未知的目标数据集开箱即用地应用使用源数据集训练的re-ID模型。
结构
全新的CNN体系结构OSNet(Omni-scale Network,OSNet),它是专门为学习全尺度特征表示设计的。
托换构建块(building block)由多个不同的卷积特征流组成(如图2所示),每个流所关注的特征尺度由指数(exponent)决定,指数是一个新的维度因子,跨流线性增加,以确保每个块中捕获不同尺度。

AG是一种跨所有流共享参数的子网络,具有许多有效的模型训练所需的特性。 在可训练的AG下,生成的信道权值依赖于输入,从而实现了动态尺度融合。
这种新颖的AG设计为全尺度特征学习提供了极大的灵活性: 根据特定的输入图像,门可以通过为特定的流/尺度分配主导权重来聚焦于单个尺度;或者,它可以选择和混合,从而产生异构的特征尺度。
创新点
1、动态尺度融合: 统一聚和门AG: 信道全职,分配权重聚焦不同尺度(全局、衣服、图案、鞋子)
2、轻量级: 将标准卷积分解为点卷积和深度卷积,使OSNet不仅在特征学习上有区别,而且在实现和部署上也很高效。
3、通过消除给定新目标域的数据收集和模型更新的繁琐过程,使用我们的方法,可以对任何未知的目标数据集开箱即用地应用使用源数据集训练的re-ID模型。

最后,为了增强对不可见数据集的通用性,我们通过实例规范化(IN)扩展了OSNet,并进一步提出了一个可区分的架构搜索机制来自动推断最优的布局。
OSNet 性能对比

在本文中,我们提出了一种轻量级的CNN架构OSNet,它能够学习人的全方位特征表示。与现有的ReID CNNs相比,OSNet具有在每个构建块内显式学习多尺度特征的独特能力,其中统一聚合门动态融合多尺度特征生成全尺度特征。
为了改进跨域的泛化,我们通过可微架构搜索为OSNet配备了实例规范化,从而产生了一种称为OSNet- ain的域自适应变体。在相同域的re-ID设置中,结果显示OSNet在比基于resnet的竞争对手小得多的同时,还能达到最先进的性能。
在跨域的ReID设置中,OSNet-AIN在不可见的目标数据集上表现出了非凡的泛化能力,甚至在没有对目标域数据进行每域模型自适应的情况下,也击败了最新的UDA方法。
2020
车辆重识别: 多域学习与身份挖掘 Multi-Domain Learning and Identity Mining for Vehicle Re-Identification

baseline : re-id : bag of tricks (BoT-BS)

https://github.com/heshuting555/AICITY2020_DMT_VehicleReID.
Multi-domain learning method
synthetic data and real-world 联合合成信息和真实世界信息 用于训练网络
先对合成数据进行预训练,根据现实世界微调。
Identity Mining method
Some unsupervised methods, such as the k-means clustering, can be adopted to generate pseudolabels for the testing data.
However, the pseudo labelsare not accurate enough because of the poor performanceof ReID models.Therefore, We propose the Identity Min-ing (IM) method to generate more accurate pseudo labels
IM selects some samples of different IDs with high confi-dence as clustering centers, where only one sample of eachidentity can be selected. Then, for each clustering center,some similar samples are labeled with the same ID. Differ-ent from the k-means clustering dividing all data into sev-eral clusters, our IM method just automatically labeled apart of data with high confidence.
IM选取可信度较高的不同id的样本作为聚类中心,每个IDs只能选择一个样本。
然后,对于每个聚类中心,用相同的ID标记一些相似的样本,不同于k-means聚类将所有数据分为多个聚类,我们的IM方法只是自动标记出高置信度的数据。
K-means 聚类不能提供准确的伪标签。

每一步都可以用新的ID标记一个样本,黄色圆圈的半径是负样本对的距离阈值。
黄色圆圈外的样本是满足距离约束的候选样本。
使用自动注释的labe 来训练模型,性能变差了。
query : Q
gallery set : G
query : Q : 待查询的样本集合
gallery set : G : 全部的样本集合
Stage t :
- 1、 Stage1 : L := {L1, L2, L3 … Lt} l1 随机初始化
- 2、计算距离矩阵: Dist(L,Q) 、定义距离阈值。
- 3、目标: 找到新ID 添加到 L
- 4、qi 作为候选, 在黄色圆圈里面的qi ,作为候选。
- 5、为了避免多个候选满足这个约束: 选择最不相似的候选
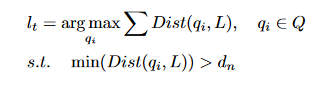
就是使后面这个式子达到最大值 , 时候, q 的曲子。 是的 q 在L中的距离, 达到最大值。
下一时刻的l , = 使得 和当前L里面最远的qi 和现有L里面距离最远的qi 。 这个qi 的距离得在阈值外。
q和L的最小距离在距离范围外。
L 包含几个 不同的样本, 第二部挖掘


优点: 自动生成聚类中心,在第一个stage , 不需要知道类数量
缺点: 局部优化 , 对初始化L样本敏感。
下一步: 关注全局优化问题, 有潜力比pseudo labels 聚类方法更好: global optimization problem
a tracklet-level re-ranking strategy
CVPR 2020 : Multi-Granularity Reference-Aided Attentive Feature Aggregationfor Video-based Person Re-identification
未开源
基于视频的多粒度参考辅助注意特征聚合方法

















 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









