







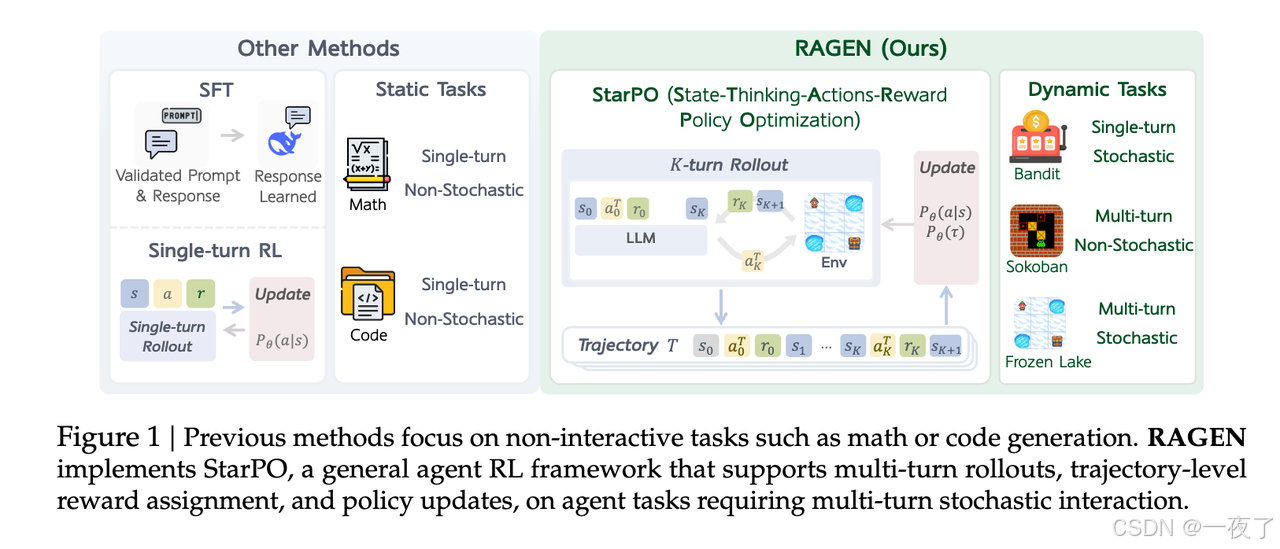
1. 简介
本文提出了StarPO(State-Thinking-Actions-Reward Policy Optimization)),这是一个轨迹级智能体强化学习的通用框架,并引入了RAGEN,这是一个用于训练和评估LLM智能体的模块化系统。随后分析了智能体学习的三个维度并总结了下面的发现:
- Multi-turn RL训练稳定的关键是gradient stablility:在multi-turn Rl训练中经常出现Echo Trap,一种经常出现的不稳定pattern。主要是因为agent在locally rewarded reasoning patterns中过拟合,表现为reward variance奔溃,entropy drop和gradient spike。为了解决这个问题,本文提出了StarPO-S,通过variance-based trajectory filtering,critic baselining和decoupled clipping三个操作优化训练稳定性。
- Rollout Frequency and Diversity Shape Self-Evolution:RL训练中,LLM自己生成rollout trajectories用于训练。其中关键的rollout factors是:1)确保rollouts来自不同的prompt及每个prompt有多个responses。2)在固定的回合限制内,每回合执行多个动作,提高互动范围。3)保证一个较高的rollout frequency(指rollout batch size小一点?)。
- Emerging Agent Reasoning Requires Meticulous Reward Signal:简单的在action中奖励reasoning不确保有reasoning行为。当没有明确的reasoning reward时,即使模型被prompted to reason,模型也会被训练的直接生成action操作。所以需要一个fine-grained,reasoning-aware reward signals。
2. 框架
2.1 StarPO: Reinforcing Reasoning via Trajectory-Level Optimization

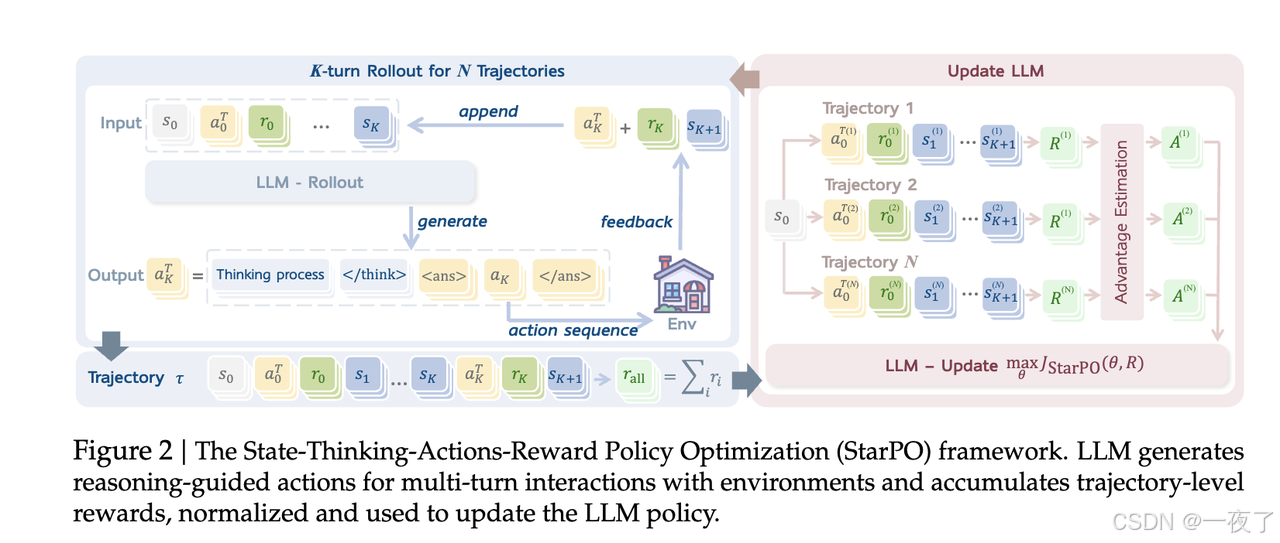
2.1.2 Optimization Procedure: Reasoning-Interaction Trajectories
在每个训练迭代中,agent初始状态为
S
0
S_0
S0,然后生成N个trajectories,生成的每个step中,结果为:
a
t
T
=
<
t
h
i
n
k
>
.
.
.
<
/
t
h
i
n
k
>
<
a
n
s
w
e
r
>
a
t
<
/
a
n
s
w
e
r
>
a_t^T=<think>...</think><answer>a_t</answer>
atT=<think>...</think><answer>at</answer>
其中
a
t
a_t
at表示需要执行的action(tool调用),然后环境返回下一个
s
t
+
1
s_{t+1}
st+1和reward
r
t
r_t
rt,完整的轨迹为:
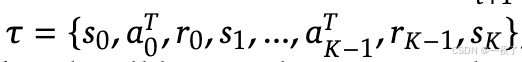
2.1.3 Modular Optimization Strategies


2.3 The RAGEN System
RAGEN支持structured rollouts,定制化reward functions和整合多轮,随机的交互环境。
3. 实验与发现
3.1 环境和任务
- 三个游戏任务


3.2 Settings
- Model:Qwen-2.5-0.5B
- 200 rollout-update iterations
- 每个batch,8个prompts,n_samples_per_prompt:16,最大5轮,10个action
- 算法:PPO(GAE lambda=1, gamma=1) or GRPO
- Adam optimizer
- entropy bonus:beta=0.001
- response-format penalty:-0.1
- KL coefficient:0.001,k1 estimation,without KL loss term
3.3 Evaluation Metrics
- 256 prompts, temperature=0.5,最大5轮,10个action
- metrics(smoothed using exponential moving average (EMA)):
- average success rate:验证集任务完成比例
- rollout entropy(exploration):Computes the average token-level entropy of sampled responses, capturing the exploration level and policy uncertainty. A sharp entropy drop may indicate premature policy convergence or collapse
- in-group reward variance(behavioral diversity):高in-group reward variance表示多样行为和学习潜力。突然奔溃表示奖励同质化和学习停滞。
- response length(reasoning verbosity):每次rollout生成的令牌的平均数量,测量agent的冗长性和推理深度。长度的波动可能表明planning风格或信心的变化
- gradient norm(training stability):l2 norm of the policy gradient vector。Spikes often correlate with phase transitions in policy behavior or unstable reward signals
3.4 实验结果和发现
3.4.1 Multi-turn agent RL training introduces new instability pattern
Finding1: 单轮的RL不能只用用于多轮RL训练,训练早期会有收益,后面会崩溃。PPO中的critic会延缓不稳定,但不能延迟推理退化。
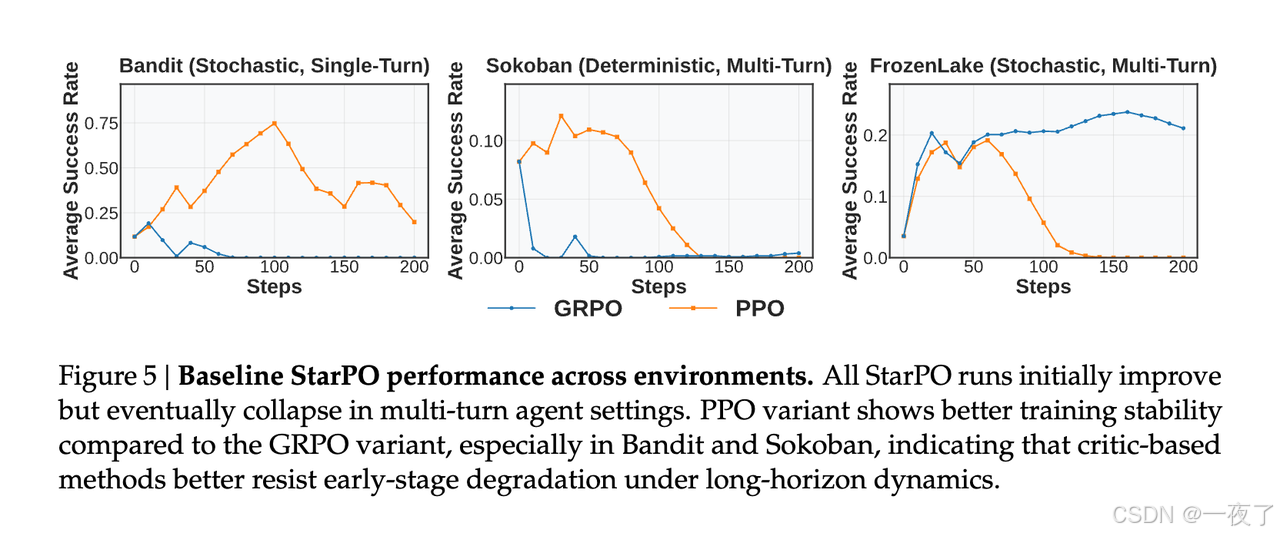
早期的推理结果多样性好,reward正常。后期推理结果会有很多的重复和确定性。这种错误的mode称为“Echo Trap”。Finding2: 模型收敛于固定的phrasing,这表明强化学习可能会强化表面模式,而不是一般推理,并形成阻碍长期泛化的“Echo Trap”。

为了更进一步定位问题,前期观测几个指标1)Reward Standard Deviation(用于判断rollout是多样的还是重复的。)2)Output Entropy(捕捉模型输出的不确定性,突然下降表示policy变的过于自信且倾向于窄的推理路径。)。3)Average Reward。 4)Gradient Norm(衡量更新的幅度,spike表示小的迭代就会带来大的改变,表示训练不稳定和崩溃)。
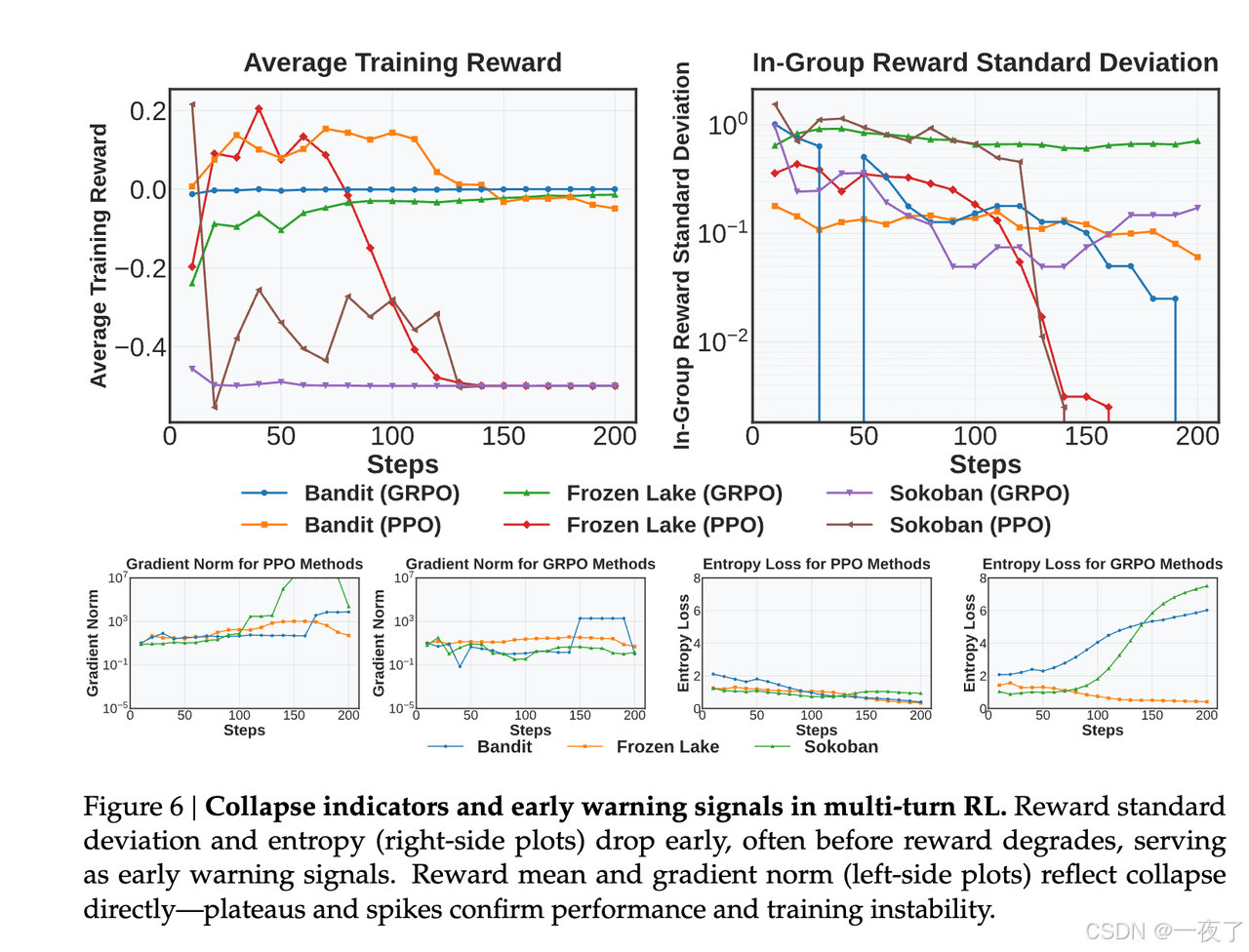
从上图中可以看出,关于多回合智能体RL中模型崩溃如何展开,我们得出以下结论:
- Reward standard deviation could be a reliable early signal:在FrozenLake-PPO中,reward mean在90步崩溃,reward standard deviation则在40步。在Bandit-PPO中,reward standard deviation在70步触底,reward mean则在120步。在Sokoban-PPO中,基本都是在10步崩溃。
- Gradient norm spikes indicate irreversible collapse:一旦170(Bandit),110(Sokoban),90(FrozenLake)出现gradient norm spike,之后恢复就变的不可能了。
- Entropy typically follows a stable decay trend during effective learning:entropy的极速增加或不稳定往往会带来崩溃。(eg. GRPO on Bandit and Sokoban)
Finding3: 崩溃遵循类似的规律,可以通过指标预测,Reward standard deviation and entropy会在表现下降之前变动,gradient norm spike预示不可逆的崩溃。
3.4.2 StarPO-S: Stabilize Multi-turn RL with instance filtering and exploration encouragement
- 过滤掉low-variance rollouts能缓解collapse
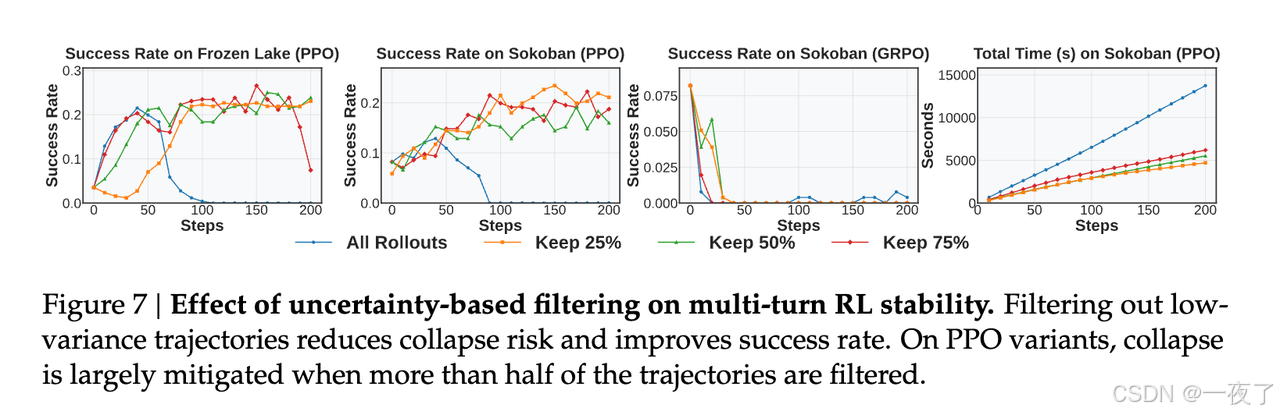
- 在FrozenLake任务中,75%的保留比例,将崩溃点从100延迟到140。
- 50%的保留比例消除了崩溃
- 保留high-variance samples会改进训练效率,可以看最右边的图。
- 最后,保留比例默认使用25%。
Finding4: 过滤掉low-variance trajectories会改进训练稳定性和效率。
除此之外,还采用了DAPO中的两种策略:
- KL Term removal:在PPO objective中删掉了KL divergence penalty。
- clip-Higher(asymmetric clipping):using a higher upper bound(0.28),lower bound(0.2)」
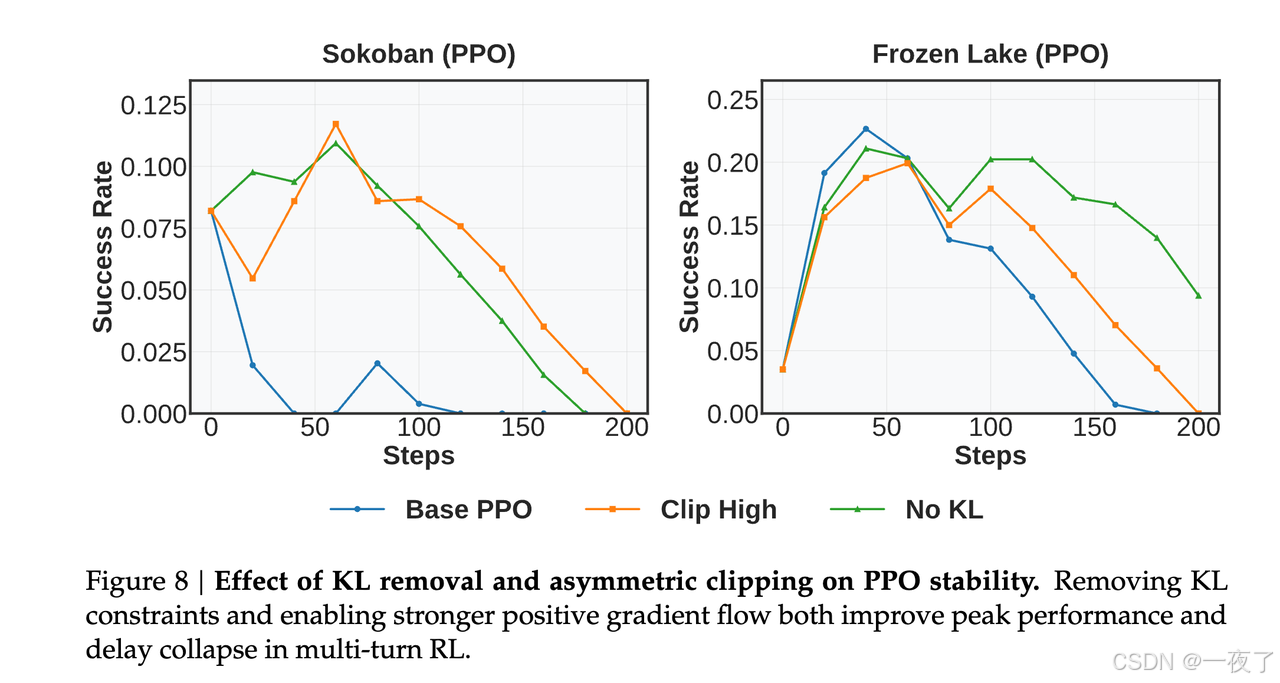
全面对比:
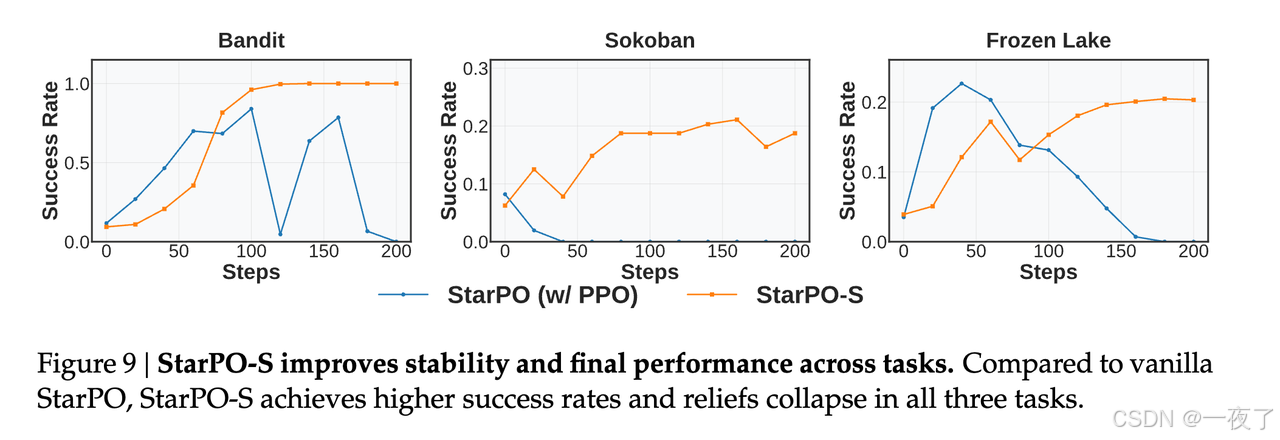
3.4.3 Generating Useful Trajectories for RL Training
显著影响学习动态和泛化性的三个因素:task diversity,interaction granularity和rollout frequency。
- Higher task diversity with response comparison improves generalization:多样化的提示集将模型暴露在更广泛的决策环境中,有助于在记忆行为之外的泛化。在固定的batch size下,任务多样性与每个提示的response数量成反比。从下图中可以知道更高的task diversity,每个prompt更少的responses会有更好的泛化性。
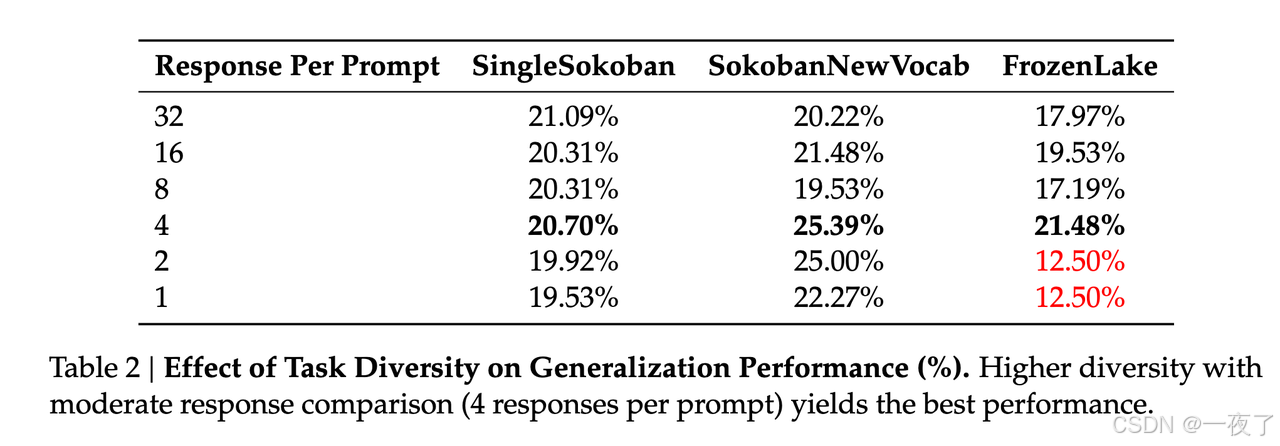
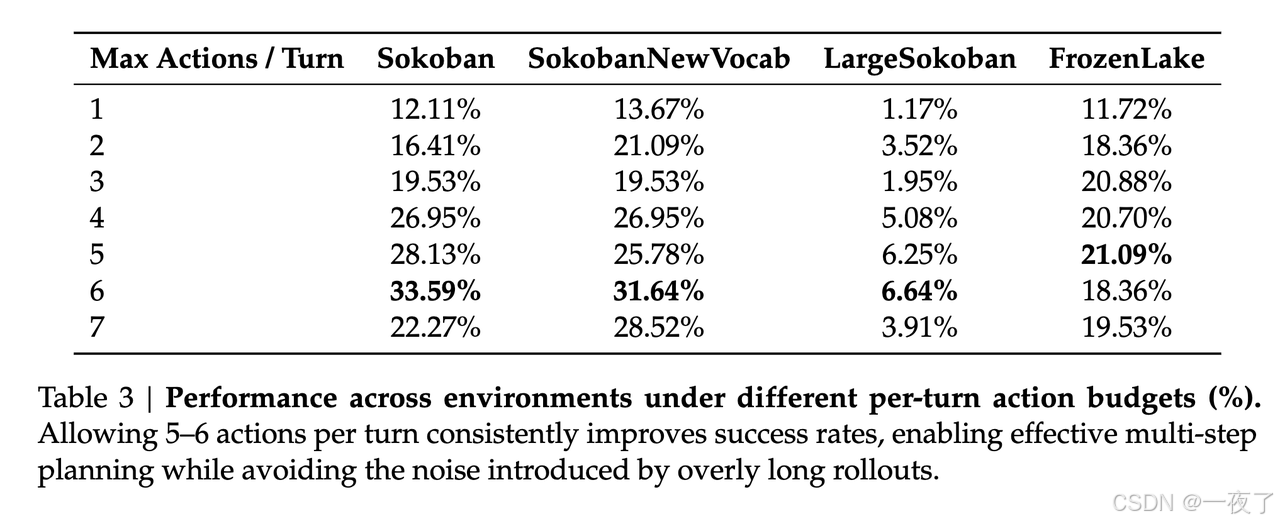
- Allowing more action budgets enables planning, while overly long rollouts inject noise:每轮执行最多5,6个action,效果最佳。
- Frequent rollout updates ensure alignment between optimization targets and current policy
behavior.当轨迹数据反映agent最近的行为时,学习是最有效的。频繁的采样可以减轻策略数据不匹配,并防止使用过时的策略状态进行优化。
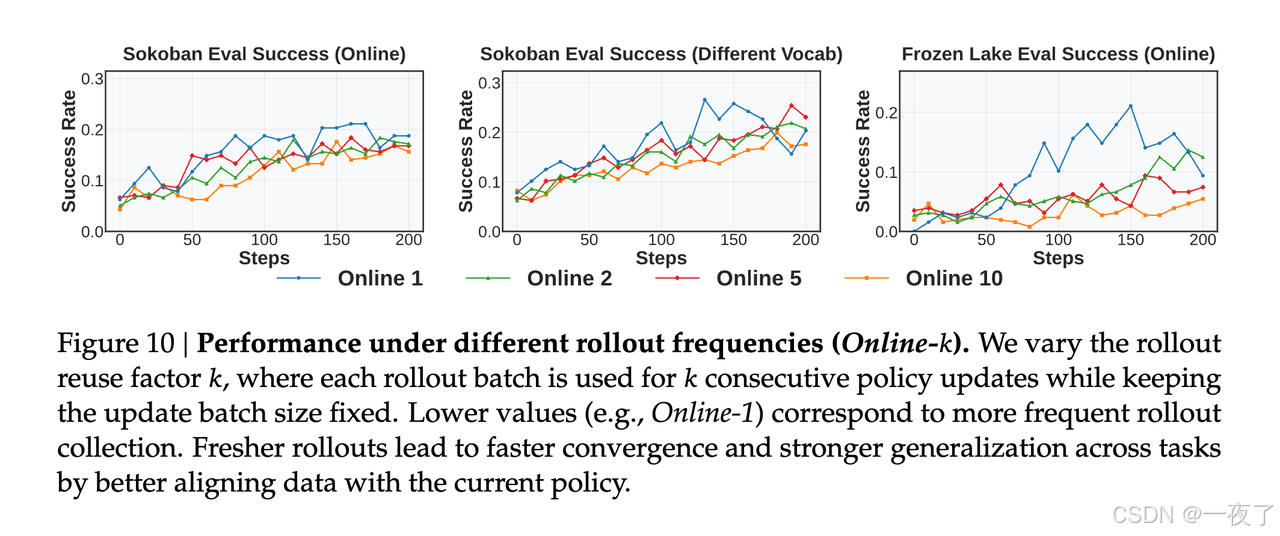
- Frequent rollout updates align optimization with the current policy and stabilize learning:见上图。
Finding5: Task diversity, action budget, and rollout frequency affect data quality
3.4.4 Reasoning Emerges in Single-Turn Tasks but Fails to Grow in Multi-Turn Settings Without Fine-Grained Reward Signals
- Reasoning traces improve symbolic generalization in single-turn Bandit tasks:reasoning traces有助于agent内化symbolic-reward关联,并在表面记忆之外进行泛化,即使在语义-奖励不一致的情况下也是如此
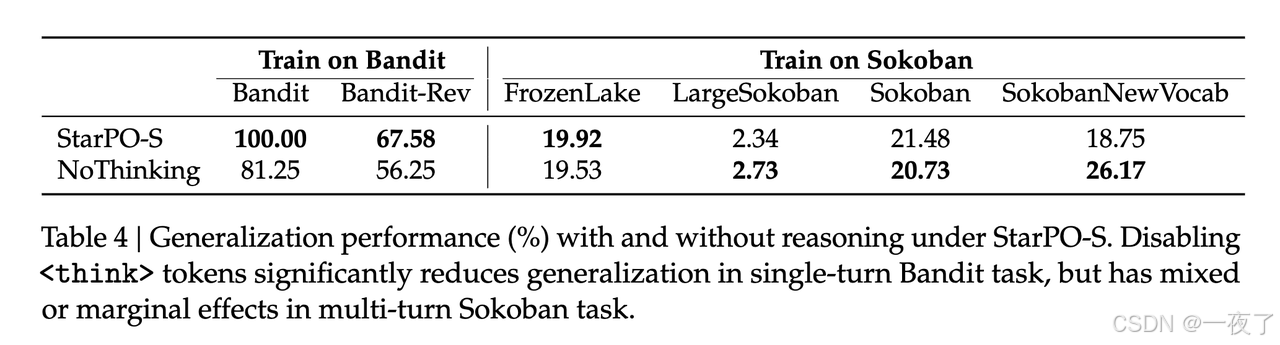
- In multi-turn tasks, reasoning signals fade as training progresses:相比之下,对于像Sokoban和FrozenLake这样的任务,推理提供的好处有限。即使将response结构化为包含片段,从提示中删除推理(无思考变体)也会产生相当甚至更好的性能。推理长度在训练过程中持续下降,表明模型逐渐抑制了自己的思维过程。有趣的是,在BanditRev中,语义标签和奖励结构是不一致的,推理痕迹往往更长,这表明代理花了更多的精力来协调符号线索和观察到的奖励。
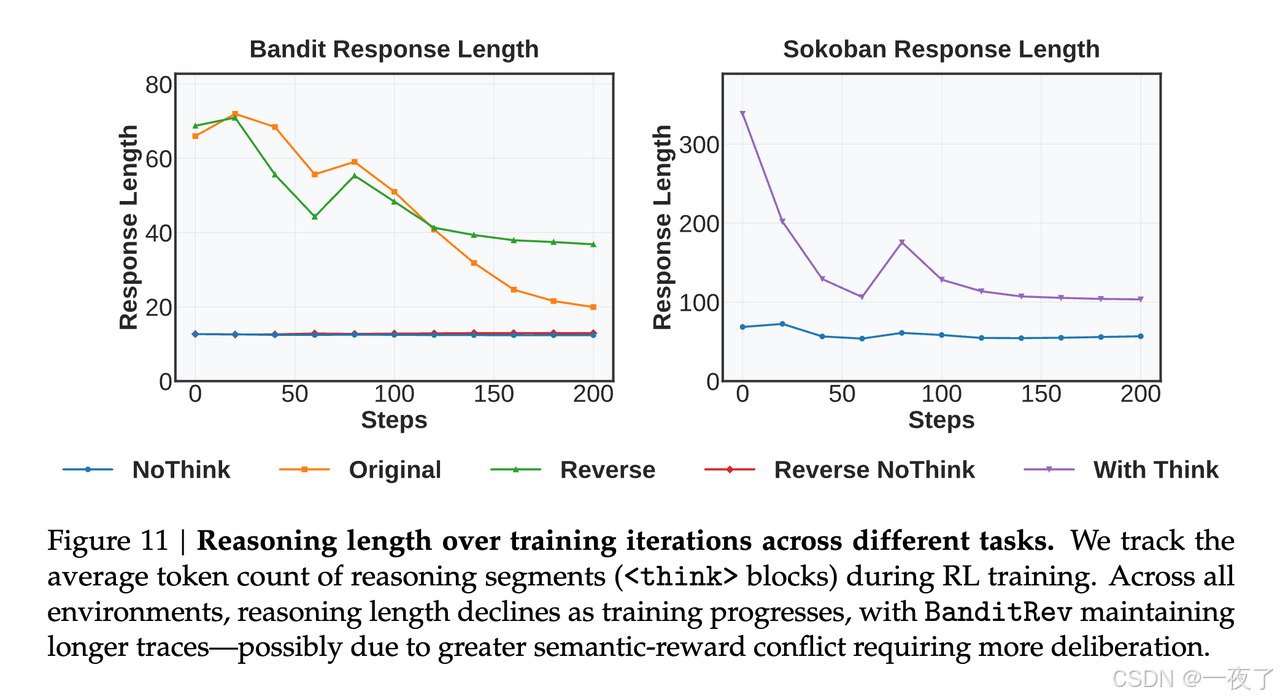
-
Reward signals in multi-turn tasks may be too noisy to reliably support fine-grained reasoning
learning:在这样的环境中,奖励信号通常是稀疏的、延迟的和基于结果的,这使得很难区分由连贯推理驱动的成功轨迹和通过反复试验获得的成功轨迹。我们观察到模型产生不连贯或幻觉推理但仍然得出正确答案的例子- how can we consistently reinforce useful reasoning when the
reward alone may not reflect its quality? 一种可能的方法是将动作正确性与推理质量解耦。 Inspired by GRPO, we apply format-based penalties: when the model fails to produce valid – structures, we reduce the reward。
Finding 6: Reasoning fails to emerge without meticulous reward design
- how can we consistently reinforce useful reasoning when the
4. 总结
- 发现PPO训练会比GRPO更稳定。
We find evidence from multiple sources that PPO could be more stable than GRPO training in Open-Reasoner-Zero, TinyZero, and Zhihu. We have changed the default advantage estimator to GAE (using PPO) and aim to find more stable while efficient RL optimization methods in later versions.
- 训练细节:
- 过滤low-variance的轨迹数据
- 在loss中删除KL divergence penalty
- clip-higher
- 数据:(可以参考)
- 确保prompt的多样性;
- 每个step可以执行多个action
- 保证一个较高的rollout frequency。让训练模型的训练更新一些。
- Finding:(可以参考一些指标的建设)
- 单轮的RL不能只用用于多轮RL训练,训练早期会有收益,后面会崩溃。PPO中的critic会延缓不稳定,但不能延迟推理退化。
- 模型收敛于固定的phrasing,这表明强化学习可能会强化表面模式,而不是一般推理,并形成阻碍长期泛化的“Echo Trap”。
- 崩溃遵循类似的规律,可以通过指标预测,Reward standard deviation and entropy会在表现下降之前变动,gradient norm spike预示不可逆的崩溃。
- 过滤掉low-variance trajectories会改进训练稳定性和效率。
- Task diversity, action budget, and rollout frequency affect data quality
- Reasoning fails to emerge without meticulous reward design,如果没有细粒度的reward设计,训练中reasoning 会逐渐消失。



















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











