









23年5月AI芯片创业公司SambaNova系统(在LLM研发中提出COE概念)的论文“On the Tool Manipulation Capability of Open-source Large Language Models”。
最近关于语言大模型 (LLM) 的软件工具操作研究主要依赖于封闭模型 API。 由于给封闭的LLM API 服务公开信息存在安全性和稳健性风险,这些模型的工业采用受到严重限制。 本文询问是否可以通过实际的人工监督,增强开源 LLM 在工具操作方面与领先的封闭 LLM API 之间的竞争力。 通过分析常见的工具操作失败,首先证明开源LLMs可能需要使用示例、上下文演示和生成风格规范进行训练来解决失败。 重新审视LLM文献中的经典方法,证明可以将它们作为模型与程序化数据生成、系统提示和上下文演示检索器相结合,以增强开源LLM的工具操作能力。 为了评估这些技术,创建ToolBench,一个工具操作基准测试,由实际任务的各种软件工具组成。 本文技术可以将领先的开源 LLM 成功率提高高达 90%,在 8 个 ToolBench 任务中的 4 个中,显示出与 OpenAI GPT-4 竞争的能力。 这种增强通常需要开发人员大约一天的时间来整理每个工具的数据,并在实际的人工监督下呈现出一个解决方法。
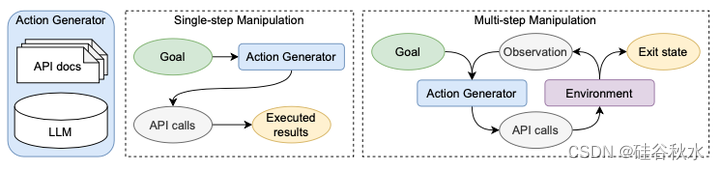
如图是工具操纵设置。 将LLM作为动作生成器,可以访问 API 文档。 在单步场景中,动作生成器直接生成 API 调用来完成目标。 多步操作生成器使用 API 调用对环境进行迭代,并根据环境中的信息生成下一步调用,直到退出状态。
研究这样的场景:软件用户打算将自然语言目标描述 g 转换为一系列应用程序编程接口 (API) 调用 C = { c0, c1, …,cng } 以实现目标。 在这个特定的环境中研究开源LLM的工具操作,因为 API 是现代软件系统中开发人员和用户的普遍抽象形式。
给定 x0 、 x1 、…、xN 作为上下文序列 ,自回归语言模型将下一个单词 xN +1 的概率进行编码[21]。通过迭代地从这个条件概率 p (xN +1 |x0 , x1 , ··· , xN ) 中采样,它可以从给定的上下文中生成语言延续。 在最近扩大模型大小和训练数据量的浪潮中,基于 Transformer 的语言模型在文本和代码生成的指令跟踪方面表现出了前所未有的能力 [22,23,24]。 在工具操作的背景下,将目标描述和可选信息作为上下文的指令,并要求LLM为 API 调用生成代码作为延续。
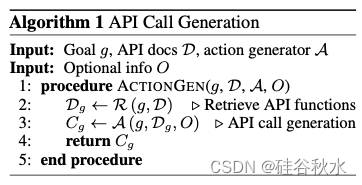
工具操作的一个关键实现是动作生成器 A,它将目标 g 映射到 API 调用 Cg。 由于开源 LLM 可能没有看到有关相关 API 的信息,因此提供一个 m 个候选 API 函数 D = {d0, d1, ··· , dm} 的池进行访问,将这个 LLM(M)增强为动作生成器。 由于 LLM 的输入序列长度限制,提供了一个可选的检索器 R 来保留 API 文档的相关子集 Dg = R (g, D) ∈ D。因此,动作生成器生成 API 调用序列 Cg = A ( g, Dg , O),其中 O 表示可以包含在提示中的可选信息。 这是一种简单的检索增强生成(RAG)方式 [18,25,26],在研究中采用了现成的检索器实现 [27],但也强烈鼓励社区探索为动作生成器量身定制的算法。
如下是API调用生成的算法总结:
如上图所示,动作生成器可以在单步或多步场景中与软件交互。 在单步场景中,动作生成器直接生成 API 调用序列 Cg = A (g, Dg , ∅)。 在多步场景中,动作生成器生成一系列 API 调用序列 Cg = ∪i (Cg,i),其中每片段 Cg,i 用于与预定义环境 E 交互并生成观察值 Oi = E(Cg,i) 。 然后使用观察结果生成新片段 Cg,i+1 = A (g, Dg, Oi)。 该过程停止在退出状态。 在本文的其余部分中,用单步设置。
为了评估开源 LLM 的工具操作能力,将它们与 OpenAI GPT-4 API 进行比较。 在这个初步比较中,最初预计封闭式LLM将在工具操作方面表现出优势,正如在传统 NLP 任务中观察到的那样 [12]。 然而,观察的差距明显大于预期。 例如,在家庭搜索任务中,开源 LLM 很难生成正确的 API 调用,导致与零样本 GPT-4 API 相比有 70% 的成功率差距,如表所示。

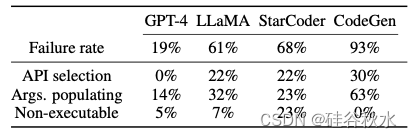
分析开源LLM在工具操作方面的行为,通过分析天气查询任务中的常见错误,发现强大的工具操作能力的三个挑战。 如表所示,开源LLM通常在 (1) API 选择、(2) API 参数填充以及 (3) 生成合法且可执行的代码等面临困难。
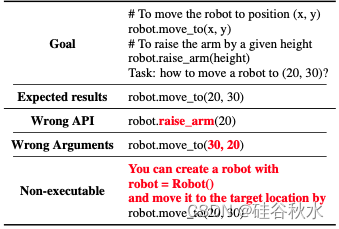
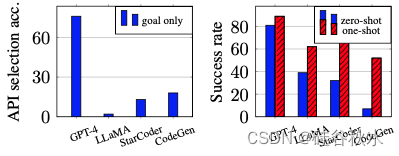
观察的是,API 选择失败通常涉及使用不正确的 API,甚至产生幻觉的不存在的 API 名称。 为了定量地了解 API 选择的内在能力,将开源 LLM 与 GPT-4 进行比较,但在推理过程中不提供任何文档或上下文演示。 如图所示的天气查询工具 OpenWeather 的结果表明,GPT-4 可以选择正确的 API,无需超出目标的额外信息,而开源模型则陷入困境。 这种能力差异导致封闭式LLM可能会在训练期间内化 API 使用知识。
动作生成器选择适当的 API 后,接下来的挑战在于解析目标描述并填充 API 参数。 在此阶段,开源模型经常为所需的 API 参数提供错误的值。 如表所示,参数的混乱导致了开源模型中高达 63% 的失败。
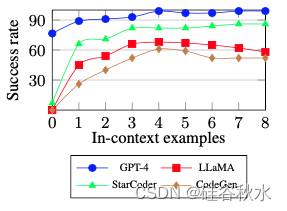
为了缓解这个问题,为LLM提供了精心挑选的预言上下文演示,该演示实现了有不同参数值的相同目标。 在上图中显示,精心挑选的预言示例将成功率提高了高达 45%。 值得注意的是,预言示例并不是为了解决引起混乱的参数,因为它们是根据每个测试用例精心挑选的。 尽管如此,这些观察结果表明,上下文演示可以极大地增强LLM的工具操作能力。
开源LLM的第三个常见失败是不可执行的生成。 此类失败包括 API 调用的语言冗长以及遵守基于自然语言的准则等问题,如上上表所示。开源模型有时在 100 个天气查询案例中,有 23% 会出现此类错误。 这些观察结果强调了监管开源LLM以专门生成代码的必要性。
通过使用示例调整LLM,模型对齐在提高LLM的指令跟随和对话等能力方面发挥着至关重要的作用[14,19,28]。模型与 API 使用示例需要保持一致,提高 API 选择能力的潜力。 为了实际利用这种对齐方式进行工具操作,需要一种数据管理策略,而无需大量手动编写示例。 为此,设计了一种方法原型,该方法可以从人工选取模板来生成使用示例。
如图描述了生成对齐数据的流程。 创建了一些模板,其中包含目标描述和相应的 API 调用。 这些模板包含一对或多对占位符(placeholder)。 每对都映射到目标中的关键字和相应 API 调用中的参数。 还为每个关键字提供候选值池,并随机选择值来填充模板内的占位符。 给定一个具有 n 个候选 API 的工具,只需要 O(n) 个人工选取的模板来确保实际的人工监督。 具体来说,采用一项原则,即鼓励 n 个 API 中的每一个都出现在至少一个模板中。 在实践中,一名开发人员平均需要一天时间才能在基准测试中整理一种软件工具的数据; 这包括编写目标模板、提供参数值池并生成数据。 带着为所有工具整理的数据,对所有工具联合执行模型对齐微调,可生成单个模型。

前面精心挑选的预言示例在改善参数填充方面的功效。 然而,从预言延伸到实际的上下文演示面临两个挑战。 首先,给定 n 个候选 API 函数,与不同目标相关的 API 调用组合,呈指数级增长。 因此,LLM应该能够基于有限数量的例子推广到各种各样的目标。 其次,为了确保有效的演示,重要的是仅向LLM提供相关示例,而无需人工干预。
为了满足上述两个需求,用演示检索器模块增强了开源LLM。 该模块围绕一个存储库,其中每个 API 都需要仅出现在一个人工策划的演示中。 这意味着只需要 O(n) 个示例。 在这些演示示例中,检索器选择语义上与目标描述最相似的示例。
为了在实践中验证演示示例的有效性,凭经验证明,检索的演示可以提高示例存储库中未见过的API 组合目标成功率。 特别是,在家庭搜索任务上评估了这种方法,该任务公开了 15 个 API 函数,并且需要多个函数来完成每个目标。 由于只有 10 个人工策划的演示在 API 组合方面与 100 个测试用例中的任何一个都不完全匹配,检索的演示可以将开源 LLM 的成功率提高高达 79%,并使 GPT-4 近乎完美, 如图所示。这表明演示示例可以仅用大小为 O(n) 的存储库来改进针对未见目标类型的工具操作。
在LLM支持的聊天机器人中,使用系统提示是一项成熟的技术[19]。 通过结合人类与聊天机器人的对话,系统提示可以有效地控制生成响应的自然语言风格。 在工具操作的背景下,正则化开源LLM,专门生成带有系统提示的API调用,如图所示,其中黑色部分是所有任务共享的模板,红色部分是在推理过程中实例化某个目标。 系统提示首先定义了一种格式,该格式结合了目标、演示和生成的文本部分。 然后,它以自然语言提供明确的指导方针,指示LLM专门生成代码。 系统提示直接针对每个请求合并目标描述和检索的 API 函数,将人类开发工作量减少为一次性任务。

为了评估工具操作领域的开源LLM,从现有数据集和新收集的数据集中策划了一个基准套件ToolBench。 该基准测试是第一个具有用于定量评估预定义测试用例的开源测试平台,将其与最近使用封闭LLM的工具操作研究区分开来 [2, 3]。
如表所示,基准测试ToolBench由收集的 5 个任务和从现有数据集派生的 3 个任务组成,包括 VirtualHome[29, 30]、Webshop[31] 和 Tabletop[20]。 它们涵盖单步和多步操作生成,这需要选择并组合 2 到 108 个 API 函数才能实现目标。 每个任务由大约 100 个测试用例组成,包括目标描述和真实 API 调用。 还提供了有限数量的演示示例来帮助模型预测。

采用成功率作为大多数任务的主要评估指标,除了采取奖励的 WebShop 以及用可执行性和最长公共子序列 (LCS) 的 VirtualHome,其他遵循各自作者提出的原始指标。 为了便于评估,构建了一个基础设施,用于执行操作生成器生成的 API 调用并评估最终结果。 此过程可以对工具操作能力进行可靠的评估,而不会限制动作生成器以完美匹配真实的 API 调用。
为了评估挑战级别,根据 API 复杂性和高级推理的要求来检查 ToolBench 任务。 直观上,API 复杂性表明泛化到未见过的 API 组合和非默认参数值的挑战。 API 复杂性之外的挑战还涉及高级推理。
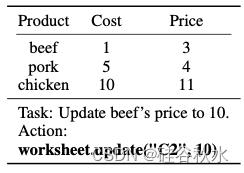
在基准测试中,高级推理除了泛化到未见过的 API 组合之外还包含挑战。 这些挑战包括针对 Google Sheets 和 Tabletop 等任务的非基于 API 编码,以及基于从 WebShop 环境返回的观察结果进行决策。 例如,在下表所示的 Google 表格示例中,牛肉价格单元格(“C2”)的坐标无法轻松地从目标或表格本身得出。 在调用 API 函数之前,动作生成器需要理解内容或编写额外的 Python 代码来导出此坐标。 在类似的场景中,WebShop 任务要求操作生成器提取准确的按钮 ID,去单击给定描述的网页。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









