









23年2月北大、北京通用AI和UCLA的论文“Describe, Explain, Plan and Select: Interactive Planning with LLMs Enables Open-World Multi-Task Agents”;
智体规划的两个主要挑战:
1)由于任务的长期性,在游戏Minecraft这样的开放世界中规划需要精确的多步骤推理;
2)由于原始规划器在一个复杂规划中对并行子目标排序时没有考虑当前智体,因此产生的规划可能效率较低。
所提出的“描述、解释、计划和选择”(DEPS),一种基于LLM的交互式规划方法。该方法有助于在长期规划过程中更好地从反馈中进行纠错,同时通过目标选择器(一个可学习的模块)接近智体;该模块根据估计的完成步骤对平行子目标进行排名,并相应地改进原规划。代码发布于https://github.com/CraftJarvis/MC-Planner。
如图所示是提出的动态规划器架构。给定任务T,“通过交互式提示,LLM描述、解释和规划”的流水线,迭代生成可执行和可解释的规划Pt。预测的选择器选择状态感知目标作为当前目标gt。
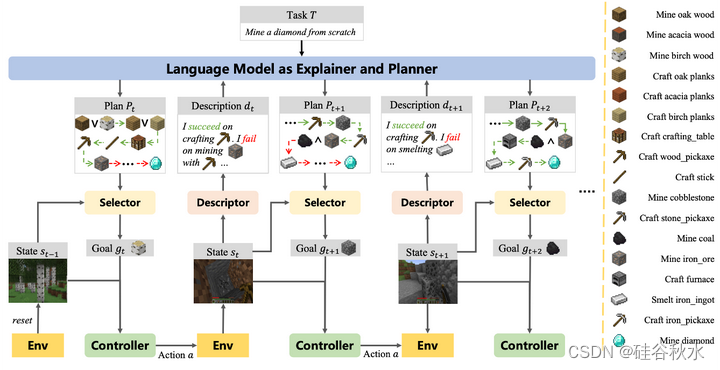
DEPS智体由事件触发描述符、LLM的解释器和规划器、基于预测的目标选择器和目标为条件的控制器组成。用LLM作为智体的零样本规划器来完成任务。给定一个指令命令(例如,ObtainDiamond)作为任务T,基于LLM的规划器将高级任务提取到子目标序列{g1,…,gK}中,作为初始规划P0。目标用自然语言进行说明。
尽管许多目标本质上是连续的,即一个目标是另一个目标完成的先决条件,但有些目标是通过AND和OR连接的。当目标之间AND在一起时,所有目标都需要完成。当目标之间OR在一起时,可以简单地选择其中任何一个来执行。
给定当前状态st,选择器被训练为预测实现一组并行目标剩余的时间步长。基于该信息,选择器选择合适的目标作为当前目标gt。最后,所选择的目标gt将由低层多任务控制器执行。控制器表示为决策的目标为条件策略π(a|s,g),将当前状态st映射到目标gt为条件的动作at。策略π可以通过强化学习或模仿学习方法进行训练。
初始规划P0很难一次成功执行,因为它经常包含错误。当失败出现时,Descriptor会将当前状态st和最近目标的执行结果汇总为文本dt,并将其发送给LLM。LLM首先尝试通过自我解释来定位先前规划Pt−1中的错误,然后它将重新规划当前任务T,并根据解释生成修改后的规划Pt。
在此过程中,LLM除了扮演规划器角色外,还被视为解释者。这种单样本规划方法对带许多子目标的长期任务往往失败,解决的方法是“描述、解释和规划”,一种交互式规划方法,可以生成更多可执行和可解释的规划。
首先将提示重写为交互式对话格式,如ChatGPT,将后续反馈传递给LLM。制定的规划附加每个目标的前提条件和效果。结构化的提示提高了规划的可读性和可解释性,并便于以后失败时进行错误定位。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









