










LeRobot 的数据集系统提供了一个强大的框架,用于管理用于训练、评估和推理的机器人数据。本文介绍 LeRobot 数据集组件的架构和使用方法,重点介绍了机器人数据的存储、访问和处理方式。

。。。。。。继续。。。。。。
LeRobotDataset 是 LeRobot 框架中的核心数据集管理组件,提供用于存储、访问和处理机器人数据的标准化格式。它管理基于事件的机器人轨迹数据,并包含同步的多模态观测、动作和相关元数据。咋次详细介绍LeRobotDataset 的结构、用法和功能。
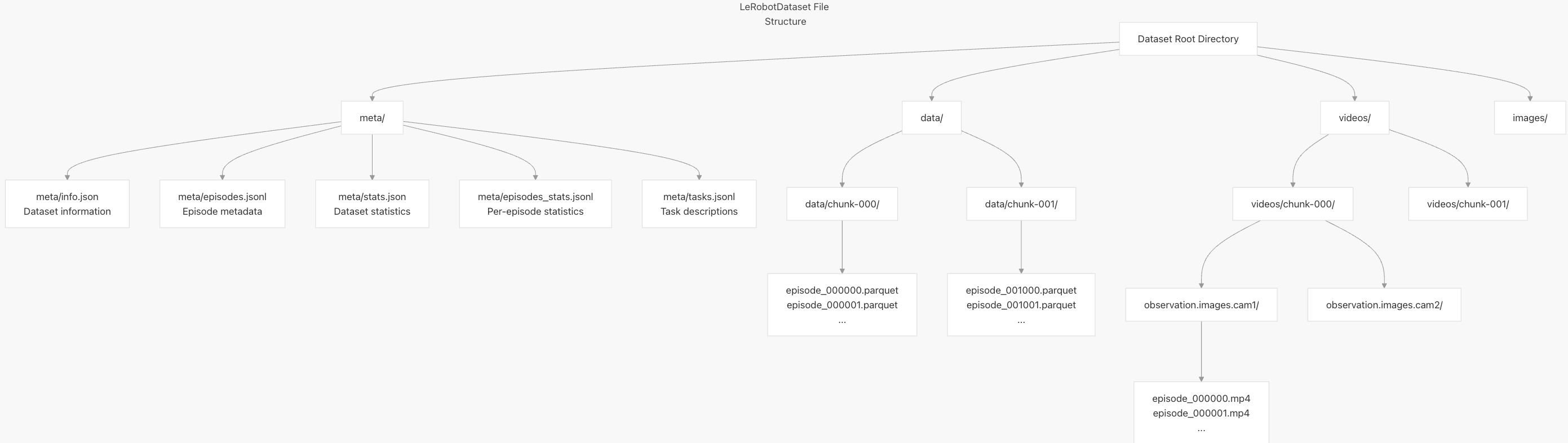
数据集结构与组织
LeRobotDataset 遵循结构化组织,将元数据、原始数据和视觉模态分开:

数据集结构旨在支持:
分块组织:剧集被分组为多个块(默认每个块 1000 episode),以便于下载和处理。
分离的元数据:元数据以 JSON 和 JSONL 文件形式存储,方便查阅。
模块化存储:不同数据类型(Parquet 格式用于状态数据,MP4 格式用于视频)分别存储。
层级组织:文件按 episode 索引和摄像机密钥组织,方便访问。
关键文件包括:
核心组件
数据集系统主要包含两个类:LeRobotDatasetMetadata 和 LeRobotDataset
LeRobotDatasetMetadata
LeRobotDatasetMetadata 负责加载和管理数据集的元数据,包括:
- 数据集信息(特征、形状、总集数/帧数等)
- episode 信息(长度、任务)
- 用于规范化的统计数据 任务及其索引
LeRobotDatasetMetadata 的主要属性:
- features:特征字典,包含其数据类型、形状和名称
- camera_keys:视觉模态的键列表
- video_keys:视频模态的键列表
- image_keys:图像模态的键列表
- tasks:将任务索引映射到任务描述的字典
- episodes:episode 元数据字典
- stats:数据集统计数据字典
LeRobotDataset
LeRobotDataset 是一个 PyTorch 数据集,可用于访问实际数据。它使用 LeRobotDatasetMetadata 来理解数据集结构,并从 Parquet 文件和视频文件中加载相应的数据。
主要功能:
- 子类 torch.utils.data.Dataset,以便与 PyTorch 无缝集成
- 通过 getitem 提供对帧的随机访问
- 处理来自不同模态的数据加载和同步
- 支持使用 delta 时间戳访问过去和未来的帧
数据集创建与加载
加载现有数据集
要从 Hugging Face Hub 加载现有数据集,请执行以下操作:
Load the entire dataset
dataset = LeRobotDataset(“lerobot/aloha_mobile_cabinet”)
Load a subset of episodes
dataset = LeRobotDataset(“lerobot/aloha_mobile_cabinet”, episodes=[0, 10, 20])
View metadata only (without downloading data)
metadata = LeRobotDatasetMetadata(“lerobot/aloha_mobile_cabinet”)
创建新数据集
可以使用 LeRobotDatasetMetadata 的 create 类方法创建新数据集:
Create a new dataset metadata
metadata = LeRobotDatasetMetadata.create(
repo_id=“username/new_dataset”,
fps=30,
robot=robot_instance, # Or provide features directly
use_videos=True
)
Create a dataset instance
dataset = LeRobotDataset(“username/new_dataset”)
Create an episode buffer for adding frames
episode_buffer = dataset.create_episode_buffer()
数据访问和处理流程
下图展示 LeRobotDataset 如何访问和处理数据:
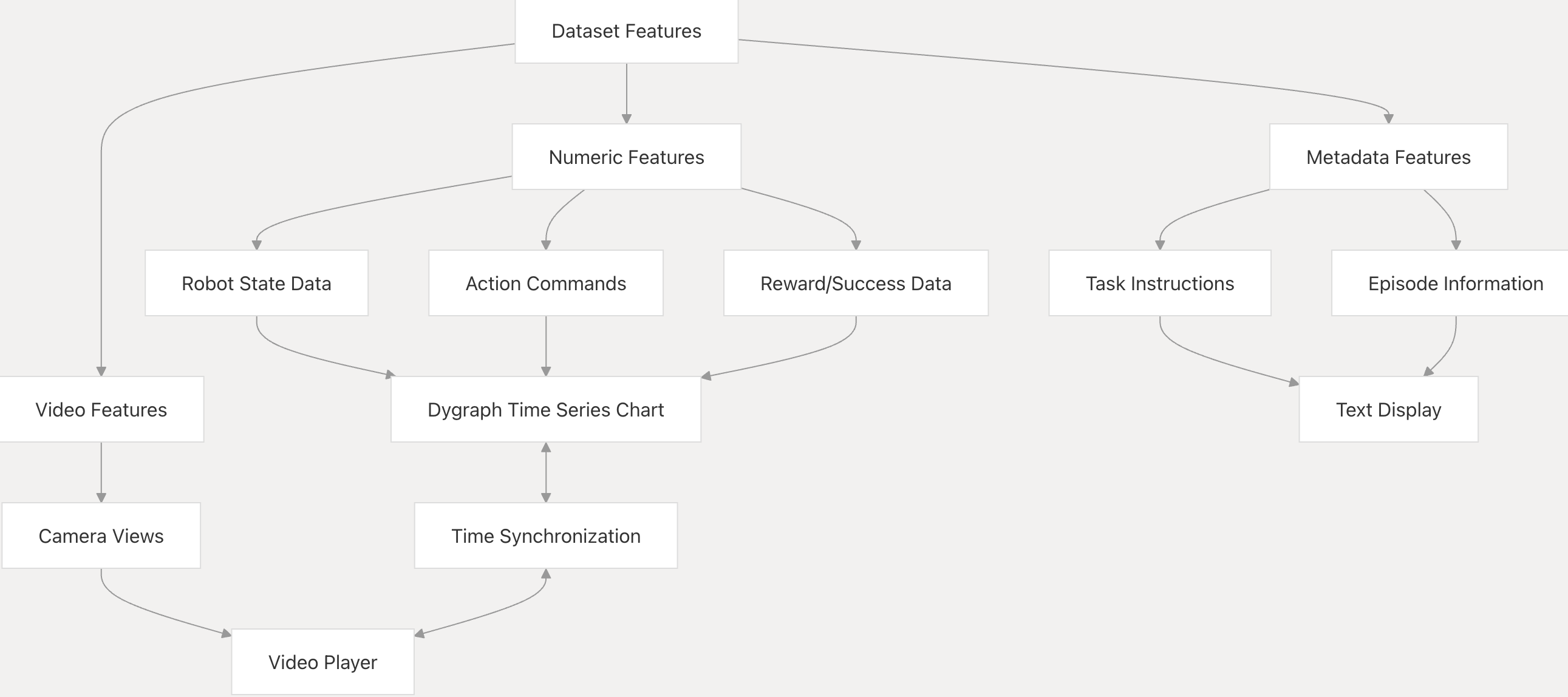
高级功能
历史和未来数据的 delta 时间戳
LeRobotDataset 最强大的功能之一是能够使用 delta 时间戳加载具有指定时间偏移的帧序列:
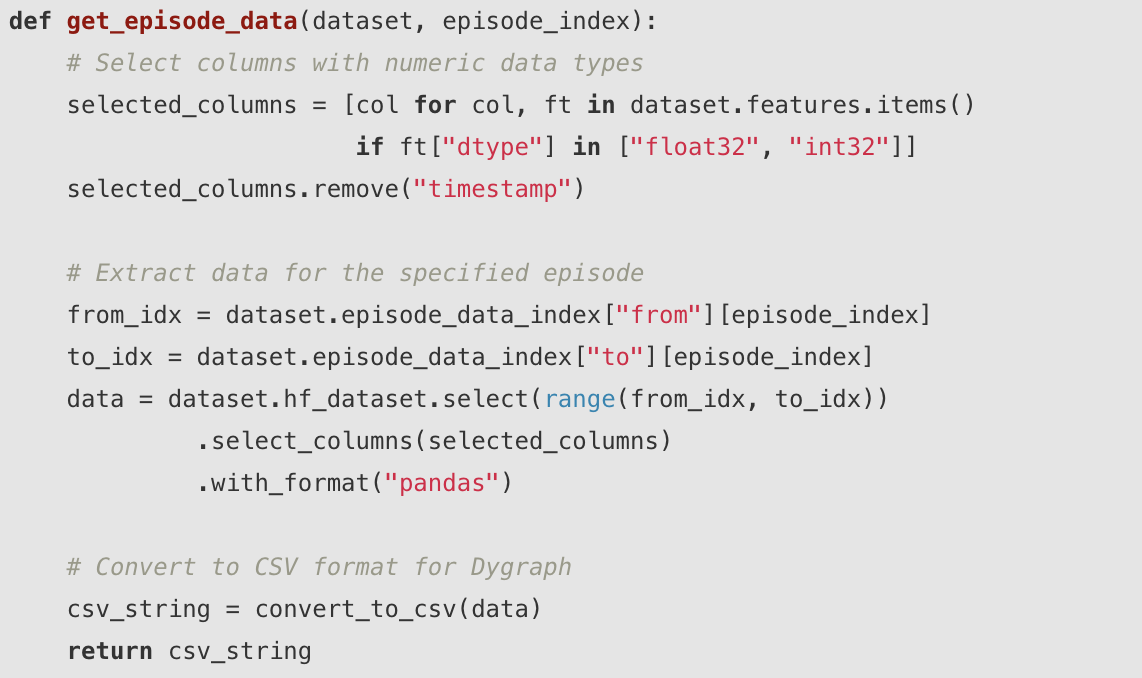
初始化数据集时,可以指定 delta 时间戳来加载每种模态的帧序列:
delta_timestamps = {
“observation.images.front”: [-1.0, -0.5, -0.2, 0], # 1s before, 0.5s before, 0.2s before, current
“observation.state”: [-1.5, -1.0, -0.5, -0.2, -0.1, 0], # Historical states
“action”: [t/30for t inrange(64)], # Current and future actions (30 FPS, 64 frames)
}
dataset = LeRobotDataset(“lerobot/dataset”, delta_timestamps=delta_timestamps)
batch = dataset[0]
print(batch[“observation.images.front”].shape) # (4, channels, height, width)
print(batch[“observation.state”].shape) # (6, state_dim)
print(batch[“action”].shape) # (64, action_dim)
根据数据集的 FPS,delta 时间戳会转换为索引,并在这些索引处查询数据。数据集会通过适当的填充来确保查询不会跨越 episode 边界。
与 PyTorch DataLoader 集成
LeRobotDataset 可以与 PyTorch 的 DataLoader 配合使用,进行批处理:
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=32,
num_workers=4,
shuffle=True,
)
for batch in dataloader:
Process batch
images = batch[“observation.images.front”] # Shape: (batch_size, seq_len, channels, height, width)
states = batch[“observation.state”] # Shape: (batch_size, seq_len, state_dim)
actions = batch[“action”] # Shape: (batch_size, seq_len, action_dim)
Hugging Face Hub 集成
LeRobot Dataset 与 Hugging Face Hub 无缝集成,实现数据集共享:
Push dataset to the Hubdataset.
push_to_hub(
branch=“main”,
tags=[“robot-type”, “task-type”],
license=“apache-2.0”,
push_videos=True,
private=False
)
该系统支持版本控制,允许数据集在保持向后兼容性的同时不断发展。数据集结构设计支持部分下载(例如,仅下载特定 episode 或排除视频)。
数据集特征和统计信息
每个数据集都包含具有指定数据类型、形状和维度名称的特征。特征分为:
- 状态特征:表示机器人状态的数值数据(关节位置、速度等)
- 视觉特征:来自摄像头的图像或视频
- 动作特征:发送给机器人的控制信号
- 元数据特征:时间戳、事件索引等。
数据集还存储每个特征的统计信息(平均值、标准差、最小值、最大值),可用于训练期间的归一化。
数据集演进与兼容性
LeRobotDataset 支持版本控制系统,用于管理数据集格式的演进并保持兼容性:
- 数据集使用代码库版本标记(例如,“v2.0”、“v2.1”)。
- 向后兼容性检查确保较新的代码可以加载较旧的数据集。
- 向前兼容性检查可防止加载较新格式的数据集。
- 转换实用程序可帮助在不同版本之间迁移数据集。
- 系统使用语义版本控制来指示重大更改(主版)、功能添加(次版)和错误修复(补丁版)。
使用示例
基本用法
Load an existing dataset
dataset = LeRobotDataset(“lerobot/aloha_mobile_cabinet”)
Access metadata
print(f"Total episodes: {dataset.meta.total_episodes}“)
print(f"Features: {dataset.meta.features}”)
print(f"Camera keys: {dataset.meta.camera_keys}")
Access a specific frame
frame = dataset[0]
print(f"Frame keys: {frame.keys()}")
Access frames from a specific episode
episode_index = 0
from_idx = dataset.episode_data_index[“from”][episode_index].item()
to_idx = dataset.episode_data_index[“to”][episode_index].item()
frames = [dataset[idx] for idx inrange(from_idx, to_idx)]
Delta 时间戳的高级用法
Define delta timestamps for each modality
delta_timestamps = {
“observation.images.front”: [-0.5, -0.25, 0], # 0.5s before, 0.25s before, current
“observation.state”: [-0.3, -0.2, -0.1, 0], # Historical states
“action”: [0, 0.033, 0.067, 0.1], # Current and future actions
}
Load dataset with delta timestamps
dataset = LeRobotDataset(“lerobot/aloha_mobile_cabinet”, delta_timestamps=delta_timestamps)
Access data with sequences
batch = dataset[0]
images = batch[“observation.images.front”] # Shape: (3, channels, height, width)
states = batch[“observation.state”] # Shape: (4, state_dim)
actions = batch[“action”] # Shape: (4, action_dim)
小节
LeRobotDataset 提供了一个全面的系统,用于以标准化、高效的格式处理机器人数据。主要功能包括:
- 结构化组织:元数据、数据和媒体文件的清晰划分
- 多模态支持:支持处理数值数据、图像和视频
- 时间同步:确保所有模态均正确同步
- 序列加载:使用增量时间戳访问过去和未来的帧
- PyTorch 集成:与 PyTorch 的 DataLoader 无缝集成
- Hub 集成:可轻松从 Hugging Face Hub 共享和下载
- 版本控制:通过兼容性检查支持数据集的演变
这些功能使 LeRobotDataset 成为机器人学习研究的重要组成部分,实现了高效的数据管理和标准化的数据集共享。
最好简介一下 LeRobot 的视频处理系统,其提供了一种高效灵活的视觉数据存储和访问方式。通过优化的视频编解码技术,该系统显著降低了存储需求,同时保持了机器人应用所必需的高质量视觉数据和快速随机访问能力。
LeRobot 中的视频使用 FFmpeg 的 encode_video_frames 函数进行编码。基于大量的基准测试,默认编码参数已针对文件大小、解码速度和视觉质量进行了优化。
系统通过统一接口支持多种解码后端:主要的解码函数是 decoder_video_frames。该函数提供了一个统一的接口,用于使用不同的后端解码特定时间戳的视频帧:
torchcodec - 可用时优先使用,性能最佳
pyav - torchcodec 不可用时的默认回退方案
video_reader - 备用后端,需要自定义 torchvision 构建
系统会自动选择最优的可用后端,但也允许通过 LeRobotDataset 中的 video_backend 参数手动选择。

















 1172
1172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









