









23年12月来自Nvidia、多伦多大学、Vector Inst和Simon Fraser大学的论文“Trajeglish: Learning The Language Of Driving Scenarios“。
自动驾驶开发的一个挑战是模拟记录动态驾驶场景。本文应用离散序列建模工具来建模车辆、行人和自行车在驾驶场景中的互动方式。用一个简单的数据驱动token化方案,可以通过一个小词汇将轨迹离散到厘米级的分辨率。然后,用类似GPT的编码器-解码器对多智体运动tokens序列进行建模,其在时间上是自回归的,并考虑了智体之间时间步内交互。从模型中采样的场景展现了现实感;在Waymo Sim Agents基准测试中名列前茅,在真实感综合指标和交互指标方面分别超过之前工作3.3%和9.9%。
如图所示是模型输入和输出,在给定的时间步长,模型预测定义的固定V状态集上分布,相对于智体当前位置和航向、地图信息上的条件、所有先前时间步的动作(绿色)以及其他智体在当前时间步内已经选择的任何动作(蓝色)。对驾驶场景相关的所有智体运动进行建模,包括车辆、行人和自行车。

在测试时,模型作为一个策略,在智体每个时间步可能到达的一组可能状态,输出分类分布。从模型中反复采样动作会导致任意长度、多样、场景一致的多智体轨迹。称该方法为“Trajeglish”,因为是将多智体轨迹建模为一系列离散的token,类似于语言建模的表示,类比于道路参与者如何使用车辆运动进行交流,以及人们如何使用语言(如英语)进行交流。
模型中选择的样本如图所示:每行中的轨迹显示都有相同的单时间步长初始化,用黑色表示;随时间的推移,未来的轨迹会变得更亮;虽然图中有些轨迹重叠,但考虑到时间的话,其实它们并不重叠;在这些轨迹中没有冲突。当生成这些样本时,只提示模型智体的初始位置和航向,而之前的工作通常需要至少一秒的历史运动才能开始采样。模型为每个场景生成不同的结果,同时保持轨迹的场景一致性。

给出了一个具有N个智体的初始场景,其中场景由地图信息、每个智体的维度和目标类、以及过去一些时间步长内每个智体的位置和航向组成。为了方便起见,用c表示初始化时提供的场景信息。用s=(x,y,h)表示车辆i在未来时间步长t的状态,其中(x,y)是智体的边框中心,h是航向。对一个场景来说,感兴趣的交通建模分布定义为
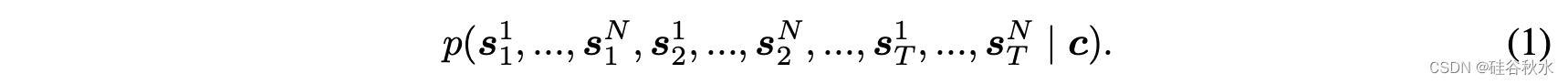
将此分布的采样示例称为展开(rollouts)。在交通建模中,目标是在每个时间步长,黑盒子自动驾驶车(AV)系统为智体的子集选择一个状态,在此限制下对展开进行采样。交通模型控制的智体,称为“非玩家角色”或NPC。交互模型得到以下公式(1)描述的联合似然分布分解:
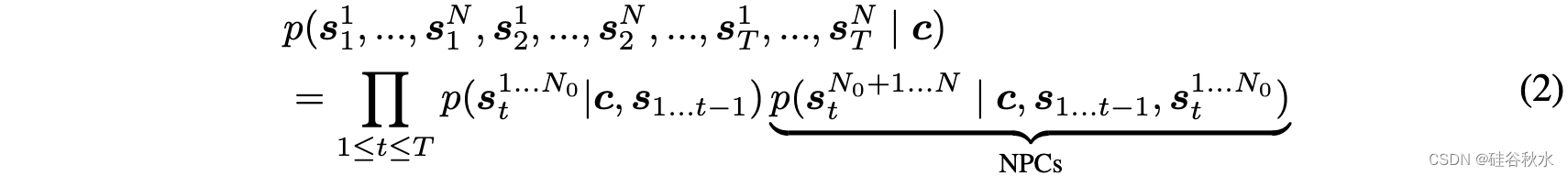
公式(2)表明,寻求一个模型,从中对智体的下一个状态进行采样,条件是在以前时间步中采样的所有状态以及在当前时间步长中已经采样的任何状态。
尽管生成驾驶数据的真实世界系统涉及独立参与者,但对其他参与者在同一时间步行动影响进行建模来说,可能仍然很重要。虽然智体之间的时间步内交互通常较弱,但显式建模这种交互提供了一个窗口去了解在建模时需要考虑的重要情况。
Trajeglish的重要特征包括,为动态测试时间交互保留了全似然的动态分解,它考虑了智体之间时间步内的耦合关系,并且它能够有效地对场景进行采样和密度估计。虽然采样是交通建模的主要目标,但Trajeglish的密度估计有助于理解较长上下文长度和时间步相互关系的重要性。
Token化的目标是将连续分布的支持建模为一组|V|离散选项。给定x~p(x),token化器是将连续分布的样本映射到离散项的一个f。一个渲染器是将离散项映射回原始输入r。一个高质量的token化器-渲染器对是这样的,即r(f(x))≈x。在交通建模的情况下,试图token化的连续分布由公式(1)给出。这些分布是在仅由位置和航向组成的单智体状态上。考虑到输入数据的低维性,提出一种简单的方法,用于基于一组固定的状态-到-状态转换来token化轨迹。
设s0是在当前时间步长具有长度l和宽度w的智体状态。s为寻求token化的下一个时间步状态,将V={si}定义为一组模板动作,每个动作表示最近状态坐标系中位置和航向的变化。用符号ai来表示token模板si的索引表示,并用s^来表示token化状态s的原始表示。
Token化器和渲染器定义如下:

其中d(s0,s1)是由s0和s1定义的边框有序角点之间L2距离的平均值,“local”将s转换为s0的局部框,“global”将si*从s0的局部框转换到全局框。
为了token化完整的轨迹,在下一个token化步骤中,用token化状态作为基本状态s0,沿轨迹迭代地完成状态s转换为其token化表示s^的整个过程。如图可视化了token化轨迹的过程:示例轨迹显示为绿色,token化轨迹的原始表示显示为带有蓝色轮廓的方框,尚未token化的状态为浅绿色;token模板优化,是最小化token化轨迹和原始轨迹之间的误差。为了进行交通建模,生成的token具有三个方便的特性:在坐标系上具备不变,在时间偏移下具备不变,并且提供了对token之间相似性度量的有效访问,即原始表示之间的距离。

文章提出了一种易于并行化的方法来寻找具有低离散化误差的模板集。收集了大量在数据中观察到的状态转换,对其中一个进行采样,过滤ε米以内的转换,并重复|V|次。该算法的伪码包含在如下算法1中。这种对候选模板进行采样的方法称为“k-disks”,因为它与k-means++这种锚为种子的标准k-means(Arthur&Vassilvitskii,2007)算法以及泊松盘采样(disk sampling)算法(Cook,1986)相似。

如图可视化用离散化误差最小k-disk找到的模板集。
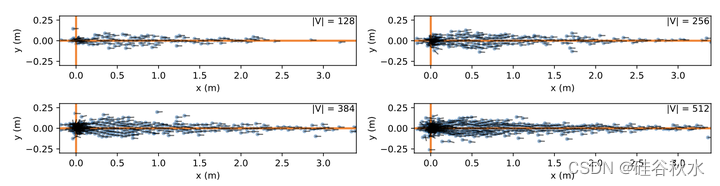
如图验证,尽管模板在训练集上进行了优化,但token化的动作分布在WOMD训练和验证是相似的。
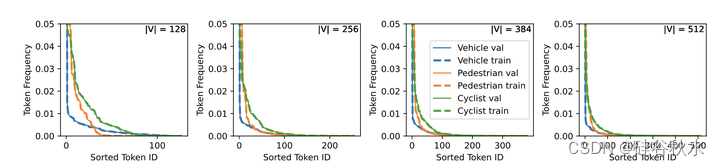
如图显示,在不同的智体类型中,用k-disk采样的模板引起的离散化误差通常比k-means好得多。

第二部分工作是,学习第一个输出token序列上分布的架构。模型遵循与LLM非常相似的编码器-解码器结构(Vaswani,2017;Radford,2019;Raffel,2019)。该模型的示意图如图所示:训练一个编码器-解码器transformer,其以先前的动作token、地图信息和t=0时可用的智体信息为条件来预测智体的动作token;该图表示训练期间网络的前向传递,其中t=0智体信息、地图目标和运动token用因果掩码传递到网络中,并且训练模型以预测下一个运动token。编码器的两个重要性质是,对全局坐标系的选择不等变,对智体次序不是置换等变。对于第一个特性,在训练期间随机化坐标系的选择是直接的,并且共享全局坐标系能够实现跨智体的共享处理和表示学习。对于第二个性质,置换等变实际上是不可取的,因为智体顺序会编码智体在时间步内选择动作的顺序;当提供了其他智体已经选择的动作时,模型预测动作的能力应该会提高。
















 1814
1814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









