










24年4月来自耶鲁大学和谷歌的论文“Prompt Cache: Modular Attention Reuse For Low-latency Inference“。
Prompt Cache是一种通过在不同的 LLM 提示中重用注意状态来加速大语言模型 (LLM) 推理的方法。许多输入提示都有重叠的文本段,例如系统消息、提示模板和为上下文提供的文档。主要见解在于,通过预先计算并将这些频繁出现的文本段注意状态存储在推理服务器上,可以在这些段出现在用户提示中时有效地重用它们。Prompt Cache 采用一种议程(schema),明确定义此类可重用的文本段,称为提示模块。该议程可确保注意状态重用期间的位置准确性,并为用户提供访问其提示中缓存状态的界面。原型实现在多个 LLM 中评估 Prompt Cache。Prompt Cache 显著降低了第一个token的延迟时间,尤其是对于较长的提示,例如基于文档的问答和推荐。改进范围从基于 GPU 推理的 8 倍到基于 CPU 推理的 60 倍,同时保持输出准确性,无需修改模型参数。
如图所示是完全自回归生成(a)、KV Cache (b)和 Prompt Cache (c)之间的区别。随着缓存段的大小增加,性能优势变得更加明显,因为注意状态的计算开销与输入序列大小成二次方关系(Keles,2022;Tay,2023),而 Prompt Cache 的空间和计算复杂度与大小成线性关系。
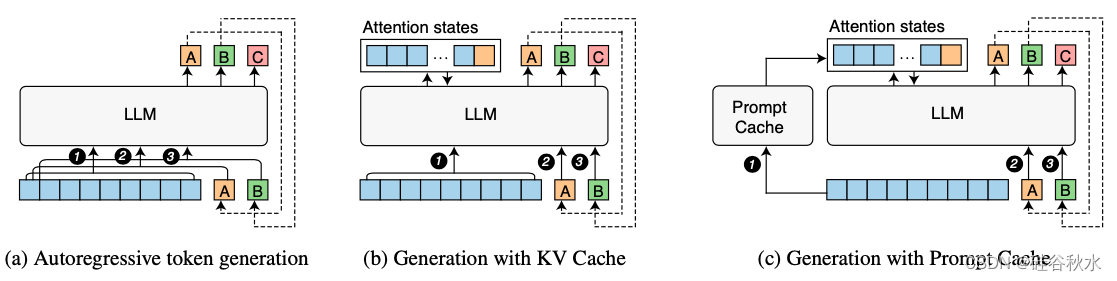
比较这三种 LLM token 生成方法,每种方法均显示三个步骤(1 到 3步)。每个框表示一个token。蓝色框代表提示。 (a) LLM 接收提示(蓝色 token)并预测下一个 token (A) 。然后将生成的 token (A) 附加到提示以预测下一个 token (B)。此过程称为自回归,将持续到满足停止条件。 (b) KV Cache 仅对提示计算一次时间注意状态,并在后续步中重复使用它们;© Prompt Cache 跨服务重用 KV 状态,绕过提示注意计算。Prompt Cache 在加载一个议程(schema)时填充其缓存,并重用从议程派生提示的缓存状态 。
跨提示重用注意状态时会出现两个挑战。首先,由于 Transformers 中的位置编码,注意状态与位置相关。因此,只有当文本段出现在相同位置时,才能重用该文本段的注意状态。其次,系统必须能够有效识别可能已缓存其注意状态以便重用的文本段。
为了解决这两个问题,Prompt Cache 结合了两个想法。第一个是使用提示标记语言 (PML) 明确提示的结构。PML 将可重用的文本段明确为模块,即提示模块。它不仅解决了上述第二个问题,而且为解决第一个问题打开了思路,因为可以为每个提示模块分配唯一的位置 ID。第二个想法是,LLM 可以对具有不连续位置 ID 的注意状态进行操作。这意味着可以提取不同部分的注意状态并将它们连接起来形成含义子集。利用这一点,使用户能够根据需要选择提示模块,甚至在运行时更新某些提示模块。
Prompt Cache 的做法是,LLM 用户用 PML 编写提示,目的是可以根据提示模块重复使用注意状态。重要的是,他们必须从议程中派生出提示,该议程也是用 PML 编写的。
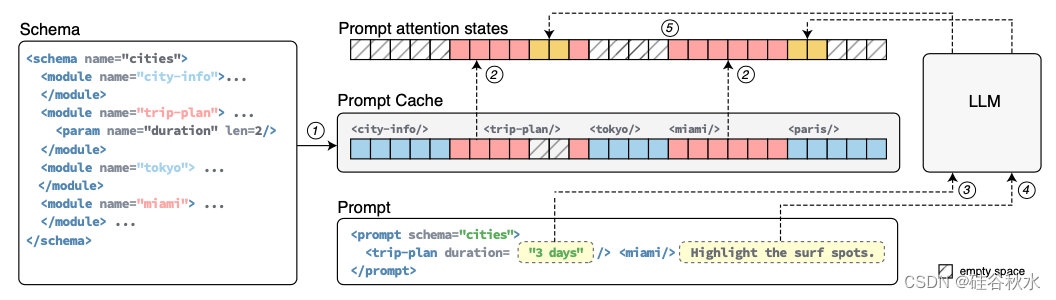
如图所示显示了基于示例议程的示例提示,可以解释 Prompt Cache 的重用机制:(i)PML 在议程和提示中都明确了可重用的提示模块;提示模块可以具有类似旅行计划的参数;导入模块的提示为一个参数(持续时间)提供了一个值(3 天)。提示可以包含在排除的模块位置上新的文本段、参数以及末尾。(ii)提示模块编码预先计算议程中所有模块的注意状态(1)并将其缓存以供将来重用。(iii)在提示时,Prompt Cache采用缓存的推理:它检索为导入提示模块缓存的注意状态(2),为参数(3)和新文本段(4)计算它们,最后将它们连接起来生成整个提示的注意状态(5)。
可以看到,当 Prompt Cache 收到提示时,它首先处理其议程并计算其提示模块的注意状态。它将这些状态重用于提示中的提示模块以及从同一议程派生的其他提示。虽然 Prompt Cache 可以与任何与 KV Cache 兼容的 Transformer 架构一起使用,实验中采用三种流行的 Transformer 架构,为以下开源 LLM 提供支持:Llama2 (Touvron,2023)、Falcon (Penedo,2023) 和 MPT (MosaicML,2023)。考虑两种用于存储提示模块的内存:CPU 和 GPU 内存。虽然 CPU 内存可以扩展到 TB 级别,但它带来了主机到设备内存复制的开销。相比之下,GPU 内存不需要处理,但容量有限。
一个议程(schema)是定义提示模块并描述其相对位置和层次结构的文档。每个议程都有一个唯一标识符(通过 name 属性),并使用 标记指定提示模块。未包含在 标记或未指定标识符中的文本,将被视为匿名提示模块,并且始终包含在从议程构建的提示中。
对于 LLM 用户,议程用作创建和重用提示模块注意状态的接口。用户可以使用 标记从一个议程构建一个提示。此标记通过 schema 属性指定要使用的议程,列出要导入的提示模块,并添加任何其他(非缓存)指令。例如,要从议程中导入模块 miami,可以将其表示为 。Prompt Cache 将仅计算议程中未指定文本的注意状态,例如突出显示冲浪点(surf spots),并重用导入模块的注意状态,例如旅行计划和 miami,从而减少延迟。
PML 允许对提示模块进行参数化,最大限度地提高重用机会。参数是一个具有指定长度的命名占位符(placeholder),可以出现在议程中提示模块的任何位置。它使用 标记定义,其中 name 和 len 属性分别指示其名称和参数的最大tokens数。当提示导入提示模块时,它可以为这个参数提供一个值。
参数化提示模块有两个重要用途。首先,一个提示模块与其他提示模块的不同之处通常只在一些明确定义的地方。参数允许用户提供特定参数以在运行时自定义模块,并且仍然可以从重用中受益。这对于模板化提示特别有用。其次,可以在架构中提示模块的开头或结尾处,一个参数可以用来创建一个“缓冲区”。此缓冲区允许用户在提示中添加任意文本段,只要该段不超过其替换的参数 token 长度即可。
为了简化 PML 编写,Prompt Cache 可以自动将提示程序(Beurer-Kellner,2023;Guidence,2023)从 Python 等语言转换为 PML,从而无需手动编写模式。这主要通过使用 Python API 实现,该 API 将 Python 函数转换为相应的 PML 模式。转换过程很简单:if 语句变成 PML 中的 构造,将条件提示封装在其中。当条件计算为真时,将激活相应的模块。“选一”语句(例如 if-else 或 switch 语句)映射到 标签。函数调用被转换成嵌套的提示模块。此外,还实现了一个装饰器(decorator)来管理参数,特别是限制最大参数长度。这对应于 中的 len 属性。这种 Python 到 PML 的编译,对用户隐藏了 PML 的复杂性,从而提高了提示的可维护性。
第一次需要提示模块的注意状态时,必须计算它们并将其存储在设备内存中,称为提示模块编码。首先,Prompt Cache 从议程中提取一个提示模块的token序列。然后,它为每个token分配位置 ID。起始位置 ID 由提示模块在架构内的绝对位置决定。例如,如果两个前提示模块的token序列大小分别为 50 和 60,则为提示模块分配起始位置 ID 110。对联合模块,存在例外。由于联合的提示模块从相同位置开始,因此它们的token序列大小将与最大子模块的大小一起考虑。
然后,根据提示模块的token序列和相应的位置 ID,将它们传递给 LLM,计算 (k, v) 注意状态。分配的位置 ID 不从零开始。这在语义上是可以接受的,因为空格不会改变预计算文本的含义。然而,许多现有的Transformer位置编码实现,例如 RoPE,通常需要进行调整以适应不连续的位置 ID。
对于编码参数化提示模块,提示中包含空格不会影响其语意。参数由预定数量的 tokens替换,相当于它们的 len 属性值。与这些 tokens 相对应的位置 ID 会被记录下来以供将来替换。当此模组整合到用户的提示中并与相关参数配对时,这些提供的参数 token 序列会采用先前与 tokens 连结的位置 ID。然后,产生的 (k, v) 注意状态将替换最初分配给 tokens 的注意状态。新提供的 tokens 长度可以小于指定的参数长度,因为尾随空格不会改变语意。
当向 Prompt Cache 提供提示时,Prompt Cache 会对其进行解析,以确保与声明的议程(schema)一致。它会验证导入模块的有效性。然后,Prompt Cache 从缓存中检索导入提示模块的 (k, v) 注意状态,计算新文本段的注意状态,并将它们连接起来,生成整个提示的注意状态,从而取代预填充操作。
用 PyTorch 中的 HuggingFace Transformers 库(Wolf,2020)构建一个 Prompt Cache 原型,包含 3K 行 Python 代码。目标是无缝集成现有的 LLM 代码库并重用其权重。Prompt Cache 用 CPU 和 GPU 内存来容纳提示模块,并在两个平台上对其进行评估。















 102
102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









