










24年7月来自UCLA的论文“MetaUrban: A Simulation Platform for Embodied AI in Urban Spaces”。
街道和广场等公共城市空间为居民提供服务,并适应各种充满活力的社会生活。机器人技术和具身智能的最新进展使公共城市空间不再是人类的专属。送餐机器人和电动轮椅已经开始与行人共享人行道,而各种各样的机器狗和人形机器人最近也出现在街道上。在城市空间的繁华街道上导航时,确保这些即将出现的移动机器通用性和安全性至关重要。这项工作 MetaUrban,是一个用于城市空间具身智能研究的组合模拟平台。MetaUrban 可以从组合元素构建无数个交互式城市场景,涵盖各种各样的平面图、目标位置、行人、弱势道路使用者和其他移动智体的外观和动态。设计点导航和社交导航任务作为使用 MetaUrban 进行具身智能研究的试点研究,并建立强化学习和模仿学习的各种基线。实验表明,模拟环境的组合特性可以显著提高经过训练的移动智体通用性和安全性。
城市公共空间的类型、形式和规模各不相同,包括街景、广场和公园。它们是交通和运输的重要空间,同时也为举办各种社会活动提供了机会。自 20 世纪初以来,城市公共空间的研究一直是城市社会学 [56, 32, 29] 和规划 [26, 78, 28] 的基石。例如,威廉·H·怀特 (William H. Whyte) 在其开创性著作《城市——重新发现中心》[79] 中指出,公共空间的复杂性和活跃的互动,深刻地决定了人类的社会生活,强调了这些环境在城市安全和活力中发挥的关键作用。
机器人技术和具身智能的最新发展,使城市空间不再是人类独有的。各种移动机器开始出现。例如,老年人和肢体残疾人在街上操纵电子轮椅,而送餐机器人在人行道上导航以完成最后一英里的送餐任务。各种移动腿式机器人也即将问世,例如波士顿动力公司的机器狗 Spot 和特斯拉的人形机器人 Optimus。因此可以想象,未来的公共城市空间将由人类和由具身智能驱动的移动机器共享和共同居住。确保这些移动机器的通用性和安全性至关重要。
模拟平台 [35、67、70、41、73、13、18、38、44、19] 在实现具身智能智体的系统性和可扩展性训练以及在实际部署之前的安全评估方面发挥了关键作用。然而,大多数现有的模拟器要么侧重于室内家庭环境 [61、35、67、70、41、24],要么侧重于户外驾驶环境 [38、44、19]。例如,AI2-THOR [35]、Habitat [67] 和 iGibson [70] 等平台专为家庭助理机器人设计,其环境主要是带有家具和家电的公寓或房屋;SUMO [38]、CARLA [19] 和 MetaDrive [44] 等平台则专为自动驾驶和交通研究而设计。然而,对具有多样化布局和目标以及复杂行人动态的城市空间的模拟探索却很少。
与室内家庭和驾驶环境不同,城市空间具有独特的特征。最后一英里送货机器人,它的目标是将午餐订单从附近的比萨店送到校园。首先,它面临着一英里距离的几个街区长途旅程,道路危险多种多样,例如人行道上的树根造成的破碎路缘和凹凸不平地面。然后,它必须安全地穿越满是垃圾桶、停放的摩托车和盆栽等障碍物的杂乱街道。此外,它需要妥善处理行人和人群以避免碰撞。它还应该特别照顾坐在轮椅上的残疾人。因此,布局多样性、目标分布和动态复杂性,给模拟环境的设计和在城市空间中运行的具身智体的通用性和安全性的研究,带来了挑战。
MetaUrban 就是一个用于城市空间具身智能研究的组合模拟平台。如图所示:(上)人类和移动机器开始共享公共城市空间。(下)MetaUrban 模拟器通过构建具有不同街区、目标、以及行人、弱势道路使用者和其他智体运动的交互式城市环境,促进城市环境中的具身智能研究。

从规模、传感器和特征维度对 MetaUrban 与其他模拟器进行比较。就规模而言,MetaUrban 可以使用程序生成流水线生成无限场景。它还提供所有模拟环境中最多的人类数量(1,100)和动作数量(2,314)。就传感器而言,MetaUrban 提供 RGBD、语义和激光雷达,而声学是更好地支持多模型任务的举措。就特征而言,与其他模拟器不同,MetaUrban 提供目标类别的真实世界分布,并使用更复杂的路径规划算法来获得自然的人类轨迹。它还提供灵活的用户界面——鼠标、键盘和操纵杆以及赛车方向盘,极大地简化人类专家演示数据的收集。MetaUrban 使用开源的 PyBullet 作为其物理引擎,其在物理模拟方面具有很高的准确性,为未来的发展提供了经济高效且灵活的解决方案。 MetaUrban 使用 Panda3D [27] 进行渲染,这是一款轻量级的开源游戏引擎,无缝集成 Python,提供灵活且易于访问的开发环境。
总之,最近的模拟平台都没有为城市空间构建,并且所提出的模拟器在多样化的布局、目标、人体动态以及不同类型的移动智体(如送货机器人、电动轮椅、机器狗、人形机器人和车辆)及其复杂的交互方面与它们有显著不同。
MetaUrban 是一个组合式模拟平台,可以为城市空间中的具身智能生成无限的训练和评估环境。如图描述了程序生成流程。MetaUrban 使用结构化描述脚本来创建城市场景。根据提供的街区、人行道、目标、智体等信息,它从街区地图开始,然后通过划分不同的功能区来规划地面布局,然后放置静态目标,最后填充动态智体。
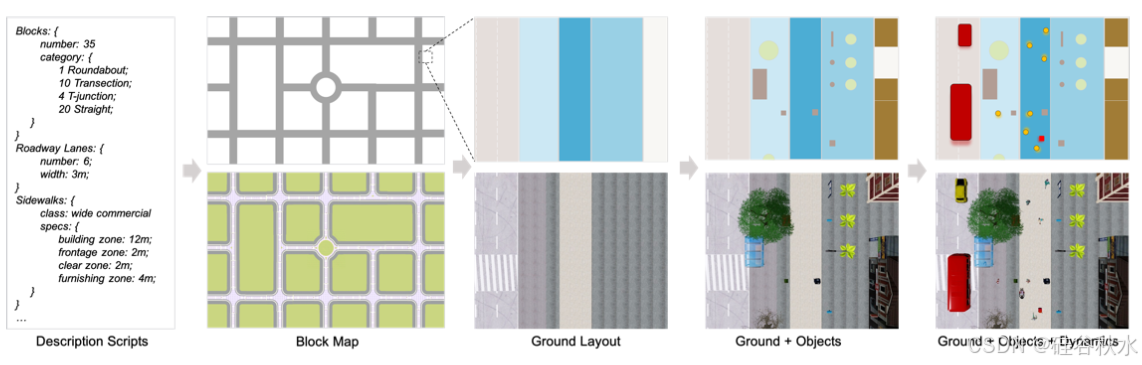
场景布局的多样性,即街区的连接和类别、人行道和人行横道的规格以及目标的放置,对于增强已训练的智体在公共空间中行进的通用性至关重要。在分层布局生成框架中,首先对街区类别进行采样,划分人行道和人行横道,然后分配各种目标,这样就可以得到具有任意大小和地图规格的无限城市场景布局。
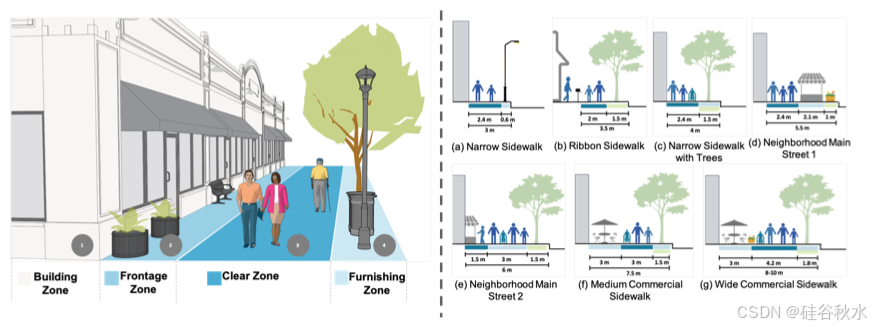
如图是地面规划。(左)人行道分为四个功能区——建筑区、临街区、空地区和装饰区。(右)七种典型的人行道模板——从(a)到(g)。
确定地面布局后,可以在地面上放置目标。目标分为三类。1)标准基础设施,如电线杆、树木和标志,定期沿道路放置。2)非标准基础设施,如建筑物、盆景和垃圾箱,随机放置在指定的功能区。3)杂物,如饮料罐、袋子和自行车,随机放置在所有功能区。可以通过指定目标池来获得不同的街道风格,同时通过指定密度参数来获得不同的紧凑度。如图显示了使用采样的路面规划和目标位置放置的不同目标。

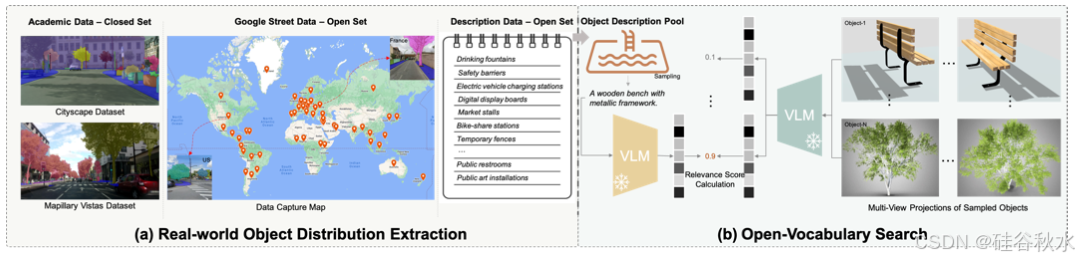
分层布局生成决定了场景的布局以及放置目标的位置。但是,为了让经过训练的智体能够在现实世界中浏览由各种目标组成的场景时具有通用性,放置哪些目标是另一个关键问题。可扩展资产检索流水线,首先从网络数据中获取现实世界的目标分布,然后通过基于 VLM 的开放词汇搜索模式从 3D 资产存储库中检索目标。此流水线灵活且可扩展:随着继续利用更多网络数据进行场景描述并将更多 3D 资产作为候选目标,检索的目标可以缩放到任意大小。如图所示:
同居填充(Cohabitant Populating)技术。遵循 BEDLAM [6] 和 AGORA [57],将人类表示为参数人体模型 SMPL-X [58],其中 3D 人体分别由一组姿势 θ、形状 β 和面部表情 φ 参数控制。然后,基于 SynBody [81] 的资产库,通过从 68 件服装、32 根头发、13 根胡须、46 个配饰和 1,038 种布料和皮肤纹理中采样,程序生成 1,100 个 3D 装配人体模型。为了形成安全关键场景,还包括弱势道路使用者,如骑自行车的人、滑板手和踏板车骑手。对于其他智体,整合 COCO Robotics 和 Starship 的送货机器人、Drive Medical 的电动轮椅、Boston Dynamic 的机器狗和 Agility Robotics 人形机器人的 3D 资产。
在模拟器中提供两种人体运动——日常运动和独特运动。日常运动提供日常生活中的基本人体动态,即闲置、行走和跑步。独特运动是在公共场所随机出现的复杂动态,例如跳舞和锻炼。利用 BEDLAM 数据集 [6] 获得 2,311 个独特运动。对于具有日常运动的人类和其他智体,用 ORCA [77] 社会力模型和推-转 (P&R) 算法 [11] 模拟他们的轨迹。ORCA [77] 使用联合优化和集中控制器来保证智体不会相互碰撞或与任何其他被识别为障碍物的目标发生碰撞。推-转 (P&R) [11] 是一种多智体路径搜索算法,可通过局部协调解决任何潜在死锁。未来一个有趣的方向是赋予人类职业、性格和目标等个人特征,并利用 LLM [1] 和 LVM [45] 的优势,实现人类在城市场景中的社交 [62] 和交互行为 [55]。
基于 MetaUrban 模拟器,构建 MetaUrban-12K 数据集,其中包括 12,800 个用于训练的交互式城市场景(MetaUrban-train)和 1,000 个用于测试的场景(MetaUrban-test)。对于训练集和测试集,从 6 个具有相同目标和动态分布的人行道模板中随机抽样。进一步构建一个包含 100 个场景的未见过测试集(MetaUrban-unseen)用于零样本实验,其中从未见过模板中抽样 - 宽阔的商业人行道、未见目标、智体的轨迹,并根据真实场景由设计者进一步手动调整。此外,为了实现微调实验,构建一个与 MetaUrban-unseen 分布相同 1,000 个场景的训练集,称为 MetaUrban-finetune。在本地工作站上,12 小时即可生成 12K 场景。值得注意的是,MetaUrban 平台可以轻松将城市场景的规模从多街区级别扩展到整个城市级别。为了实现离线 RL 和 IL 训练,从训练有素的 RL 智体和人类操作员那里收集专家演示数据,形成 30,000 步高质量演示数据。演示数据的成功率为 60%,可作为离线 RL 和 IL 实验的参考。
如图是动态场景的模拟示例:


















 1147
1147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









