










24年3月来自北大等机构的论文“Harder Tasks Need More Experts: Dynamic Routing in MoE Models”。
混合专家 (MoE) 模型的动态专家选择框架,旨在通过根据输入难度调整激活专家的数量来提高计算效率和模型性能。与传统的 MoE 方法不同,传统方法依赖于固定的 Top-K 路由,无论输入的复杂性如何,都会激活预定数量的专家,而动态路由方法则根据每个输入的专家选择置信度动态选择专家。这可以更有效地利用计算资源,为需要高级推理的复杂任务激活更多专家,为简单任务激活更少专家。该模型将更多专家分派到需要复杂推理技能的任务,如 BBH(Big Bench),证实了它能够根据输入的复杂性动态分配计算资源。特别是Transformer 模型不同层所需专家数量的变化。
代码和模型开源 GitHub - ZhenweiAn/Dynamic_MoE
具体来说,首先计算选择专家的概率分布。如果某个专家的最高概率超过预定义的阈值 p,则表明置信度较高,只激活该专家。否则,逐步增加其他专家,直到选定专家的累积概率超过阈值 p。这种方法允许动态选择专家,专家数量根据输入的复杂性进行调整。
如图所示:Top-K路由机制与Top-P路由机制比较。(a)每个token以Top-K路由概率选择固定的K=2个专家。(b)在Top-P路由机制中,每个token选择路由概率较高的专家,直到累积概率超过阈值。
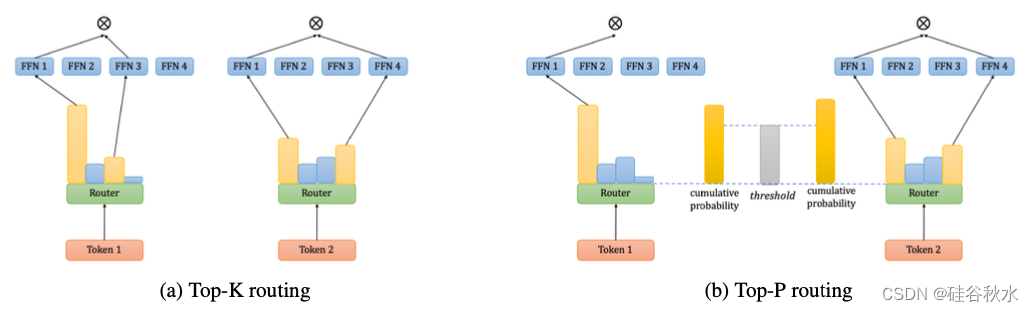
具体而言,专家选择的概率 P 反映了输入token x 在选择不同专家时的置信度。换句话说,Pi 表示模型对第 i 个专家能够充分处理输入 x 的信心度。如果 P 中的最高概率足够大,那么可能只需要使用相应的专家。但是,如果最高概率不够大,需要添加更多专家来提高处理 x 的可靠性。不断添加专家,直到所选专家的概率总和超过特定阈值 p,此时模型足够自信,这些专家可以有效地处理输入 x。按 P 中概率的降序添加新专家,尽可能减少激活专家的数量。正式地,首先将 P 中的元素从高到低排序,得到一个排序索引列表 I。然后找到累积概率超过阈值 p 的最小专家集。
动态路由机制存在一个风险:它可能会为所有专家分配较低的置信度,从而激活更多专家以实现更好的性能。假设 P 是一个均匀分布,将超参数 p 设置为 0.5,那么模型将激活多达一半的专家。这违背了 MoE 框架的初衷:高效地扩展模型。
为了防止动态路由用过多的参数作弊并失去选择性选择专家的能力,对 P 引入了一个约束。希望路由机制选择一小组必要的专家,因此,目标是最小化分布 P 熵,确保每个 token 都能关注尽可能不具体的专家。动态损失旨在鼓励路由机制选择最小的必要专家集。
由于其他专家未得到充分利用,从而影响训练效率,因此通常希望不同专家处理的 tokens 数量大致相同。此外,先前的研究(Zuo,2022)表明,MoE 层中均匀地激活专家可以带来更好的性能。为了实现不同专家之间的平衡负载,加入负载平衡损失(Lepikhin,2021;Fedus,2022)。
该模型是一个生成模型,生成的下一个token作为训练目标。最终损失是语言模型损失、动态损失和负载平衡损失的组合。
用 RedPajama(Computer,2023)作为训练数据,它是 LLaMa 数据集的全开源实现。RedPajama 数据来自多种来源,包括常见爬虫 (CC)、C4、github、维基百科、书籍、arxiv 和 Stackexchange。在主要实验中,用 100B 个 tokens 训练所有模型。
该模型架构遵循 LLaMA(Touvron,2023)。用 Llama2 token化器,其词汇量为 32000。除非另有明确说明,将 Transformer 层数设置为 24,隐维度设置为 1024。采用多头注意机制,总共有 16 个注意头,每个头维度为 64。在 FFN 层中使用 SwiGLU(Shazeer,2020)。对于初始化,所有可学习参数都以标准差 0.006 随机初始化。每个 MoE 层有 16 个专家,具有与标准 FFN 相同的初始化参数。在这种配置下,每个密集模型大约有 374M 个参数。每个 MoE 模型总共有 3.5B 个参数。MoE-Top 1 中仅激活 374 个参数,而 MoE-Top 2 中激活 581M 个参数。
用密集模型作为基线。在密集模型中,每个 Transformer 层由一个多头注意层和一个标准前馈网络组成。将隐维度分别设置为 1024 和 1280 来实现两个密集模型:密集(374M)和密集(570M)。
采用 Top-K 路由的 MoE 模型,其中 K 分别设定为 1 和 2。仅使用语言建模损失和负载平衡损失进行训练。MoE-Top 1 可以看作是 Switch Transformer (Fedus et al., 2022) 的重实现,而 MoE-Top 2 是 Gshard (Lepikhin et al., 2021) 的重实现。MoE-Top 1 和 MoE-Top 2 的激活参数分别与 密集(374M) 和 密集(570M) 几乎相同。
MoE-Dynamic 模型用动态自适应路由机制,根据输入的 token 表示激活不同数量的专家。路由机制中的阈值 p 为 0.4。在推理过程中,MoE-Dynamic 模型激活的专家不超过 2 名,这意味着它使用的参数比 MoE-Top 2 少。
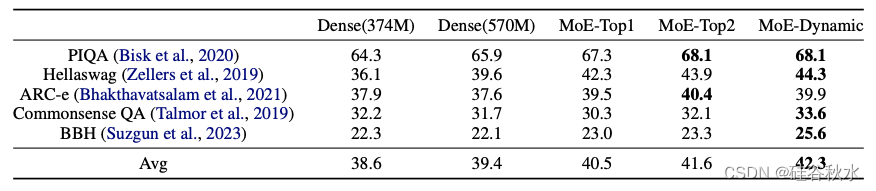
下表为实验结果:

















 7174
7174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









