










24年3月来自南京大学、中科院自动化所和复旦大学的论文“STAG4D: Spatial-Temporal Anchored Generative 4D Gaussians”。
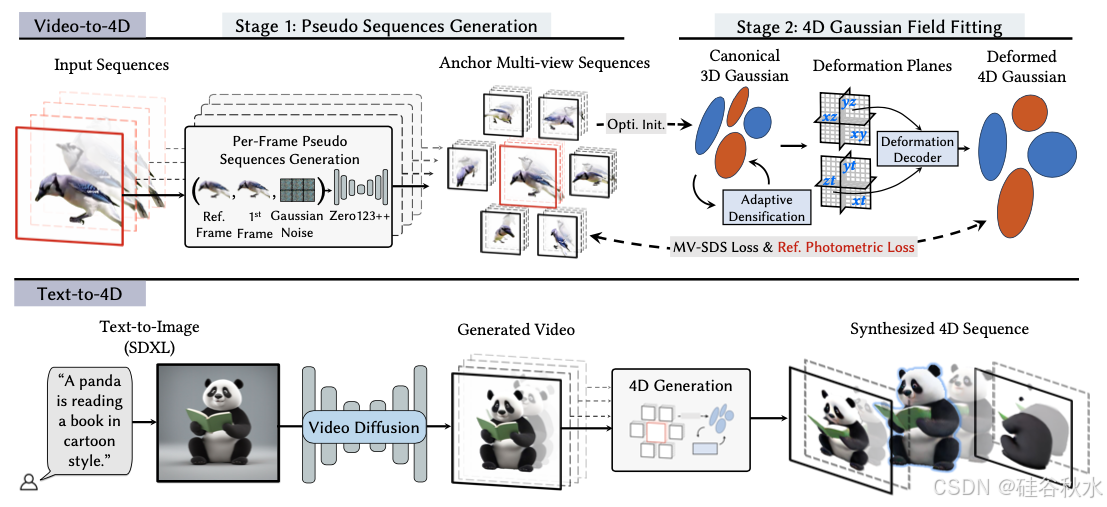
预训练扩散模型和 3D 生成的最新进展激发了人们对 4D 内容创作的兴趣。然而,实现具有时空一致性的高保真 4D 生成仍然是一个挑战。STAG4D,将预训练的扩散模型与动态 3D 高斯扩散相结合,实现高保真 4D 生成。从 3D 生成技术中汲取灵感,用多视图扩散模型来初始化锚定在输入视频帧上的多视图图像,其中视频可以是真实世界捕获的,也可以是由视频扩散模型生成的。为了确保多视图序列初始化的时间一致性,引入一种简单但有效的融合策略,利用第一帧作为自注意计算中的时间锚点。对于几乎一致的多视图序列,应用分数蒸馏采样(score distillation sampling,SDS)来优化 4D 高斯点云。 4D 高斯扩散是专门为生成任务而设计的,其中提出一种自适应致密化策略来缓解不稳定的高斯梯度,实现稳健优化。值得注意的是,所提出的流程不需要对扩散网络进行任何预训练或微调,为 4D 生成任务提供更易于访问和实用的解决方案。
如图所示生成的3D资产例子:

Dreamfusion [23] 首先提出了 SDS 损失 [23, 31] 用于 NeRF 优化,这是当今文本转 3D 方法中最流行的技术。为了缓解多视图 Janus 问题,Zero123 [14] 和 Sycn-Dreamer [15] 对 2D 扩散模型进行了微调,使图像生成器具有视点控制能力,而后来的研究 [16,18,27,28] 则明确在一次扩散过程中生成固定的多视图图像。
除了为扩散模型配备多视图或深度感知外,另一个进展方向是 3D 表示。 Magic3D [11] 遵循可微分优化的思想,采用了两阶段生成流水线,并将 3D 表示改为 instant-NGP [21] 和 DMTet [26],实现了更快的运行时间并提高了生成质量。Direct2.5 [18] 采用显式网格表示,并使用可微分光栅化进行快速网格优化。最近,DreamGaussian [30] 凭借新开发的 3DGS,通过用 3D 高斯表示取代 NeRF,展示了在几分钟内生成 3D 目标的能力,展示了在 3D 生成任务中使用显式点表示的潜力。
动态三维重建是计算机视觉与图形学领域的另一个热门研究课题。通过将静态 NeRF [20] 框架扩展到动态场景,动态 NeRF [4,5,10,35] 在动态三维重建方面取得了显著进展。然而,受限于隐式神经表示和动态三维信息的复杂性,动态 NeRF 仍然存在优化速度慢和重建质量低的问题。随着 3DGS [8] 的发展,研究人员很快将 3D 高斯扩展到动态场景表示,与基于隐式神经表示的 D-NeRF 相比,实现了更快的训练和渲染速度。动态 3D 高斯 [19] 将每帧 3DGS 优化应用于 4D 场景重建。一些研究 [34, 36] 尝试将显式基于点的 3DGS 与隐式神经场相结合,以进行动态信息建模,而Gaussian-flow [12] 引入显式每点运动模型来表示 4D 场景,而无需使用隐式神经网络。值得注意的是,将高斯重建扩展到 4D 重建并非易事,因为每个重建流水线都需要在每个阶段对超参进行启发式调整。
3D 内容生成和视频扩散技术的最新发展,引发了研究人员对从各种输入条件下探索 4D 内容生成的兴趣。MAV3D [29] 展示了文本到 4D 生成的早期尝试。通过利用从视频扩散模型中得出的分数蒸馏采样(SDS),MAV3D 优化了基于文本提示的动态 NeRF。与此同时,Consistent4D [7] 引入了视频到 4D 的任务。该方法利用来自图像扩散模型的预训练知识,通过 SDS 优化来优化动态 NeRF,展示了从预训练的 2D 扩散模型生成高质量 4D 内容的潜力。4DGen [37] 引入了一个生成动态 3D 模型的框架,该框架在多视图扩散模型中的关键帧上使用时空伪标签。然而,由于其渲染保真度受到隐式神经表征的限制,并且在扩散生成过程中存在不充分的时空信息交换,因此其生成的整体质量可以进一步提高。
如图所示:该方法总体流程。给定一个视频输入,应用多视图扩散模型来生成连贯的多视图序列,这些序列可作为空间和时间锚点。接下来,用多视图 SDS 损失和参考损失训练可变形 3D 高斯。对于文本到 4D 的生成,其流程可以自然扩展与现成的文本到视频模块集成来接受文本输入。
3D Gaussian Splatting 的概念最初是在 [8] 提出的,其中使用基于点的显式表示来建模 3D 场景。在 3D 重建中,通过基于点的可微分体渲染优化 3D 高斯点云。将连续场景动态呈现为 3D 运动场,此表示可以自然扩展到 4D 场景。受 [34] 的启发,将 4D 场景呈现为具有基于六角形平面(hex-plane)变形场的 3D 高斯点云,表示为 F(S,t)。
标准的 3D Gaussian Splatting 技术通常采用点云致密化控制策略,动态调整单位体内的高斯数量及其密度。这种自适应方法允许从初始的稀疏高斯集过渡到更密集的配置,以更好地表示 3D 场景。论文 [34] 中介绍的 4D Gaussian Splatting 方法,采用了与原始 3DGS [8] 中类似的致密化策略,即使用基于视图空间位置梯度的固定致密化阈值。然而,虽然固定梯度阈值策略在重建方面表现出色,特别是当多个视图能够对目标场景提供稳健且冗余的覆盖时,但它在生成设置中的表现并不理想。这种限制源于输入单幅图像或单目视频所施加的限制,导致每个训练目标的空间和尺度维度存在很大的不确定性。这将导致不同情况下最佳阈值的不同。
为了解决这个问题,提出一种自适应阈值方法,其中只选择具有相对较大梯度的候选点进行致密化。其方法基于对每个点累积梯度的统计分析,在整个训练过程中遵循相似形状的对数分布。应用一个自适应阈值,滤除梯度相对较小的高斯分布,只对梯度较大的高斯分布进行致密化。自适应阈值设置,为每次致密化操作选择固定百分比(前 λ%)的最高梯度点。这确保阈值适应梯度的分布并保持稳定的相对位置。
提出的流程采用图像扩散模型中的分数蒸馏采样(SDS)[23]来优化动态高斯。图像-到-图像扩散模型 Zero123 可以在任何相对摄像机位置生成目标视图图像,但一次只能生成一个目标视图,因此擅长从所有视图优化 3D 目标,但不擅长从多个目标视图生成空间一致的图像。相比之下,Zero123++ [27] 利用参考注意 [38] 来模拟来自多个目标视图以及输入视图的图像之间关系,从而产生多视图一致性输出,但代价是固定目标摄像机位置。在计算 SDS 损失时,将 Zero123++ 的多视图一致性输出作为 Zero123 的输入图像,从而结合这两个模型的优势。
遵循基于多视图扩散 3D 生成视图的生成理念,4D 内容创建的一个实用解决方案是生成 4D 场景的多视图视频,然后应用多视图视频条件 SDS 损失来优化场景。然而,单独的每帧生成去合成时域一致的多视图视频相当困难。受零样本视频生成方法 [9] 的启发,提出一个无需训练的时域注意模块,使 Zero123++ [27] 具有时域-觉察能力。如图所示:多视图序列推理的时空注意融合框架
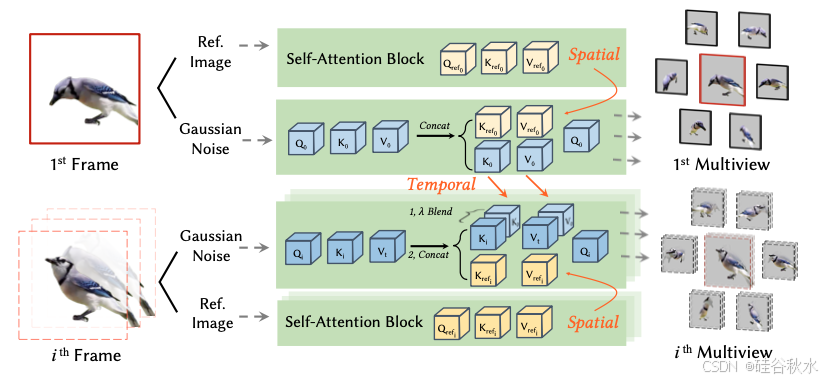
在设计中,在对第一帧的多视图图像进行去噪时获得注意信息。然后将记录的注意应用于后面的去噪过程。首先计算初始帧 T0 的 Key K0 和 Value V0。随后,对于每个后续帧 Tt,其中 t ∈ {1,…,N},对 Key Kt 和 Value Vt 与从第一帧 T0 得出的初始Key K0 和 Value V0 执行混合操作。
此外,按照 [27,39] 中概述的方法采用参考注意机制,从输入图像中提取局部条件。在此参考注意机制中,K和V都是拼接参考图像特征和噪声输入图像特征所获得。时域注意模块设计简单而有效,优于 [9] 中提出的普通跨帧注意的时间一致性、图像质量和 3D 一致性。
从单目参考视频生成多视图序列后,可以在每个时间步 t 获取 6 个锚视图 {I/i/t} 和一个参考视图 I/ref/i。在优化过程中,用多视图的分数蒸馏采样 (SDS),利用生成的图像 {I/i/t} 结合参考图像 I/tref/t。这个过程,选择最接近渲染相机视图的参考图像来计算 SDS 损失。按照方法 [30],用参考图像来计算重建损失 Lrec 和前景掩码损失 Lmask。
该方法旨在轻松适应文本和图像输入,提供新功能,例如直接从文本描述或静态图像生成视频序列。用 2D 扩散模型 SDXL [22] 启动此过程,该模型从文本输入生成图像。然后,此 2D 输出通过视频扩散模型(例如 SVD [3])转换为视频序列,为静态图像添加时间连贯性和运动。最后,上述流程进一步将视频序列提升到 4D 场景,引入额外的空间维度,从而创造出超越传统 2D 或 3D 媒体的沉浸式体验。

















 1989
1989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









