










24年12月来自Meta和UC San diego的论文“Training Large Language Models to Reason in a Continuous Latent Space”。
大语言模型 (LLM) 仅限于在“语言空间”中进行推理,它们通常使用思维链 (CoT) 来表达推理过程,以解决复杂的推理问题。然而,认为语言空间可能并不总是推理的最佳空间。例如,大多数单词tokens主要用于文本连贯性,对推理来说并不是必不可少的,而一些关键tokens需要复杂的规划,对 LLM 构成了巨大挑战。为了探索 LLM 在无限制潜空间中推理的潜力,而不是使用自然语言,引入一种新的范式 Coconut(连续思维链)。
利用 LLM 的最后一个隐状态作为推理状态(称为“连续思维”)的表示。不是将其解码为单词tokens,而是将其作为后续输入直接嵌入连续空间,反馈给 LLM。实验表明,Coconut 可以在多个推理任务中有效地增强 LLM。这种潜推理范式导致高级推理模式的出现:连续思维可以编码多个备选的下一步推理步骤,从而使模型能够执行广度优先搜索 (BFS) 来解决问题,而不是过早地选择像 CoT 这样的单一确定性路径。在某些需要在规划过程中进行大量回溯的逻辑推理任务中,Coconut 的表现优于 CoT,推理过程中的思维 tokens 更少。
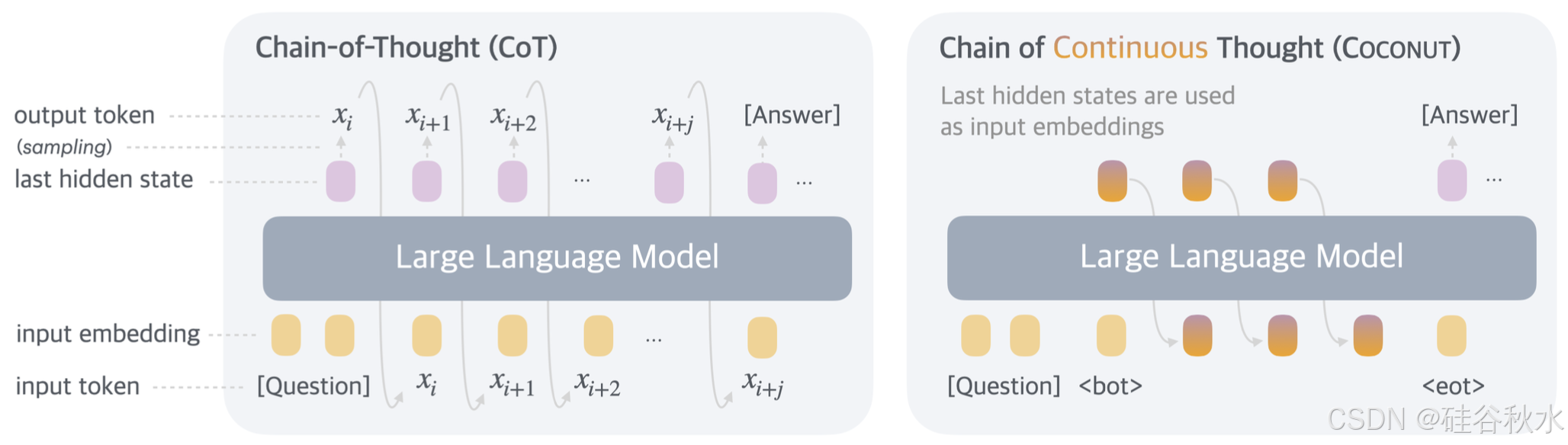
如图所示连续思维链 (Coconut) 与思维链 (CoT) 的比较。在 CoT 中,模型将推理过程生成为单词token序列(例如,图中的 [x/i, x/i+1,…, x/i+j])。Coconut 将最后一个隐状态视为推理状态的表示(称为“连续思维”),并直接将其用作下一个输入嵌入。这允许 LLM 在不受限制的潜空间而不是语言空间中进行推理。
大语言模型 (LLM) 已展现出卓越的推理能力,这是通过对人类语言进行大量预训练而产生的(Dubey,2024;Achiam,2023)。虽然下一个token预测是一个有效的训练目标,但它对 LLM 作为推理机器施加一个基本约束:LLM 的显式推理过程必须在单词token中生成。例如,一种流行的方法,称为思维链 (CoT) 推理(Wei,2022),涉及提示或训练 LLM 使用自然语言逐步生成解决方案。然而,这与某些人类认知结果形成鲜明对比。神经影像学研究一直表明,语言网络(负责语言理解和生成的一组大脑区域)在各种推理任务中基本处于不活跃状态(Amalric & Dehaene,2019;Monti,2012、2007、2009;Fedorenko,2011)。进一步的证据表明,人类语言是为交流而不是推理而优化的(Fedorenko,2024)。
当 LLM 使用语言进行推理时,会出现一个重大问题:每个特定推理tokens所需的推理量差异很大,但当前的 LLM 架构为预测每个token分配的计算预算几乎相同。推理链中的大多数tokens仅是为了流畅性而生成的,对实际推理过程贡献不大。相反,一些关键tokens需要复杂的规划,对 LLM 构成了巨大的挑战。虽然之前的研究尝试通过促使 LLM 生成简洁的推理链(Madaan & Yazdanbakhsh,2022)或在生成一些关键tokens之前执行额外推理(Zelikman,2024)来解决这些问题,但这些解决方案仍然局限于语言空间,并没有解决根本问题。相反,理想的情况是,LLM 能够自由地进行推理,不受任何语言限制,然后只在必要时将其发现转化为语言。
思维链 (CoT) 推理。广泛使用思维链这一术语指在输出最终答案之前生成语言中中间推理过程的方法。这包括提示 LLM(Wei,2022;Khot,2022;Zhou,2022),或训练 LLM 生成推理链,无论是使用监督微调(Yue,2023;Yu,2023)还是强化学习(Wang,2024;Havrilla,2024;Shao,2024;Yu,2024a)。(Madaan & Yazdanbakhsh,2022)将 CoT 中的tokens分为符号、模式和文本,并提出根据对其角色的分析来指导 LLM 生成简洁的 CoT。最近的理论分析从模型表达能力的角度证明 CoT 的实用性(Feng,2023;Merrill & Sabharwal,2023;Li,2024)。通过使用 CoT,Transformer 的有效深度会增加,因为生成的输出会循环回到输入(Feng,2023)。虽然 CoT 已被证明对某些任务有效,但其自回归生成特性使得在更复杂的问题上模仿人类推理变得具有挑战性(LeCun,2022;Hao,2023),这通常需要规划和搜索。有研究为 LLM 配备显式树搜索算法(Xie et al., 2023; Yao et al., 2023; Hao et al., 2024),或者在搜索动态和轨迹上训练 LLM(Lehnert et al., 2024; Gandhi et al., 2024; Su et al., 2024)。
LLM 中的潜推理。以前的研究大多将 LLM 中的潜推理定义为 Transformer 中的隐藏计算(Yang et al., 2024; Biran et al., 2024)。(Yang 2024)构建了一个两-跳(two-hop)推理问题的数据集,发现可以从隐表示中恢复中间变量。 (Biran 2024) 进一步提出通过“back-patching”隐表示来干预潜推理。(Shalev 2024) 在 LLM 中发现了并行的潜推理路径。另一项研究发现,即使模型生成 CoT 来推理,模型实际上也可能使用不同的潜推理过程。这种现象被称为 CoT 推理的不忠实性(Wang,2022;Turpin,2024)。为了增强 LLM 的潜推理能力,先前的研究提出用额外的token来增强它。(Goyal 2023) 通过在训练语料库中随机插入可学习的 token 来预训练模型。这提高 LLM 在各种任务上的性能,尤其是在使用 token 进行监督微调时。另一方面,(Pfau 2024) 进一步探索填充 token(例如“…”)的使用,并得出结论,它们对于高度可并行化的问题非常有效。然而,(Pfau 2024) 提到这些方法不会像 CoT 那样扩展 LLM 的表达能力;因此,它们可能无法扩展到更一般和更复杂的推理问题。(Wang 2023) 提出在生成下一个推理步骤之前将规划tokens预测为离散潜变量。最近,人们还发现可以通过知识蒸馏(Deng,2023)或逐步缩短 CoT 的特殊训练课程(Deng,2024)将 CoT 推理“内化”为 Transformer 中的潜推理。(Yu 2024b) 还提出从复杂推理算法生成的数据中蒸馏出一个可以进行潜推理的模型。
Coconut(连续思维链)用于在无约束潜空间中进行推理。首先介绍语言模型的背景和符号。对于输入序列 x =(x/1, …, x/T),标准大语言模型 M 可以描述为:
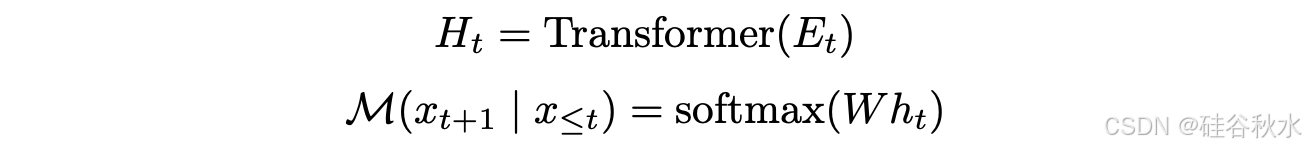
其中 E/t = [e(x/1), e(x/2), …, e(x/t)] 是直到位置 t 的 token 嵌入序列;Ht 是直到位置 t 的所有 token 隐状态矩阵;h/t 是位置 t 的最后一个隐状态,即 h/t = H/t[t, :];e(·) 是 token 嵌入函数;W 是语言模型头的参数。
在所提出的 Coconut 方法中,LLM 在“语言模式”和“潜模式”之间切换(如上图所示)。在语言模式下,该模型作为标准语言模型运行,自回归生成下一个token。在潜模式下,它直接利用最后一个隐状态作为下一个输入嵌入。这个最后的隐状态代表当前的推理状态,称为“连续思维”。
特殊token 和 分别用于token潜思维模式的开始和结束。例如,假设潜推理发生在位置 i 和 j 之间,即 x/i = 和 x/j = 。当模型处于潜模式(i < t < j)时,用前一个token的最后一个隐状态来替换输入嵌入,即 E/t = [e(x/1), e(x/2), …, e(x/i), h/i, h/i+1, …, h/t−1]。
潜模式结束后(t ≥ j),输入恢复为使用token嵌入,即 E/t = [e(x/1), e(x/2), …, e(x/i), h/i, h/i+1, …, h/j−1, e(x/j), …, e(x/t)]。值得注意的是,最后的隐状态已经由最后的归一化层处理过,因此它们的数量级不是太大。当 i < t < j 时,M(x/t+1 | x ≤ t) 没有定义,因为潜思维不打算映射回语言空间。但是,softmax(W*h/t) 仍然可以用于探测目的。
训练程序。在这项工作中,专注于一个问题解决设置,其中模型接收一个问题作为输入,并期望通过推理过程生成答案。用语言 CoT 数据来监督连续思维,实施受 (Deng 2024) 启发的多-阶段训练课程。如图所示,在初始阶段,模型在常规 CoT 实例上进行训练。在后续阶段,即第 k 阶段,CoT 中的前 k 个推理步骤被替换为 k × c 个连续思维,其中 c 是一个超参,控制替换单个语言推理步骤的潜思维数量。遵循 (Deng 2024),还会在训练阶段切换时重置优化器状态。插入 和 token(不计入 c)来封装连续思维。

在训练过程中,优化正常的负对数似然损失,但掩码问题和潜思维的损失。需要注意的是,目标并不鼓励连续思维去压缩被移除的语言思维,而是促进对未来推理的预测。因此,与人类语言相比,LLM 可以学习更有效的推理步骤表示。
训练细节。连续思维是完全可微的,并允许反向传播。当前训练阶段安排 n 个潜思维时,执行 n + 1 次前向传递,每次传递计算一个新的潜思维,最后进行额外的前向传递以获得剩余文本序列的损失。虽然可以通过使用 KV 缓存来节省任何重复计算,但多次前向传递的顺序性对并行性提出了挑战。进一步优化 Coconut 的训练效率仍然是未来研究的重要方向。
推理过程。Coconut 的推理过程类似于标准语言模型解码,不同之处在于在潜模式下,直接将最后一个隐状态作为下一个输入嵌入。挑战在于确定何时在潜模式和语言模式之间切换。当专注于解决问题的设置时,会在问题token后立即插入一个 token。对于 ,考虑两种潜策略:a) 在潜想法上训练二元分类器,使模型能够自主决定何时终止潜推理,或者 b) 始终将潜想法填充到恒定长度。这两种方法效果都相当好。因此,除非另有说明,否则在实验中使用第二种选项以简化操作。
实验中使用预训练的 GPT-2(Radford,2019)作为所有实验的基础模型。学习率设置为 1 × 10−4,有效批量大小为 128。按照 (Deng 2024)的做法,还在训练阶段切换时重置优化器。
数学推理。默认情况下,在每个推理步骤中使用 2 个潜想法(即 c = 2)。分析性能与 c 之间的相关性。除了初始阶段外,该模型还经历了 3 个阶段。然后,有一个额外的阶段,仍然使用 3 × c 个连续想法,如倒数第二阶段一样,但删除所有剩余的语言推理链。这处理长于 3 个步的推理链长尾分布。在初始阶段对模型进行 6 个epochs的训练,在剩余的每个阶段进行 3 个 epochs的训练。
逻辑推理。为每个推理步骤使用一个连续思维(即 c = 1)。除了初始阶段外,模型还经历了 6 个训练阶段,因为这两个数据集中推理步骤的最大数量为 6。然后,模型使用连续思维进行充分推理,以解决最后阶段的问题。每个阶段训练模型 5 个epochs。
对于所有数据集,在标准时间调度之后,模型停留在最后的训练阶段,直到第 50 个epochs。根据验证集上的准确性选择检查点。对于推理,手动设置连续思维的数量,使其与它们的最终训练阶段一致。对所有实验都使用贪婪解码。

















 154
154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









