







25年11月来自Generalist AI 团队的博客论文“GEN-0: Embodied Foundation Models That Scale with Physical Interaction”。
多年来,机器人领域的基础模型主要采用视觉语言预训练作为扩展机器人规模的垫脚石,这样能够将现有大型多模态模型的语义泛化优势迁移到机器人领域。然而,目前尚缺乏的是如何有效地在机器人领域本身扩展大型多模态模型的训练——建立能够证实机器人智能随着计算和数据量的增加而持续(且可预测地)提升的扩展规律,正如其他领域(例如LLM模型)的进步所依据的那样。这需要一种架构、训练流程和数据引擎,能够推动新的感知运动能力,提供行为泛化能力,并随着与真实物理世界交互所产生的庞大且不断扩展的经验而成长。
为此,其推出 GEN-0,这是一种新型的具身基础模型,专为直接在高保真原始物理交互上进行多模态训练而构建。其架构建立在视觉和语言模型的优势之上,同时又超越了它们——它原生设计用于捕捉人类水平的反思和物理常识。 GEN-0 的核心特性之一是谐波推理,它训练模型能够同时进行思考和行动,实现无缝衔接。
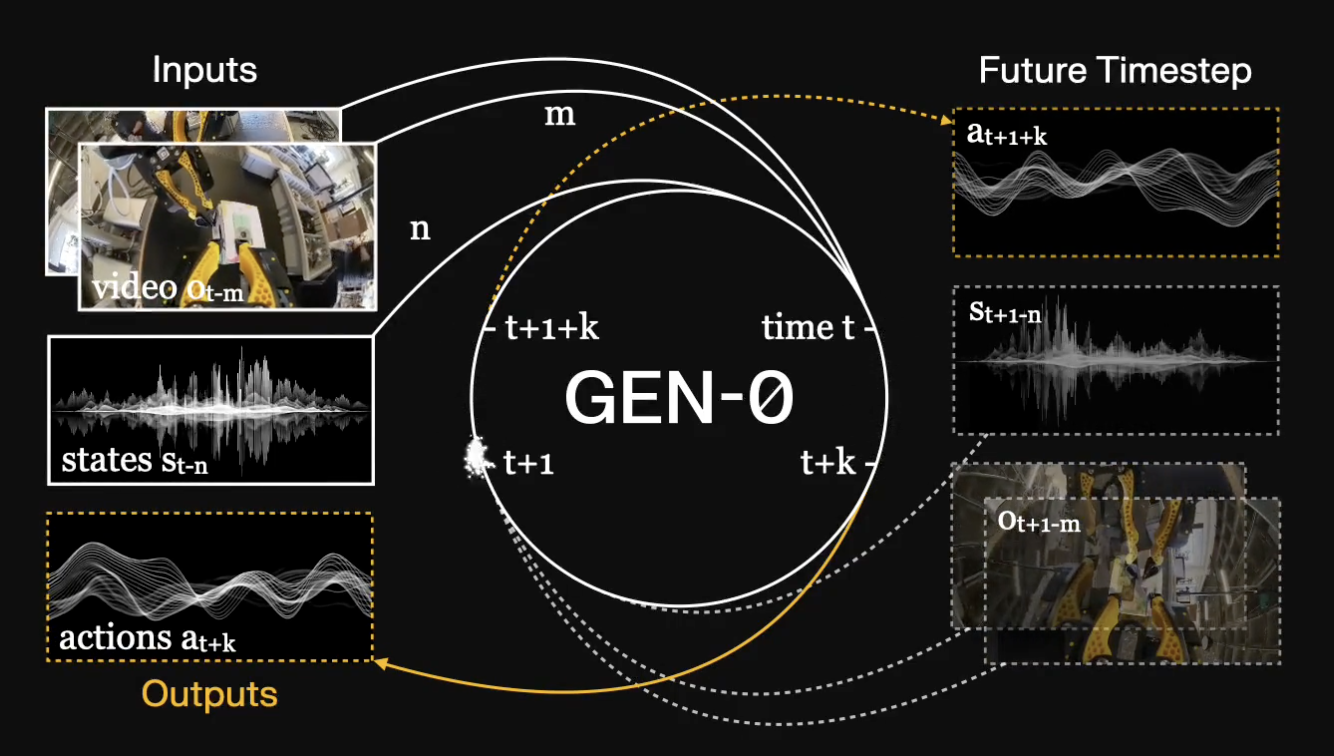
在之前的视频中展示早期原型机的部分功能,将分享 GEN-0 不仅拥有突破性的基础功能,而且这些功能还在不断扩展:
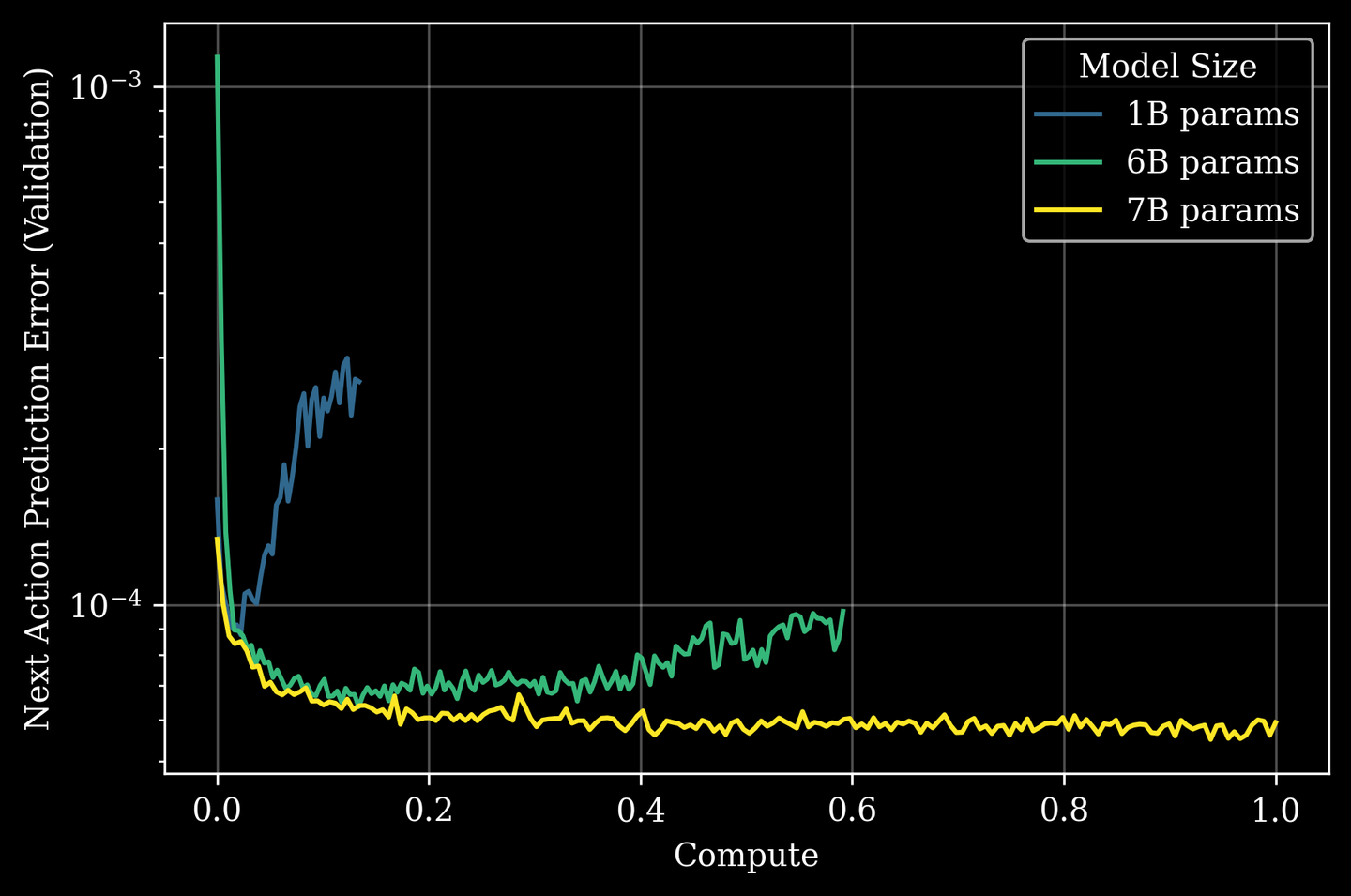
超越智能阈值——在机器人领域前所未有的高数据量环境下,70 亿数据量时模型会发生相变,较小的模型会出现性能停滞,而较大的模型则会持续改进。此后,将 GEN-0 的模型规模扩展到 100 亿以上,并观察到模型能够快速适应新任务,且所需的后训练量越来越少。
扩展规律——GEN-0 模型展现出强大的扩展规律,即更多的预训练数据和计算资源能够持续(且可预测地)提升模型在众多任务中的后训练性能。
谐波推理——虽然对于语言聊天机器人来说,在响应之前花更多时间思考是很容易实现的,但对于在现实世界中运行的物理系统来说,情况并非如此简单——物理定律不会停止。为了解决这个问题,谐波推理采用一种全新的模型训练方法,在异步的、连续时间的感知和动作 token 流之间创建一种“谐波”交互。这样能够扩展到非常大的模型规模,而无需依赖系统1-系统2架构或推理时指导。
跨平台——GEN-0架构的设计使其能够适用于不同的机器人。在6自由度、7自由度和16+自由度的半人形机器人上测试模型。
不再受限于数据——GEN-0在其内部的机器人数据集上进行预训练,该数据集包含超过27万小时的真实世界多样化操作数据,并且每周以1万小时的速度增长,还在加速增长。
预训练的科学——不同来源(例如数据工厂)的预训练数据的不同组合会产生具有不同特征的 GEN-0 模型。
GEN-0 标志着一个新时代的开始:具身基础模型的能力能够随着物理交互数据(不仅限于文本、图像或模拟数据,而是来自真实世界)的增加而可预测地扩展。

超越智能阈值
扩展实验表明,GEN-0 模型必须足够大才能吸收海量的物理交互数据。较小的模型在数据过载下表现出类似于“僵化”的现象,而较大的模型则持续改进——这表明模型智能能力发生了令人惊讶的“相变”:
10 亿模型在预训练期间难以吸收复杂多样的感觉运动数据——随着时间的推移,模型权重将无法吸收新信息。
60 亿模型开始受益于预训练,并展现出强大的多任务处理能力。
70 亿及以上的模型能够内化大规模机器人预训练数据,并仅需几千步的后训练即可将其迁移到下游任务中。
这是一种模型骨化(ossification)现象,此前的研究可能未能发现这一现象,原因在于:(a) 机器人领域迄今为止缺乏高数据量阶段;(b) 该阶段的模型规模足够大。在LLM文献中,高数据量阶段也曾观察到模型骨化现象,但模型规模要小得多,参数数量约为O(10M),而非O(1B)。这种相变发生在机器人领域,且模型规模要大得多,这与莫拉维克悖论不谋而合:人类毫不费力就能做到的事情——感知和灵巧性——所需的计算复杂度远高于抽象推理。实验表明,物理世界中的智能(即物理常识)可能具有更高的计算激活阈值,而才刚刚开始探索其背后的奥秘。
机器人领域的扩展规律
扩展规律通常在预训练阶段进行测量,如图所示,展示预训练期间模型规模与下游零样本任务计算量之间的关系。
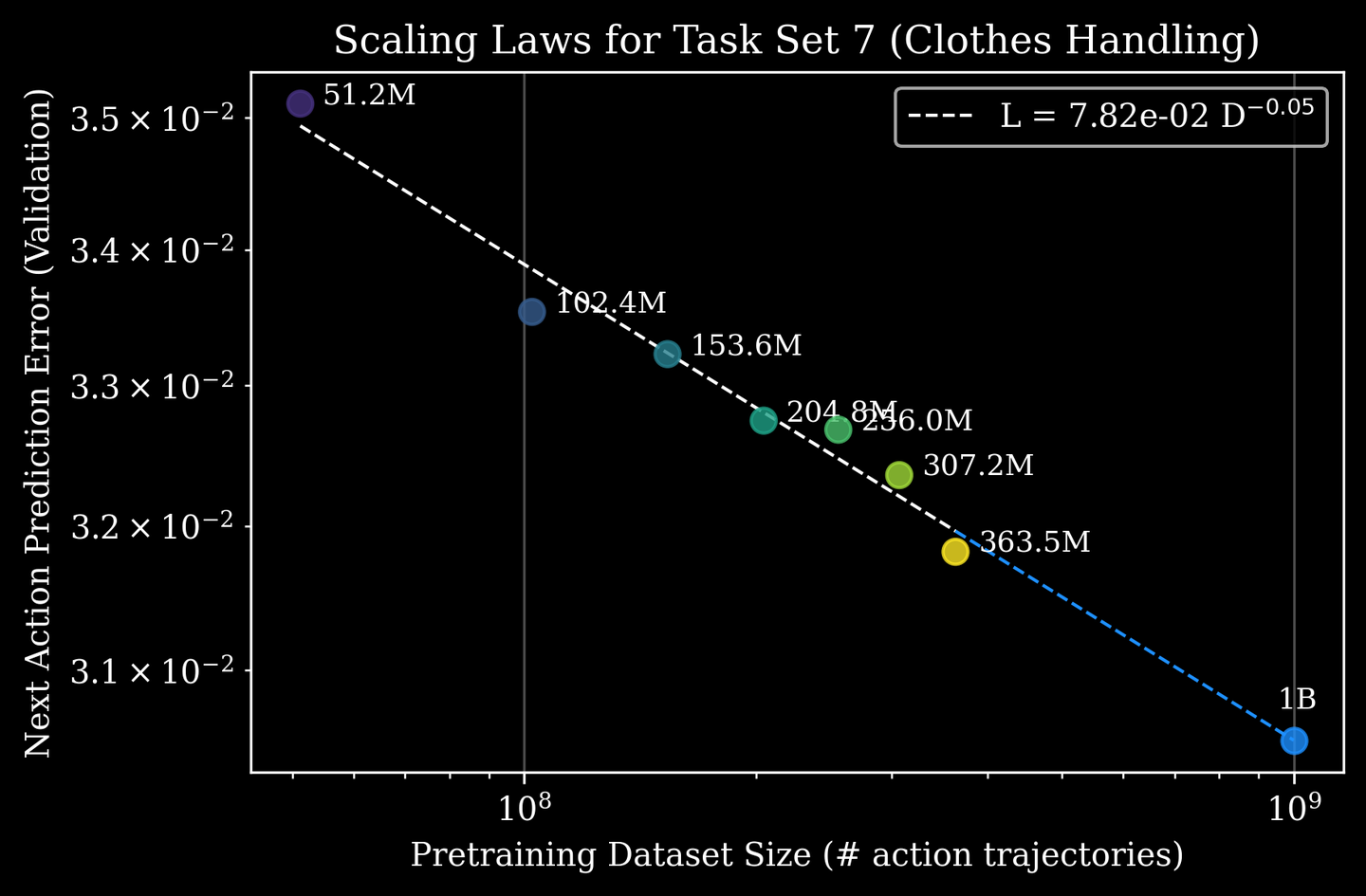
另一种扩展规律与预训练的优势在微调阶段的持续存在有关。在模型规模足够大的情况下,预训练数据规模与下游训练后性能之间存在显著的幂律关系(如图所示)。这适用于测量的所有任务,包括合作伙伴和客户启发式应用程序及其在服装、制造、物流、汽车和电子等众多行业领域的工作流程。
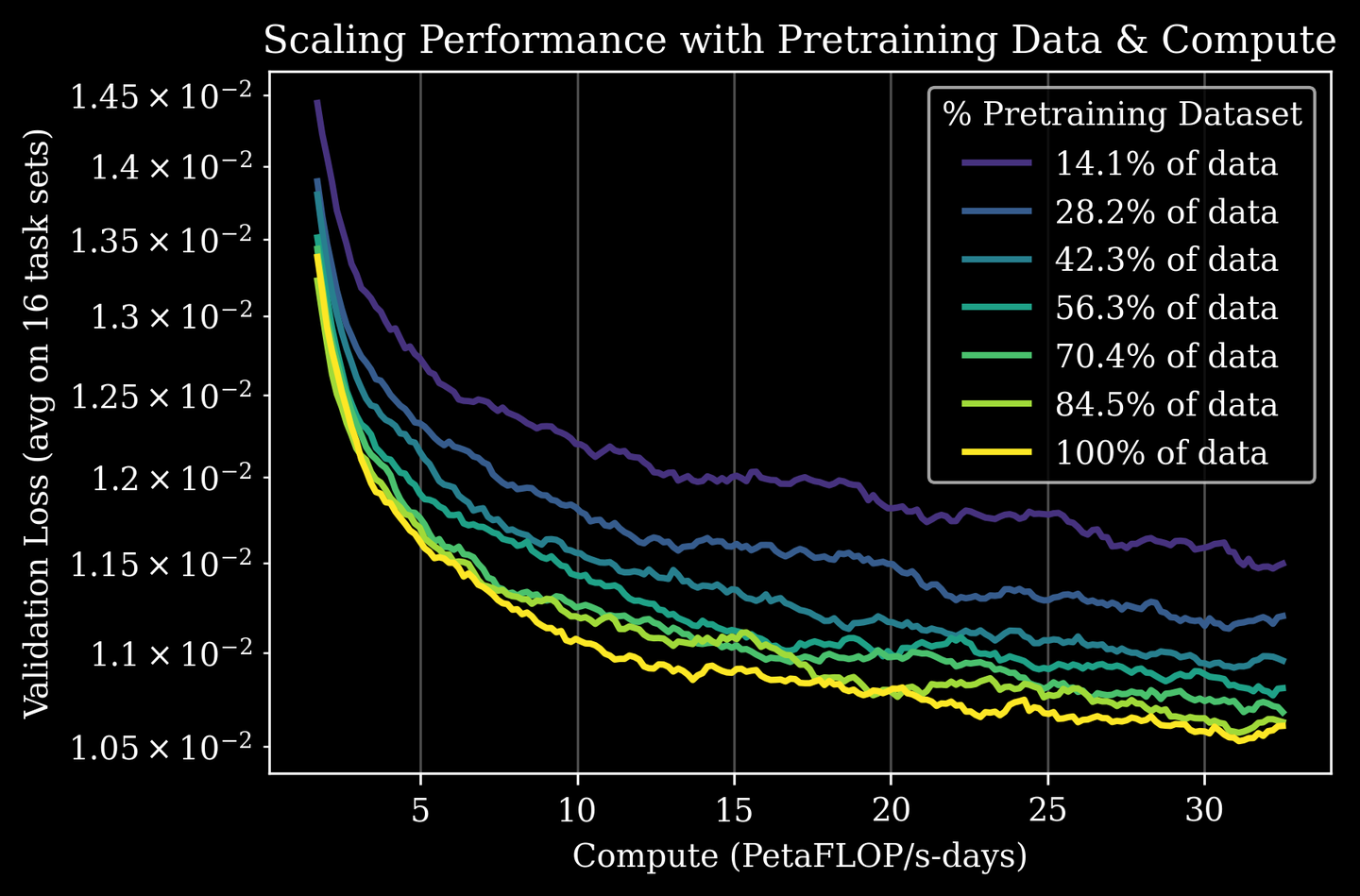
更具体地说,用不同的训练流程在预训练数据集的不同子集上预训练各种模型检查点(如图所示),然后在多任务语言条件数据上对这些检查点进行后训练,即在 16 个不同的任务集上同时进行监督式微调。更多的预训练可以提高下游模型在所有任务上的性能。
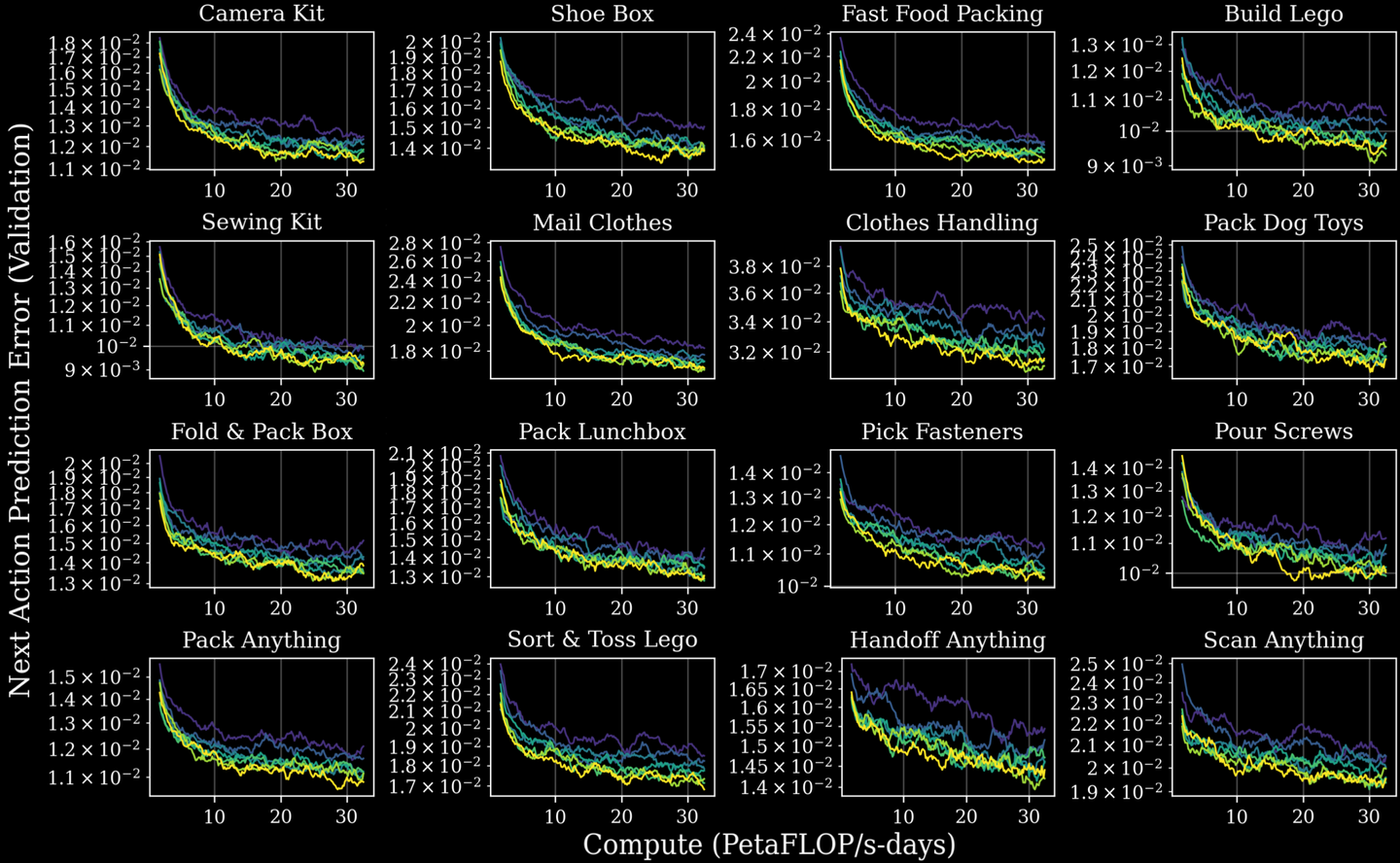
模型性能可以用幂律关系预测,由此可以回答诸如“需要多少预训练数据才能达到特定的下一步动作预测误差?”或“可以用更多的预训练数据来购买多少(针对特定任务的)后训练数据?”之类的问题。给定下游任务的固定数据和微调预算,以及大小 D 可变的预训练数据集,下游任务的验证误差 L(.) 可以通过以下形式的幂律来预测:
L(D) = (D_c/D)αD
例如,在“衣物处理”(涉及在真实工作场所对衣物进行分类、整理、扣扣和悬挂)任务中,可以使用 10 亿条动作轨迹来预测模型性能。这些估计可以指导关于合作伙伴相关任务的讨论,并可以估算出达到特定性能水平所需的额外数据量。
机器人技术不再受限于数据
基础模型基于前所未有的 27 万小时真实世界操作轨迹数据集进行训练,这些数据来自全球数千个家庭、仓库和工作场所的各种活动。如今,机器人数据运营每周新增超过 1 万小时,并且还在加速增长。这一切都得益于遍布全球的硬件网络以及数千台数据采集设备和机器人。
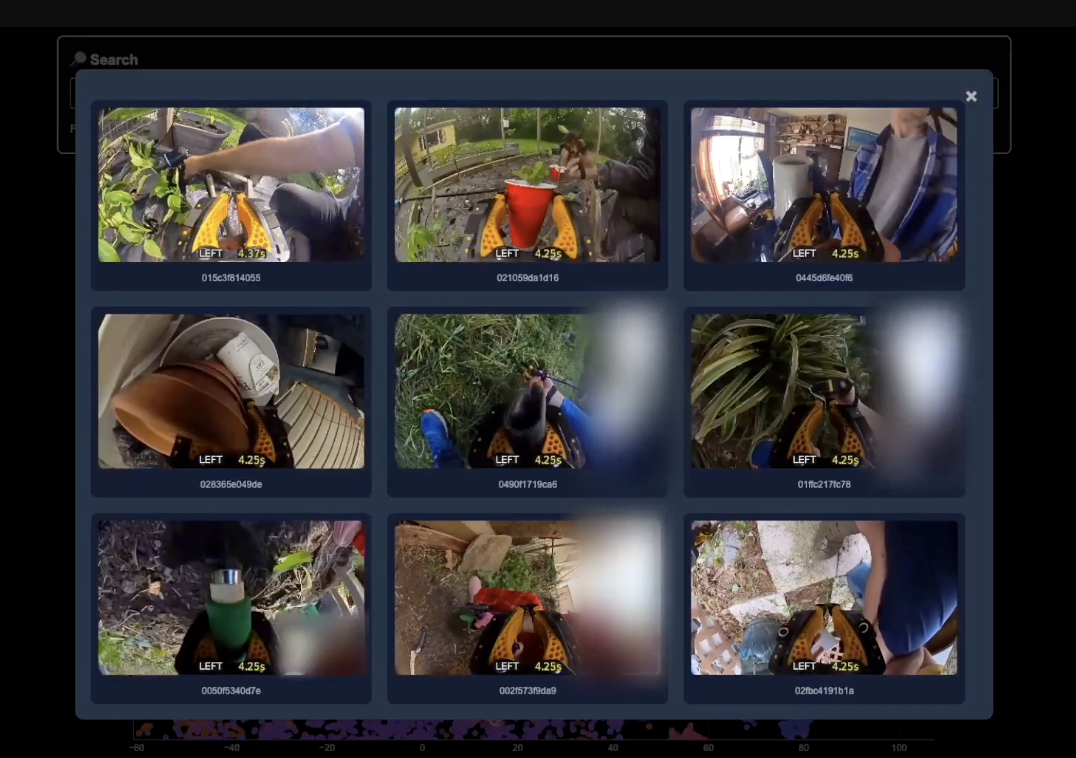
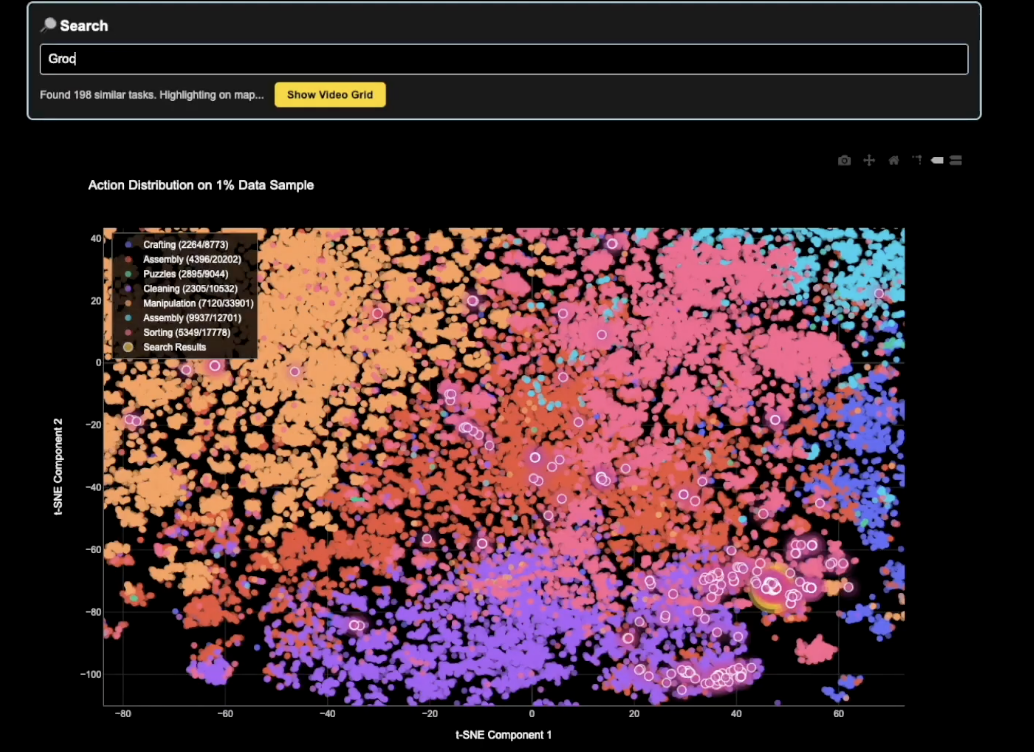
绘制操作宇宙图
为了扩展 GEN-0 的功能,其正在构建有史以来规模最大、种类最丰富的真实世界操作数据集,涵盖人类能想到的所有操作任务——从削土豆皮到拧螺栓——遍及家庭、面包房、洗衣店、仓库、工厂等各种场所。以下是构建的一个用于探索该宇宙的内部搜索工具示例:
互联网规模机器人数据的基础设施
构建支持这种规模的运营和机器学习基础设施绝非易事。为了处理如此大规模的机器人模型和数据,构建定制硬件、数据加载器和网络基础设施(包括铺设新的专用互联网线路),以支持来自世界各地不同数据采集站点的上行带宽。签订多云协议,构建定制上传服务器,将核心数扩展到 O(10K) 以进行持续的多模态数据处理,并利用前沿视频基础模型背后的数据加载技术压缩数十 PB 的数据,这些模型每天的训练能够吸收相当于 6.85 年真实世界操作经验的数据。
预训练的科学原理
通过大规模消融实验,发现数据质量和多样性比数据量本身更为重要,精心构建的数据混合可以带来不同的预训练模型特征。这些任务集分为 3 组,分别评估不同的维度:灵巧性、实际应用和泛化能力。
性能指标包括验证预测均方误差 (MSE_val = ||a* - a||_22) 和逆 Kullback-Leibler 散度(逆 KL),后者能更好地衡量模型的模式搜索行为。为了估计逆 KL,用蒙特卡罗估计器,其中策略通过以 M 个策略样本为中心的单位方差高斯混合模型来诱导经验密度 q,而数据/真实值则诱导以 a* 为中心的单位方差高斯分布 p(a)。用策略样本来近似期望值:D^_KL(q|p)。
实验表明,预测误差和逆KL值均较低的模型在训练后进行监督微调(SFT)时往往表现更佳,而预测误差高、反向KL值较低的模型则往往呈现更明显的分布多峰性,这有助于训练后的强化学习。大规模地采用多种数据收集策略,这样能够持续进行A/B测试,找出哪些数据最能提升预训练效果。

















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









