







【医学影像 AI】医学通用人工智能的基础模型
0. 论文介绍
0.1 什么是医学通用人工智能(GMAI)
医学通用人工智能(GMAI)是指一类先进的基础模型,具备处理多种医疗任务的能力,而无需针对每个具体任务进行单独训练。
与传统的医学 AI 模型不同,GMAI 可以通过少量或无需标注数据,灵活应对不同的医疗需求。
GMAI 通过在大规模、多样化的数据集上进行自监督学习,能够理解和整合来自影像、电子健康记录(EHR)、组学、实验室结果等多种数据类型,生成详细的诊断报告、治疗建议甚至蛋白质设计方案。
0.2 论文简报
2023年4月,美国斯坦福大学 Moor、哈佛大学 Banerjee 等在 Nuture 上发表研究论文:Foundation models for generalist medical artificial intelligence,提出了医学通用人工智能 (GMAI, Generalist Medical Artificial Intelligence) 的医学 AI 新范式。
本文对比了传统的医学 AI 与 GMAI 的区别,并从能力的角度对 GMAI 进行了定义以及可能的实现方案,并对 GMAI 的未来应用场景与面临的挑战进行了讨论。

0.3 下载与引用
论文下载地址:
https://www.nature.com/articles/s41586-023-05881-4
论文引用:
Moor, M., Banerjee, O., Abad, Z.S.H. et al. Foundation models for generalist medical artificial intelligence. Nature 616, 259–265 (2023). https://doi.org/10.1038/s41586-023-05881-4
0.4 摘要
高度灵活、可重复使用的人工智能(AI)模型的异常快速发展可能会在医学领域带来新的能力。
我们提出了一种新的医学人工智能范式,我们称之为医学通用人工智能 (GMAI, Generalist Medical Artificial Intelligence) 。
- GMAI模型将能够使用很少或没有特定任务的标记数据来执行各种任务。
- 通过对大型、多样化的数据集进行自我监督,GMAI 将灵活解释医疗模式的不同组合,包括来自成像、电子健康记录、实验室结果、基因组学、图表或医学文本的数据。
- 模型能产生富有表现力的输出,如自由文本解释、口头推荐或图像注释,以展示先进的医学推理能力。
我们确定了GMAI的一组高影响力的潜在应用,并列出了实现这些应用所需的具体技术能力和培训数据集。
我们预计,支持GMAI的应用程序将挑战目前监管和验证医学人工智能设备的策略,并将改变与收集大型医疗数据集相关的做法。
BTW:我们列出了实现医学人工智能范式转变的具体策略。我们描述了新一代模型将实现的一系列潜在的高影响力应用。我们指出了GMAI要实现其承诺的临床价值必须克服的核心挑战。
1. 引言
最新一代的人工智能模型基础模型——在海量、多样化的数据集上进行训练,可以应用于许多下游任务。单个模型现在可以在各种各样的问题上实现最先进的性能,从回答有关文本的问题到描述图像和玩视频游戏。这种多功能性代表了与上一代人工智能模型的明显变化,上一代AI模型旨在一次解决一个特定任务。
在不断增长的数据集、模型大小的增加和模型架构的进步的推动下,基础模型提供了前所未有的能力。例如,在2020年,语言模型GPT-3解锁了一项新功能:上下文学习,通过该模型,该模型仅通过从包含几个示例的文本解释或“提示(prompt)”中学习,就可以执行从未明确训练过的全新任务。此外,许多最近的基础模型能够接收和输出不同数据模型的组合。例如,最近的Gato模型可以聊天、为图像添加字幕、玩视频游戏和控制机器人手臂,因此被描述为"通用代理(generalist agent2.)"。由于某些能力只出现在最大的模型中,因此预测更大的模型能够完成什么仍然具有挑战性。
尽管早期已经有开发医学基础模型的努力,但由于难以访问大型、多样化的医学数据集、医学领域的复杂性以及这一发展的及时性,这一转变尚未广泛渗透到医学人工智能中。
相反,医学人工智能模型在很大程度上仍然是采用特定任务的模型开发方法开发的。例如,胸部X射线解释模型可以在数据集上进行训练,在该数据集中,每张图像都被明确标记为肺炎阳性或阴性,这可能需要大量的注释工作。该模型只能检测肺炎,无法进行撰写全面放射学报告的完整诊断工作。这种狭隘的、特定于任务的方法产生了不灵活的模型,仅限于执行训练数据集及其标签预定义的任务。在当前的实践中,如果不在另一个数据集上重新训练,这些模型通常无法适应其他任务(甚至无法适应同一任务的不同数据分布)。在获得美国食品和药物管理局批准的500多个临床医学人工智能模型中,大多数只被批准用于1或2个狭窄的任务。
当前医学 AI 模型的局限性在于:
灵活性低:采用特定任务的模型开发方法开发,仅限于执行训练数据集及其标签预定义的任务。
泛化能力差:模型表现依赖于训练数据,如果使用不同医疗设备或处理不同患者群体的数据,模型表现可能下降。
数据依赖性高:需要大量精确标记的数据,对于罕见疾病或少数群体的数据难以实现。
在本文中,我们概述了基础模型研究的最新进展如何破打破一特定任务的范式。这些包括多模式架构和无需显式标签的自我监督学习技术的兴起(例如,语言建模和对比学习),以及情境学习能力的出现。这些进步将促进医学通用人工智能 (GMAI, Generalist Medical Artificial Intelligence) 的发展,GMAI是一类先进的医学基础模型,Generalist 意味着它们将在医疗应用中广泛使用,在很大程度上取代特定任务的模型。
直接受到医学之外的基础模型的启发,我们确定了将 GMAI模型与传统医学AI模型区分开来的三个关键能力(图1)。
- 首先,将GMAI模型适应新任务就像用简单的英语(或另一种语言)描述任务一样简单。模型将能够通过向它们解释新任务(动态任务规范)来解决以前看不见的问题,而不需要重新训练。
- 其次,GMAI模型可以接受输入,并使用不同的数据模式组合产生输出(例如,可以接收图像、文本、实验室结果或其任何组合)。这种灵活的交互性与更严格的多模态模型的约束形成鲜明对比,后者总是使用预定义的模态集作为输入和输出(例如,必须始终同时接收图像、文本和实验室结果)。
- 第三,GMAI模型将正式表示医学知识,使他们能够推理以前看不见的任务,并使用医学上准确的语言来解释他们的输出。
我们列出了实现医学人工智能范式转变的具体策略。此外,我们描述了新一代模型将实现的一系列潜在的高影响力应用。最后,我们指出了GMAI要实现其承诺的临床价值必须克服的核心挑战。
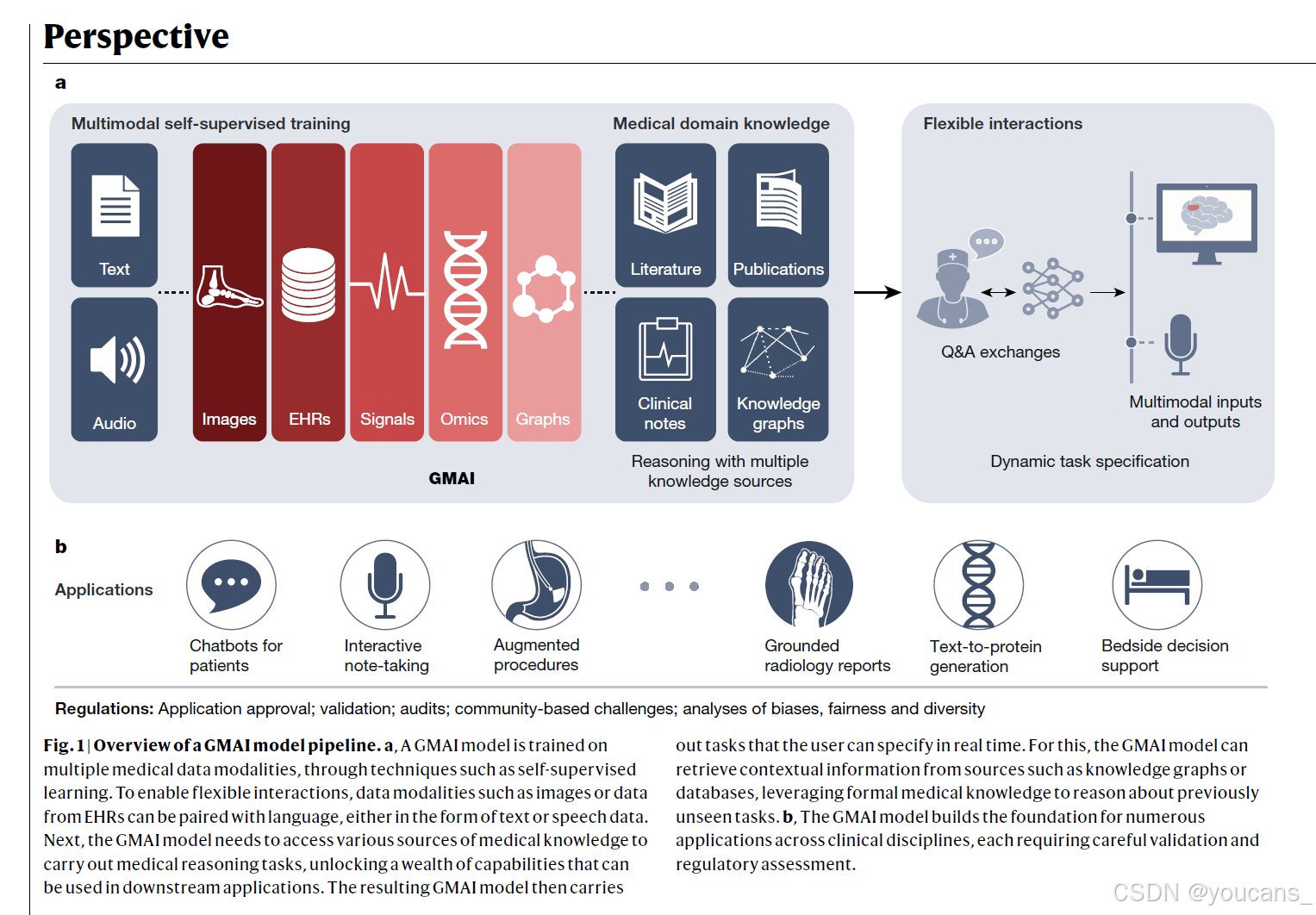
图1: GMAI模型流程概述。
a、 GMAI模型通过自我监督学习等技术在多种医学数据模式上进行训练。为了实现灵活的交互,EHR中的图像或数据等数据形式可以与语言配对,无论是文本还是语音数据。接下来,GMAI模型需要访问各种医学知识来源来执行医学推理任务,从而解锁可用于下游应用程序的丰富功能。然后,生成的GMAI模型执行用户可以实时指定的任务。为此,GMAI模型可以从知识图或数据库等来源检索上下文信息,利用正式的医学知识对以前看不见的任务进行推理。
b、 GMAI模型为跨临床学科的众多应用奠定了基础,每种应用都需要仔细的验证和监管评估。
2. 通用模型在医学人工智能中的应用潜力
GMAI模型有望解决比当前的医学人工智能模型更多样化、更具挑战性的任务,即使对特定任务几乎不需要标签。
在GMAI的三个定义能力中,有两个能够实现GMAI模型和用户之间的灵活交互:第一,执行动态指定任务的能力;第二,支持数据模式灵活组合的能力。第三种能力要求GMAI模型正式表示医学领域知识,并利用它进行高级医学推理。
最近的基础模型已经通过灵活组合多个模型或在测试时动态指定新任务展示了GMAI的各个方面,但要构建具有所有三种功能的GMAI模型,仍需要取得实质性进展。例如,显示医学推理能力的现有模型(如GPT-3或PaLM)不是多模态的,还不能生成可靠的事实陈述。
2.1 灵活的交互方式
GMAI为用户提供了通过自定义查询与模型交互的能力,使不同受众更容易理解人工智能见解,并在任务和设置方面提供了前所未有的灵活性。
在当前的实践中,人工智能模型通常处理一组狭窄的任务,并产生一组严格的、预先确定的输出。例如,当前的模型可能会检测到一种特定的疾病,接收一种图像并始终输出该疾病的可能性。相比之下,自定义查询允许用户随时提出问题:“解释一下头部MRI扫描上出现的肿块。它更可能是肿瘤还是脓肿?”。此外,查询允许用户自定义其输出的格式:“这是胶质母细胞瘤患者的后续MRI扫描。用红色标出任何肿瘤”。
自定义查询将启用两个关键功能——动态任务规范和多模式输入和输出,如下所示。
2.1.1 动态任务规范(Dynamic Task Specification)
自定义查询可以教会AI模型动态解决新问题,动态指定新任务,而不需要对模型进行重新训练。
例如,GMAI可以回答高度具体、以前从未见过的问题:“根据这项超声波,胆囊壁的厚度是多少毫米?”。不出所料,GMAI模型可能难以完成涉及未知概念或病理学的新任务。然后,在上下文学习中,用户可以通过几个例子向GMAI教授一个新概念:“以下是10名患有新发疾病的患者的病史,即 Langya henipavirus 感染。我们目前的患者也感染 Langya henibavirus的可能性有多大?”。
2.1.2 多模态输入输出(Multimodal Inputs and Outputs)
自定义查询允许用户在问题中包含复杂的医疗信息,自由混合模式。例如,临床医生在要求诊断时,可能会在查询中包含多张图像和实验室结果。
GMAI模型还可以灵活地将不同的模式整合到响应中,例如当用户同时要求文本答案和相应的可视化时。遵循Gato等先前的模型,GMAI模型可以通过将每种模态的数据转换为“令牌(tokens)”来组合模态,每个令牌代表一个可以跨模态组合的小单元(例如,句子中的单词或图像中的补丁)。
然后,可以将这种混合的令牌流馈入变压器架构,使GMAI模型能够整合给定患者的整个病史,包括报告、波形信号、实验室结果、基因组图谱和成像研究。
2.2 医学领域知识
与临床医生形成鲜明对比的是,传统的医学人工智能模型在接受特定任务的训练之前,通常缺乏医学领域的先验知识。相反,他们必须完全依赖输入数据的特征和预测目标之间的统计关联,而没有上下文信息(例如,关于病理生理过程)。这种缺乏背景的情况使得为特定的医疗任务训练模型变得更加困难,特别是在任务数据稀缺的情况下。
GMAI模型可以通过形式化表示医学知识来解决这些缺点。例如,知识图等结构可以让模型对医学概念及其之间的关系进行推理。此外,在最近基于检索的方法的基础上,GMAI可以从现有数据库中检索相关上下文,以文章、图像或整个先前案例的形式。由此产生的模型可以提出不言自明的警告:“这名患者可能会患上急性呼吸窘迫综合征,因为该患者最近因严重的胸部创伤入院,而且尽管吸入的氧气分数增加,但患者动脉血中的氧气分压仍在稳步下降”。
尽管GMAI模型主要基于观测数据进行训练,但它甚至可能被要求提供治疗建议,因此该模型推断和利用医学概念与临床发现之间因果关系的能力将在临床适用性方面发挥关键作用。
最后,通过获取丰富的分子和临床知识,GMAI模型可以通过利用相关问题的知识来解决数据有限的任务,例如基于人工智能的药物再利用的初步工作。
2.3 GMAI 的潜在应用场景
我们提出了针对不同用户群和学科的GMAI的六个潜在用例,尽管我们的列表并不详尽。尽管人工智能已经在这些领域做出了努力,但我们预计GMAI将为每个问题提供全面的解决方案。
2.3.1 基础放射学报告
GMAI支持新一代多功能数字放射学助理,在放射科医生的整个工作流程中为其提供支持,并显著减少工作量。GMAI模型可以自动起草放射学报告,描述异常和相关的正常发现,同时考虑到患者的病史。
这些模型可以通过将文本报告与交互式可视化配对,例如突出显示每个短语描述的区域,为临床医生提供进一步的帮助。
放射科医生还可以通过与GMAI模型聊天来提高对病例的理解:“你能突出显示之前图像中没有的任何新的多发性硬化症病变吗?”。
解决方案需要准确地解释各种放射学模式,甚至注意到细微的异常。
此外,在描述图像时,它必须整合患者病史的信息,包括指征、实验室结果和以前的图像等来源。
它还需要使用多种方式与临床医生沟通,提供文本答案和动态注释图像。
为此,它必须具备视觉基础,准确指出图像的哪个部分支持任何陈述。尽管这可以通过对专家标记的图像进行监督学习来实现,但Grad CAM等可解释性方法可以实现自我监督方法,不需要标记数据。
2.3.2 增强手术程序
我们预计一种手术GMAI模型可以帮助手术团队进行手术:“我们找不到肠道破裂。检查我们是否在最后15分钟的视觉反馈中错过了任何肠道切片的视图”。GMAI模型可以执行可视化任务,可能实时注释手术的视频流。他们也可能以口头形式提供信息,例如在跳过手术步骤时发出警报,或者在外科医生遇到罕见的解剖现象时阅读相关文献。
该模型还可以辅助手术室外的手术,如内窥镜手术。一个利用解剖学知识捕捉地形背景和原因的模型可以得出关于以前看不见的现象的结论。例如,可以推断,十二指肠镜检查中出现的大血管结构可能表明存在主动脉十二指肠瘘(即主动脉和小肠之间的异常连接),尽管以前从未遇到过(图2,右图)。GMAI可以通过首先检测血管,其次识别解剖位置,最后考虑邻近结构来解决这一任务。
解决方案需要整合视觉、语言和音频模式,使用视觉-音频-语言模型接受口头查询,并使用视觉提要执行任务。愿景-语言模型已经获得了广泛的关注,而开发包含更多模式的模型只是时间问题。这些方法可以建立在之前的工作基础上,将语言模型和知识图结合起来,逐步推理手术任务。此外,在手术环境中部署的GMAI可能会面临异常的临床现象,这些现象在模型开发过程中无法被包括在内,因为它们很罕见,这是一个被称为“看不见的条件的长尾”的挑战。
医学推理能力对于检测以前看不见的异常值和解释它们至关重要,如图2所示。
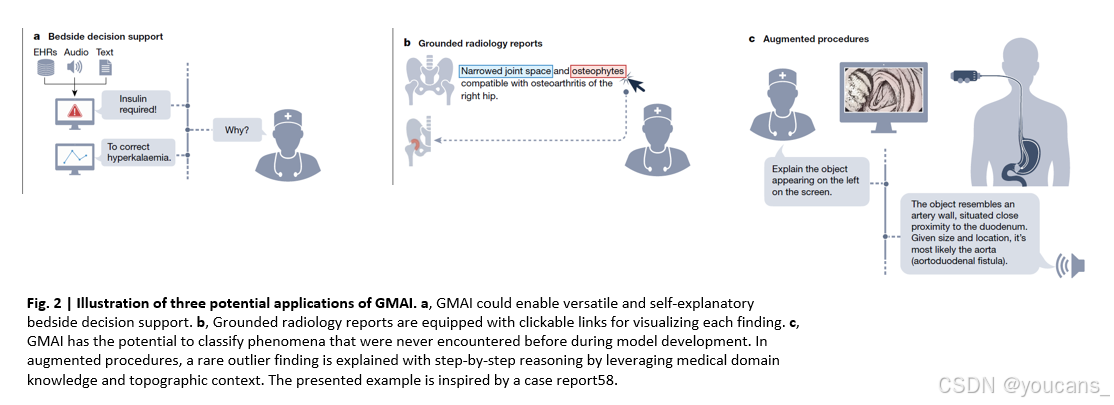
2.3.3 临床决策支持
GMAI开启了一种新型临床决策支持工具,这些工具扩展了现有的基于AI的早期预警系统,为未来的护理提供了更详细的解释和建议。
例如,用于临床决策支持的GMAI模型可以利用临床知识,提供自由文本解释和数据摘要:“警告:该患者即将进入休克状态。她的循环在过去15分钟已经不稳定 <链接到数据摘要>。建议的下一步措施:<链接到检查清单>”。
解决方案需要解析多模态的电子健康记录(EHR)资源,如生命体征、实验室参数及临床笔记等,包括文本和数字时间序列数据。它需要能从原始数据中总结出患者当前的状态,预测患者未来的可能状况,并提出治疗决策建议。该解决方案可以通过使用语言模型技术,根据他们之前的数据预测患者未来的文本和数字记录,从而预测患者的病情如何随时间变化。训练数据集可专门将 EHR时间序列数据与患者的最终结果配对,这些结果可以从出院报告和国际疾病分类(ICD)代码中收集。
此外,模型必须能够比较潜在治疗方案并估计其效果,同时遵循治疗指南和其他相关政策。模型可以通过临床知识图谱和学术文本等资源(如学术出版物、教育教科书、国际指南和当地政策)获取必要的知识。
这方面可能类似于 REALM 的发展方向。REALM是一种语言模型,通过首先检索单个相关文档,然后从中提取答案来回答查询,使用户能够识别每个答案的确切来源。
2.3.4 交互式笔记记录
文档记录是临床工作流程中不可或缺但劳动密集型的一部分。通过监测电子患者信息以及临床医生与患者的对话,GMAI模型将预先起草电子笔记和出院报告等文件,使临床医生只需进行审阅、编辑和批准。因此,GMAI能显著减少行政开销,使临床医生能够花更多时间与病人交流。
GMAI 解决方案可以借鉴语音转文本模型的最新进展,这些模型专门用于医疗应用。它必须准确地解释语音信号,理解医学术语和缩写。此外,它必须将语音数据与电子健康记录(EHR)中的信息(例如诊断列表、生命体征参数和之前的出院报告)结合起来,然后生成自由文本注释或报告。在记录与患者的任何互动之前,必须获取同意书。在大量收集录音之前,可以通过使用从聊天应用中收集的临床医生与病人的互动数据来开发早期的笔记模型。
2.3.5 患者聊天机器人
GMAI 很有潜力为患者支持的新应用程序提供动力,即使在临床环境之外也能提供高质量的护理。
例如,GMAI可以使用多种方式构建患者病情的整体视图,从症状的非结构化描述到连续的葡萄糖监测仪读数,再到患者提供的药物记录。在解释了这些异构类型的数据后,GMAI模型可以与患者互动,提供详细的建议和解释。重要的是,GMAI能够实现无障碍沟通,为患者的日程安排提供清晰、可读或可听的信息。
尽管目前类似的应用程序依赖于临床医生提供个性化支持,但GMAI 可以减少甚至消除对人类专家干预的需求,使应用程序在更大范围内可用。与现有的实时聊天应用程序一样,用户仍然可以根据要求与人类顾问互动。
使用GMAI构建面向患者的聊天机器人带来了两个特殊的挑战。
首先,面向患者的模型必须能够使用简单、清晰的语言与非技术受众进行清晰的沟通,而不会牺牲内容的准确性。在训练数据集中包含以患者为中心的医学文本可能会实现这一功能。
其次,这些模型需要处理患者收集的各种数据。患者提供的数据可能代表不寻常的模式;例如,有严格饮食要求的患者可以提交他们用餐前后的照片,这样GMAI模型就可以自动监测他们的食物摄入量。与来自临床环境的数据相比,患者收集的数据也可能更嘈杂,因为患者在收集数据时可能更容易出错或使用不太可靠的设备。同样,将相关数据纳入培训可以帮助克服这一挑战。
此外,GMAI模型还需要监测自身的不确定性,并在没有足够可靠的数据时采取适当的行动。
2.3.6 文本到蛋白质生成
GMAI 可以根据文本提示生成蛋白质氨基酸序列及其三维结构。
受现有蛋白质序列生成模型的启发,这种模型可以根据所需的功能特性来生成蛋白质序列。相比之下,生物医学知识渊博的GMAI 模型可以提供 蛋白质设计界面,具有当前流行的文本到图像生成模型那样的灵活性和易用性,如Stable Diffusion或DALL-E。此外,通过解锁上下文学习能力,基于GMAI的文本到蛋白质模型可以通过与序列配对的少数示例指令来提示,以动态定义新的生成任务,例如生成与指定靶标高度亲和力结合的蛋白质,同时满足额外的约束。
早期已有的尝试是开发生物序列的基础模型,包括RFdiffusion,它根据简单的规格(例如结合靶点)生成蛋白质。基于这项工作,基于GMAI的解决方案可以在训练过程中结合语言和蛋白质序列数据,提供一个多功能的文本界面。解决方案还可以借鉴多模态人工智能(如CLIP)的最新进展,在CLIP中,模型在不同模态的配对数据上进行联合训练。在创建这样的训练数据集时,单个蛋白质序列必须与描述蛋白质特性的相关文本段落(例如,来自生物学文献的文本段落)配对。像UniProt这样的大型项目,可以为数百万种蛋白质绘制蛋白质功能图,对于这项工作至关重要。
3. GMAI 的机遇与挑战
GMAI 有可能通过改善护理和减少临床医生倦怠来影响医疗实践。在这里,我们详细介绍了GMAI模型的总体优势。我们还描述了必须解决的关键挑战,以确保安全部署,因为与其他领域的基础模型相比,GMAI模型将在特别高的风险环境中运行。
3.1 GMAI 范式的转变
3.1.1 可控性
GMAI允许用户精细控制其输出的格式,使复杂的医疗信息更容易访问和理解。例如,将有GMAI模型可以根据要求重新表述自然语言回复。同样,GMAI提供的可视化可以精心定制,例如通过改变视点或用文本标记重要特征。模型还可以潜在地调整其输出中特定于领域的细节水平,或将其翻译成多种语言,与不同的用户进行有效的沟通。最后,GMAI的灵活性使其能够根据当地习俗和政策适应特定地区或医院。用户可能需要关于如何查询GMAI模型并最有效地使用其输出的正式指导。
3.1.2 适应性
现有的医学人工智能模型难以应对分布变化,在这种变化中,数据的分布会因技术、程序、环境或人群的变化而发生变化。
然而,GMAI可以通过情境学习跟上变化的步伐。例如,医院可以教GMAI模型解释来自全新扫描仪的X射线,只需提供显示一小部分示例的提示即可。因此,GMAI可以动态适应新的数据分布,而传统的医学AI模型需要在全新的数据集上重新训练。
目前,情境学习主要在大型语言模型中观察到。为了确保 GMAI 能够适应环境的变化,GMAI模型骨干需要接受来自多个互补来源和模式的极其多样化的数据的培训。例如,为了适应2019冠状病毒病的新变种,一个成功的模型可以检索过去变种的特征,并在查询中遇到新的上下文时进行更新。例如,临床医生可能会说,“检查这些胸部X光片是否有奥密克戎肺炎。与德尔塔变异株相比,将支气管和血管周围的浸润视为指示标志”。
尽管用户可以通过提示手动调整模型行为,但新技术也可能自动纳入人类反馈。例如,用户可以对GMAI模型的每个输出进行评分或评论,就像用户对人工智能聊天界面ChatGPT(由OpenAI于2022年发布)的输出进行评分一样。然后,可以按照InstructGPT的例子,使用这种反馈来改善模型行为,InstructGPP是一个通过使用人类反馈通过强化学习来改进GPT-3而创建的模型。
3.1.3 适用性
大规模人工智能模型已经成为众多下游应用的基础。
例如,在发布后的几个月内,GPT-3为各行各业的300多个应用程序提供了支持。作为医学基础模型的一个有前景的早期例子,CheXzero可以应用于检测胸部X射线中的数十种疾病,而无需对这些疾病的明确标签进行训练。
同样,向GMAI的转变将推动具有广泛功能的大规模医疗人工智能模型的开发和发布,这将为各种下游临床应用奠定基础。许多应用程序将直接使用其最终输出与GMAI模型本身进行交互。其他人可能会使用GMAI模型在产生输出的过程中自然生成的中间数值表示,作为可以为特定任务廉价构建的小型专业模型的输入。
然而,这种灵活的适用性可能是一把双刃剑,因为基础模型中存在的任何故障模式都会在整个下游应用程序中广泛传播。
3.2 GMAI 的挑战
3.2.1 验证难度大
由于其前所未有的多功能性,GMAI模型将特别难以验证。
目前,人工智能模型是为特定任务设计的,因此它们只需要针对那些预先定义的用例进行验证(例如,通过大脑MRI诊断特定类型的癌症)。然而,GMAI模型可以执行最终用户首次提出的以前看不见的任务(例如,诊断大脑MRI中的任何疾病),因此预测其所有故障模式无疑更具挑战性。开发人员和监管机构将负责解释GMAI模型是如何进行测试的,以及它们被批准用于哪些用例。
GMAI界面本身的设计应该是在进入未知领域时发出“标签外使用”警告,而不是自信地制造不准确的信息。更一般地说,GMAI独特的广泛能力需要监管远见,要求机构和政府政策适应新的范式,并将重塑保险安排和责任分配。
3.2.2 验证结果困难
与传统的人工智能模型相比,GMAI模型可以处理异常复杂的输入和输出,这使得临床医生更难确定其正确性。
例如,当对患者的癌症进行分类时,传统模型可能只考虑成像研究或全滑动图像。在每种情况下,只有一名放射科医生或病理学家可以验证模型的输出是否正确。然而,GMAI模型可能会考虑这两种输入,并可能输出初始分类、治疗建议和涉及可视化、统计分析和文献参考的多模态论证。在这种情况下,可能需要一个多学科小组(由放射科医生、病理学家、肿瘤学家和其他专家组成)来判断GMAI的输出。因此,无论是在验证过程中还是在模型部署后,对GMAI输出进行事实核查都是一项严峻的挑战。
开发者可以通过结合可解释性技术来更容易地验证GMAI输出。
例如,GMAI的输出可能包括指向文献中支持段落的可点击链接,使临床医生能够更有效地验证GMAI预测。最近提出了在没有人类专业知识的情况下对模型输出进行事实检查的其他策略。
最后,至关重要的是,GMAI模型需要准确地表达不确定性,从而从一开始就防止了过度自信的陈述。
3.2.3 样本偏差的风险
注:原文为 “社会偏见”,但此处“偏见”不是主管的偏见,而是训练集样本的偏差导致模型对少数人群的泛化性能问题。
之前的研究已经表明,医学人工智能模型会使偏见永久化,从而对边缘化人群造成伤害。
当数据集要么低估了某些患者群体,要么包含有害的相关性时,他们可能会在训练过程中产生偏见。在开发GMAI时,这些风险可能会更加明显。必要训练数据集前所未有的规模和复杂性将使其难以确保没有不希望的偏差。尽管偏见已经对健康领域的传统人工智能构成了挑战,但它们与GMAI特别相关,因为最近的一项大规模评估表明,社会偏见会随着模型规模的增加而增加。
GMAI模型必须经过彻底验证,以确保它们不会在少数群体等特定人群中表现不佳。此外,即使在部署后,模型也需要进行持续的审计和监管,因为随着模型遇到新的任务和设置,会出现新的问题。有奖竞赛可以激励人工智能社区进一步审查GMAI模型。例如,参与者可能会因为发现产生有害内容或暴露其他失败模式的提示而获得奖励。
快速识别和修复偏见必须是开发人员、供应商和监管机构的首要任务。
3.2.4 隐私风险高
GMAI模型的开发和使用对患者隐私构成了严重风险。GMAI模型可以访问一组丰富的患者特征,包括临床测量和信号、分子特征和人口统计信息,以及行为和感觉跟踪数据。此外,GMAI模型可能会使用大型架构,但更大的模型更容易记忆训练数据并直接向用户重复。因此,GMAI模型可能会在训练数据集中暴露敏感的患者数据,这是一个严重的风险。通过去标识和限制为个体患者收集的信息量,可以减少暴露数据造成的损害。
然而,隐私问题不仅限于训练数据,因为部署的GMAI模型也可能暴露当前患者的数据。即时攻击可以欺骗GPT-3等模型忽略之前的指令。例如,想象一下,GMAI模型被指示永远不要向未经认证的用户透露患者信息。恶意用户可以迫使模型忽略提取敏感数据的指令。
3.2.5 大模型的成本很高
最近的基础模型的规模显著增加,推高了与数据收集和模型训练相关的成本。这种规模的模型需要大量的训练数据集,就GPT-3而言,这些数据集包含数千亿个代币,收集起来很昂贵。此外,谷歌开发的5400亿参数模型PaLM需要大约840万小时的张量处理单元v4芯片进行训练,一次使用大约3000到6000个芯片,计算成本高达数百万美元。此外,开发如此大型的模型会带来巨大的环境成本,因为训练每个模型估计会产生高达数百吨的二氧化碳当量。
这些成本引发了一个问题,即数据集和模型应该有多大。最近的一项研究建立了数据集大小和模型大小之间的联系,建议使用比参数多20倍的令牌来获得最佳性能,但现有的基础模型是以较低的令牌与参数比率成功训练的。因此,在开发GMAI模型时,仍然很难估计模型和数据集必须有多大,特别是因为必要的规模在很大程度上取决于特定的医疗用例。
由于需要前所未有的大量医疗数据,数据收集将对GMAI的发展构成特别挑战。
现有的基础模型通常是在通过爬取网络获得的异构数据上进行训练的,这种通用数据源可能用于预训练GMAI模型(即进行初始准备轮训练)。尽管这些数据集并不侧重于医学,但这种预训练可以为GMAI模型提供有用的功能。例如,通过利用其训练数据集中的医学文本,Flan-PaLM或ChatGPT等通用模型可以准确地回答医学问题,在美国医学执照考试中取得及格分数。然而,GMAI模型开发可能还需要专门关注医学领域及其模式的大量数据集。这些数据集必须多样化、匿名化,并以兼容的格式组织,收集和共享数据的程序需要遵守跨机构和地区的异构政策。尽管收集如此庞大的数据集将构成重大挑战,但考虑到自我监督的成功,这些数据通常不需要昂贵的专家标签。此外,多模态自我监督技术可用于在多个数据集上训练模型,每个数据集包含来自几种模态的测量值,从而减少了对每个患者包含许多模态测量值的大型昂贵数据集的需求。换句话说,一个模型可以在一个包含EHR和MRI数据的数据集上进行训练,在另一个数据集上使用EHR和基因组数据进行训练,而不需要同时包含EHR、MRI和基因组数据的大型数据集。大规模数据共享工作,如MIMIC(重症监护医疗信息集市)数据库或英国生物库,将在GMAI中发挥关键作用,应将其扩展到代表性不足的国家,以创建更大、更丰富、更具包容性的培训数据集。
GMAI模型的规模也将带来技术挑战。除了培训成本高昂外,GMAI模型的部署也可能具有挑战性,需要专门的高端硬件,医院可能很难获得这些硬件。对于某些用例(例如聊天机器人),GMAI模型可以存储在由具有深厚技术专长的组织维护的中央计算集群上,就像DALL-E或GPT-3一样。然而,其他GMAI模型可能需要在医院或其他医疗环境中本地部署,从而消除了对稳定网络连接的需求,并将敏感的患者数据保存在现场。在这些情况下,可能需要通过知识蒸馏等技术来减小模型大小,在这些技术中,大规模模型教给更小的模型,这些模型可以在实际约束下更容易地部署
综上所述,GMAI技术的发展面临验证方法创新、结果判断协作、偏见风险关注、隐私保护挑战和开发成本高昂等五大挑战。应对这些挑战需要开发者、监管者、医疗专家和其他利益相关者的通力合作,制定严格的标准,完善评估和监管机制,确保GMAI模型的安全、可靠、公平和经济可行性。
4. 结论
基础模型具有彻底改变医疗行业的潜力。我们描述的高级基础模型类别GMAI 能够处理多种数据模式,实时学习新任务并利用领域知识,,几乎能应用于所有医疗任务。GMAI的灵活性使模型能够在新环境中保持相关性,并跟上新兴疾病和技术的步伐,而无需不断从头开始重新训练。基于GMAI的应用程序将部署在传统的临床环境和智能手机等远程设备上,我们预测它们将对不同的受众有用,实现面向临床医生和面向患者的应用程序。
但是,GMAI模型也面临诸多挑战。它们的极多功能性使得它们难以全面验证,而且模型的规模可能会增加计算成本。数据收集和访问将特别困难,因为GMAI的培训数据集不仅必须庞大,而且必须多样化,并有足够的隐私保护。我们呼吁人工智能社区和临床利益相关者尽早仔细考虑这些挑战,以确保GMAI始终如一地提供临床价值。
最终,GMAI将为医疗行业提供前所未有的可能性,在一系列基本任务中为临床医生提供支持,克服沟通障碍,更容易提供高质量的护理,并减轻临床医生的行政负担,从而让他们有更多时间关注患者。
6. 参考文献
- Bommasani, R. et al. On the opportunities and risks of foundation models. Preprint at https://arxiv.org/abs/2108.07258 (2022).
- Reed, S. et al. A generalist agent. In Transactions on Machine Learning Research (2022). This study presented Gato, a generalist model that can carry out a variety of tasks across modalities such as chatting, captioning images, playing video games and controlling a robot arm.
- Alayrac, J.-B. et al. Flamingo: a Visual Language Model for few-shot learning. In Advances in Neural Information Processing Systems (eds Oh, A. H. et al.) 35, 23716–23736 (2022).
- Lu, J., Clark, C., Zellers, R., Mottaghi, R. & Kembhavi, A. Unified-IO: a unified model for vision, language, and multi-modal tasks. Preprint at https://arxiv.org/abs/2206.08916 (2022).
- Brown, T. et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems (eds Larochelle, H. et al.) 33, 1877–1901 (2020). This study presented the language model GPT-3 and discovered that large language models can carry out in-context learning.
- Aghajanyan, A. et al. CM3: a causal masked multimodal model of the Internet. Preprint at https://arxiv.org/abs/2201.07520 (2022).
- Wei, J. et al. Emergent abilities of large language models. In Transactions on Machine Learning Research (2022).
- Steinberg, E. et al. Language models are an effective representation learning technique for electronic health record data. J. Biomed. Inform. 113, 103637 (2021).
- Tiu, E. et al. Expert-level detection of pathologies from unannotated chest X-ray images via self-supervised learning. Nat. Biomed. Eng. 6, 1399–1406 (2022). This study demonstrated that CheXzero—an early example of a foundation model in medical AI—can detect diseases on chest X-rays without explicit annotation by learning from natural-language descriptions contained in accompanying clinical reports.
- Singhal, K. et al. Large language models encode clinical knowledge. Preprint at https://arxiv.org/abs/2212.13138 (2022). This study demonstrated that the language model Flan-PaLM achieves a passing score (67.6%) on a dataset of US Medical Licensing Examination questions and proposed Med-PaLM, a medical variant of Flan-PaLM with improved clinical reasoning and comprehension.
- Yang, X. et al. A large language model for electronic health records. npj Digit. Med. 5, 194 (2022).
- Food and Drug Administration. Artificial intelligence and machine learning (AI/ML)-enabled medical devices. FDA https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-and-machine-learning-aiml-enabled-medical-devices (2022).
- Acosta, J. N., Falcone, G. J., Rajpurkar, P. & Topol, E. J. Multimodal biomedical AI. Nat. Med. 28, 1773–1784 (2022).
- Krishnan, R., Rajpurkar, P. & Topol, E. J. Self-supervised learning in medicine and healthcare. Nat. Biomed. Eng. 6, 1346–1352 (2022).
- Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding. In Proc. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (eds Burstein, J., Doran, C. & Solorio, T.) 1, 4171–4186 (2019). This paper introduced masked language modelling, a widely used technique for training language models where parts of a text sequence are hidden (masked) in order for the model to fill in the blanks. This strategy can be extended beyond text to other data types.
- Radford, A. et al. Learning transferable visual models from natural language supervision. In Proc. 38th Int. Conference on Machine Learning (eds Meila, M. & Zhang, T.) 139, 8748–8763 (2021). This paper introduced contrastive language–image pretraining (CLIP), a multimodal approach that enabled a model to learn from images paired with raw text.
- Zhang, X.-A. et al. A zoonotic henipavirus in febrile patients in China. N. Engl. J. Med. 387, 470–472 (2022).
- Vaswani, A. et al. Attention is all you need. In Advances in Neural Information Processing Systems (eds Guyon, I. et al.) 30, 5998–6008 (2017). This paper introduced the transformer architecture, a key breakthrough that ultimately led to the development of large-scale foundation models.
- Borgeaud, S. et al. Improving language models by retrieving from trillions of tokens. In Proc. 39th Int. Conference on Machine Learning (eds Chaudhuri, K. et al.) 162, 2206–2240 (2022).
- Guu, K., Lee, K., Tung, Z., Pasupat, P. & Chang, M.-W. REALM: retrieval-augmented language model pre-training. In Proc. 37th Int. Conference on Machine Learning (eds Daumé, H. & Singh, A.) 119, 3929–3938 (2020).
- Igelström, E. et al. Causal inference and effect estimation using observational data. J. Epidemiol. Community Health 76, 960–966 (2022).
- Wang, Q., Huang, K., Chandak, P., Zitnik, M. & Gehlenborg, N. Extending the nested model for user-centric XAI: a design study on GNN-based drug repurposing. IEEE Trans. Vis. Comput. Graph. 29, 1266–1276 (2023).
- Li, J. et al. Align before fuse: vision and language representation learning with momentum distillation. In Advances in Neural Information Processing Systems (eds Ranzato, M. et al.) 34, 9694–9705 (2021).
- Wang, Z. et al. SimVLM: simple visual language model pretraining with weak supervision. In Int. Conference on Learning Representations (eds Hofmann, K. & Rush, A.) (2022).
- Yasunaga, M. et al. Deep bidirectional language-knowledge graph pretraining. In Advances in Neural Information Processing Systems (eds Oh, A. H. et al.) 35 (2022).
- Yasunaga, M., Ren, H., Bosselut, A., Liang, P. & Leskovec, J. QA-GNN: reasoning with language models and knowledge graphs for question answering. In Proc. 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (eds Toutanova, K. et al.) 535–546 (2021).
- Guha Roy, A. et al. Does your dermatology classifier know what it doesn’t know? Detecting the long-tail of unseen conditions. Med. Image Anal. 75, 102274 (2022).
- Radford, A. et al. Robust speech recognition via large-scale weak supervision. Preprint at https://arxiv.org/abs/2212.04356 (2022).
- Dixon, R. F. et al. A virtual type 2 diabetes clinic using continuous glucose monitoring and endocrinology visits. J. Diabetes Sci. Technol. 14, 908–911 (2020).
- Kucera, T., Togninalli, M. & Meng-Papaxanthos, L. Conditional generative modeling for de novo protein design with hierarchical functions. Bioinformatics 38, 3454–3461 (2022).
- Rombach, R., Blattmann, A., Lorenz, D., Esser, P. & Ommer, B. High-resolution image synthesis with latent diffusion models. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (eds Chellappa, R. et al.) 10684–10695 (2022).
- Ramesh, A. et al. Zero-shot text-to-image generation. In Proc. 38th Int. Conference on Machine Learning (eds Meila, M. & Zhang, T.) 139, 8821–8831 (2021).
- Jumper, J. et al. Highly accurate protein structure prediction with AlphaFold. Nature 596, 583–589 (2021).
- Zvyagin, M. et al. GenSLMs: genome-scale language models reveal SARS-CoV-2 evolutionary dynamics. Preprint at bioRxiv https://doi.org/10.1101/2022.10.10.511571 (2022).
- Watson, J. L. et al. Broadly applicable and accurate protein design by integrating structure prediction networks and diffusion generative models. Preprint at bioRxiv https://doi.org/10.1101/2022.12.09.519842 (2022).
- The UniProt Consortium. UniProt: the universal protein knowledgebase. Nucleic Acids Res. 45, D158–D169 (2017).
- Guo, L. L. et al. Systematic review of approaches to preserve machine learning performance in the presence of temporal dataset shift in clinical medicine. Appl. Clin. Inform. 12, 808–815 (2021).
- Finlayson, S. G. et al. The clinician and dataset shift in artificial intelligence. N. Engl. J. Med. 385, 283–286 (2021).
- Lampinen, A. K. et al. Can language models learn from explanations in context? In Findings of the Association for Computational Linguistics: EMNLP 2022 (eds Goldberg, Y., Kozareva, Z. & Zhang, Y.) 537–563 (2022).
- Yoon, S. H., Lee, J. H. & Kim, B.-N. Chest CT findings in hospitalized patients with SARS-CoV-2: Delta versus Omicron variants. Radiology 306, 252–260 (2023).
- Ouyang, L. et al. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems (eds Oh, A. H. et al.) 35, 27730–27744 (2022).
- Pilipiszyn, A. GPT-3 powers the next generation of apps. OpenAI https://openai.com/blog/gpt-3-apps/ (2021).
- Burns, C., Ye, H., Klein, D. & Steinhardt, J. Discovering latent knowledge in language models without supervision. Preprint at https://arxiv.org/abs/2212.03827 (2022).
- Obermeyer, Z., Powers, B., Vogeli, C. & Mullainathan, S. Dissecting racial bias in an algorithm used to manage the health of populations. Science 366, 447–453 (2019).
- Sex and Gender Bias in Technology and Artificial Intelligence: Biomedicine and Healthcare Applications (Academic, 2022).
- Srivastava, A. et al. Beyond the imitation game: quantifying and extrapolating the capabilities of language models. Preprint at https://arxiv.org/abs/2206.04615 (2022).
- Carlini, N. et al. Extracting training data from large language models. In Proc. 30th USENIX Security Symposium (eds Bailey, M. & Greenstadt, R.) 6, 2633–2650 (2021).
- Branch, H. J. et al. Evaluating the susceptibility of pre-trained language models via handcrafted adversarial examples. Preprint at https://arxiv.org/abs/2209.02128 (2022).
- Chowdhery, A. et al. PaLM: scaling language modeling with pathways. Preprint at https://arxiv.org/abs/2204.02311 (2022).
- Zhang, S. et al. OPT: open pre-trained transformer language models. Preprint at https://arxiv.org/abs/2205.01068 (2022).
- Hoffmann, J. et al. An empirical analysis of compute-optimal large language model training. In Advances in Neural Information Processing Systems (eds Oh, A. H. et al.) 35, 30016–30030 (2022).
- Chung, H. W. et al. Scaling instruction-finetuned language models. Preprint at https://arxiv.org/abs/2210.11416 (2022).
- Kung, T. H. et al. Performance of ChatGPT on USMLE: potential for AI-assisted medical education using large language models. PLoS Dig. Health 2, 2 (2023).
- Huang, S.-C., Shen, L., Lungren, M. P. & Yeung, S. GLoRIA: a multimodal global-local representation learning framework for label-efficient medical image recognition. In Proc. IEEE/CVF Int. Conference on Computer Vision (eds Brown, M. S. et al.) 3942–3951 (2021).
- Johnson, A. E. W. et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci. Data 10, 1 (2023).
- Sudlow, C. et al. UK Biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS Med. 12, e1001779 (2015).
- Gou, J., Yu, B., Maybank, S. J. & Tao, D. Knowledge distillation: a survey. Int. J. Comput. Vis. 129, 1789–1819 (2021).
- Vegunta, R., Vegunta, R. & Kutti Sridharan, G. Secondary aortoduodenal fistula presenting as gastrointestinal bleeding and fungemia. Cureus 11, e5575 (2019).
版权说明:
本文由 youcans@xidian 对论文 Foundation models for generalist medical artificial intelligence 进行摘编和翻译。该论文版权属于原文期刊和作者,本译文只供研究学习使用。
youcans@xidian 作品,转载必须标注原文链接:
【医学影像 AI】医学通用人工智能的基础模型 (https://youcans.blog.csdn.net/article/details/145465862)
Crated:2025-02


















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











