








论文阅读-VSA: Learning Varied-Size Window Attention in Vision Transformers
写在看前
大概看了一下公式,感觉这样操作,和学习卷积核大小类似。有一个疑惑:用一个回归模块预测你的窗口大小很简单,问题是这一个操作是不可导的,咋办?
Motivation
摘要
- 固定窗口长度的self-attention不能够捕捉长距离依赖,capacity不够。
Intro
- 老生常谈,SA空间二次方,高分辨率就萎了。因此诞生了窗SA。
- 经验主义地确定窗口长度是次优的。因为,物体的大小是变化的——多层堆叠只能部分解决这个问题,但是不够完美,因为同时又带来了优化困难和参数增加的问题。
看了之后
看了半天,基本还是base在一个default的窗的基础上操作的,如:
- Quary是基于default的窗产生的;
- S, O(控制窗口的参数),是由default的窗池化之后送进某个回归模块产生的。
但是还是没懂:
3. 不可导的部分怎么办
4. 基于一个default的窗产生可变的窗,那不是想当于插值卷积核大小?这个效果能有多好?
论文阅读-CVPR2021-Involution: Inverting the Inherence of Convolution for Visual Recognition
Methedology
此篇之前看过,因此直接来到方法部分。
那个大图看不太懂,但是伪代码写得很一目了然。

在per-pixel dynamic卷积中,有一个要点,就是前馈时不直接使用nn.Conv2d的forward,而是用nn.Conv2d的weight,然后结合nn.Unfold和mul,直接对展开的输入和权重做点乘操作。
这个实现中,在HW上使用动态权重的同时,还对C个channels使用共享权重。
维度变换过程大致如下(为简便,G=1):
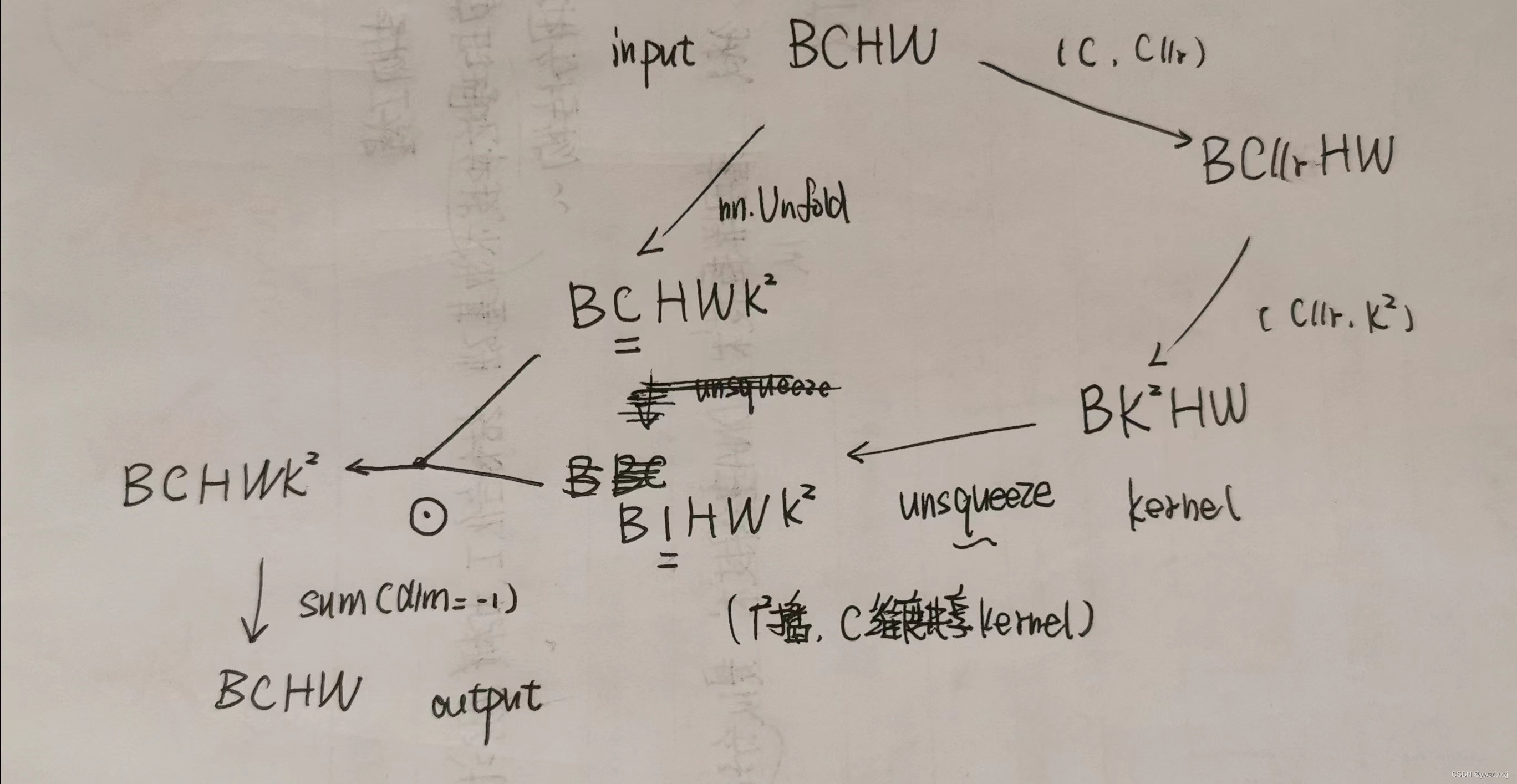
可见思路比较简单,直接就在C维度上,用
1
×
1
1\times1
1×1把
C
C
C变成了
K
2
K^{2}
K2。能否从通道到空间(核参数)直接这么变化呢?其实,WeightNet也有类似操作,GAP得到
B
×
C
×
1
×
1
B\times C\times 1 \times 1
B×C×1×1之后,直接从
C
C
C变换成类似
K
2
×
C
K^2\times C
K2×C的。感觉这么操作,凭空产生一个
K
2
K^{2}
K2,仅仅只是维度对应上了,暂时不是完全理解为啥能work,比较神奇。
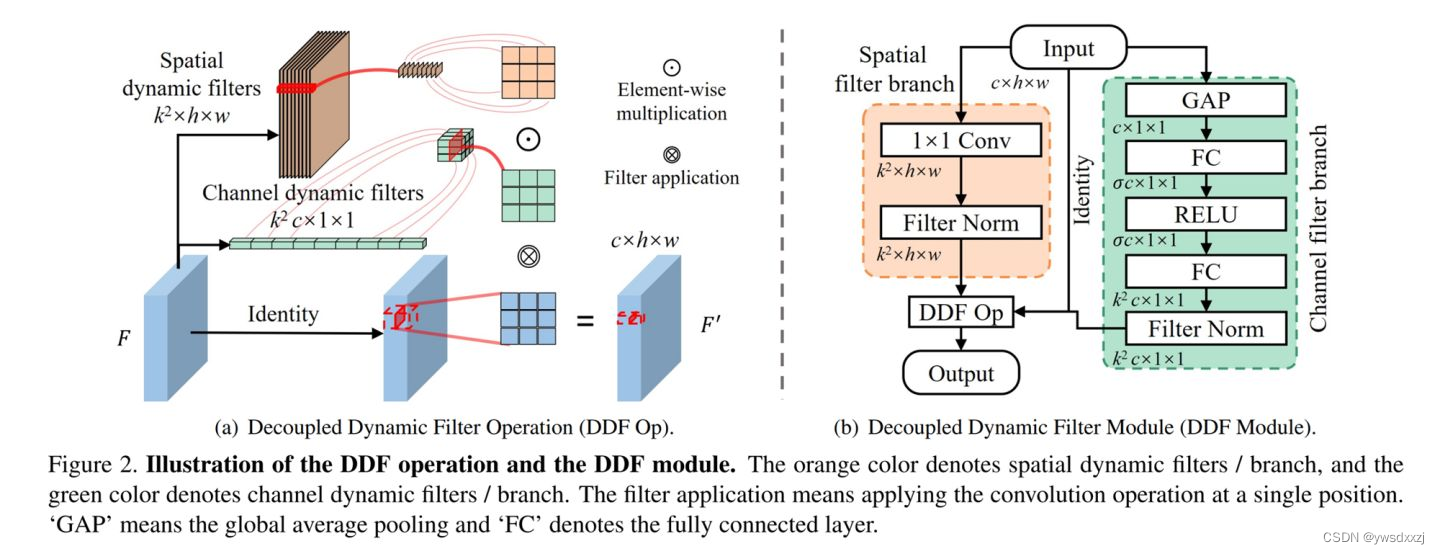
论文阅读-CVPR2021-Decoupled dynamic filter networks
这篇大概看过,感觉和TVConv的思路一样,反正矩阵分解, A × B A \times B A×B变成 A × r A \times r A×r和 r × B r \times B r×B,参数就变成了 r ( A + B ) A B \frac{r(A+B)}{AB} ABr(A+B)。用的时候再用矩阵乘法乘回去——低秩,一般不影响结果,毕竟还可以在别的地方怼上非线性和过参数。
具体来说:
- TVConv把 H W HW HW和 C C C分离, H W × r HW\times r HW×r部分做成输入了,learnable的参数矩阵; C × r C\times r C×r的部分做成非线性的了,三层卷积。
- 目的同是per-pixel。此篇也是分离 H W HW HW和 C C C,但是两部分都来自于输入。 H W × K 2 HW \times K^2 HW×K2的部分由输入经过Spatial Filter Branch得到,和上一篇Involution那个我搞不懂的 C C C直接变成 K 2 K^2 K2就如出一辙,具体结构就是1x1卷积(我靠,居然还是线性的)加一个神奇的归一化层; C × K 2 C \times K^2 C×K2的部分由两层FC得到,也有一个神奇归一化层。
总体来看,做得比较轻量级。外加的这个模块全都拆开了,实际上没多少参数增加。有意思的是,重复处理了
K
2
K^2
K2这个维度——然而最后为了得到
B
C
H
W
K
2
BCHWK^2
BCHWK2,
K
2
K^2
K2这个维度上实际上做的是点积,没有求和,因此在
K
2
K^2
K2维度上的表达复杂度应该是够的。不过这个
K
2
×
H
×
W
K^2\times H \times W
K2×H×W甚至在空间
H
W
HW
HW上完全没有变,还是有一点奇怪的。















 1067
1067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









