







 超级会员免费看
超级会员免费看
为了增强模型的任务解决能力,大语言模型在预训练之后需要进行适应性微调,通常涉及两个主要步骤,即指令微调(有监督微调)和对齐微调。
指令微调数据集
在预训练之后,指令微调(也称为有监督微调)是增强或激活大语言模型特定能力的重要方法之一(例如指令遵循能力)。本小节将介绍几个常用的指令微调数据集,并根据格式化指令实例的构建方法将它们分为三种主要类型,即自然语言处理任务数据集、日常对话数据集和合成数据集。
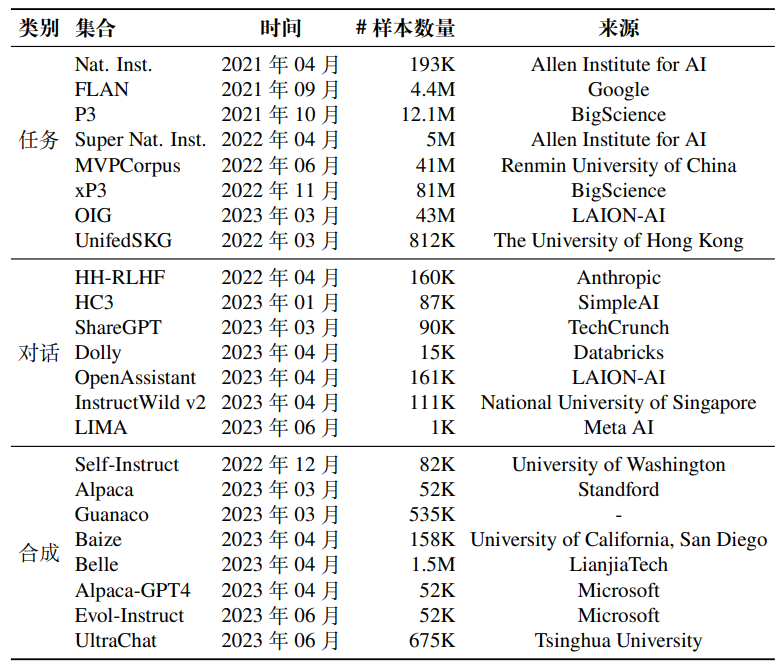
在指令微调被提出前,早期的研究通过收集不同自然语言处理任务(如文本分类和摘要等)的实例,创建了有监督的多任务训练数据集。这些多任务训练数据集成为了构建指令微调数据集的重要来源之一。一般的方法是使用人工编写的任务描述来扩充原始的多任务训练数据集,从而得到可以用于指令微调的自然语言处理任务数据集。其中,P3和 FLAN是两个代表性的基于自然语言处理任务的指令微调数据集。
P3(Public Pool of Prompts)是一个面向英文数据的指令微调数据集,由超过 270 个自然语言处理任务数据集和 2,000 多种提示整合而成(每个任务可能不止一种提示),全面涵盖多选问答、提取式问答、闭卷问答、情感分类、文本摘要、主题分类、自然语言推断等自然语言处理任务。P3 是通过 Pr

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 2322
2322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











