







乘法器系列:
- FPGA中有符号数的相乘
- FPGA中乘法器的流水线实现
- Vivado(复数)乘法器IP核的使用
一、Vivado乘法器IP核参数配置
参考文档:pg108
1.1 Basic
Multiplier Type:选择乘法器类型
- Parallel Multiplier:并行乘法器,即输入两个并行的变量
Multiplier Construction:选择该核的实现方式(LUT/专用乘数原语)
Optimization Options:选择优化方式(速度/资源)
- Constant Coefficient Multiplier:恒定系数乘法器,即输入一个变量和设定的常数相乘,选择该选项后配置界面如下:
Constant Value (Integer):恒定系数的整数值,可正可负
Memory Type:选择乘法器的内存类型(分布式RAM/块RAM/DSP片)
1.2 Output and Control
Use Custom Output Width:自定义输出宽度。如果只需要取输出的某些位,可以通过MSB和LSB进行设置
Pipeline Stages:选择流水线级数,可以看出该IP核是通过流水线实现乘法的
- Pipeline Stages = 0:表示核是组合的
- Pipeline Stages = 1:表示只寄存核输出
- Pipeline Stages > 1 :表示寄存器插入到输入和输出之间,直到最佳流水线级值
Clock Enable:加一个时钟使能控制端CE
Synchronous Clear:加一个同步复位控制端SCLR
SCLR/CE Priority:CE和CLR同时存在时,可以设置其优先级
二、乘法器IP核仿真结果
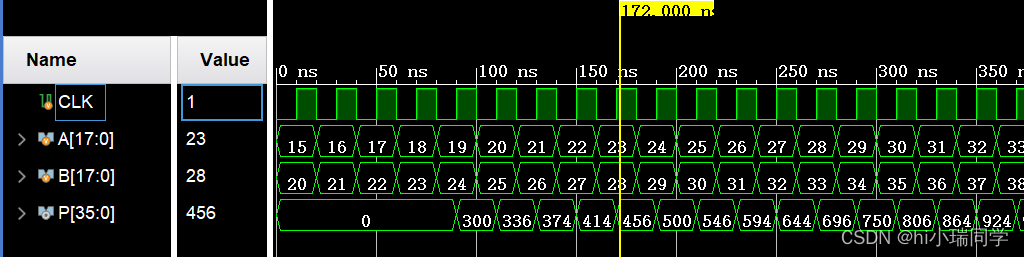
三、Vivado复数乘法器IP核参数配置
参考文档:pg104
AR/AI Operand Width:操作数宽度,默认为16,设为16时,s_axis_a_tdata结构如下图所示:

TLAST、TUSER、TUSER Width:和AXI-Stream有关
Flow Control Options:流控制选项
- 阻塞:阻塞意味着所有通道都有可用的数据之前不会执行操作
- 非阻塞:非阻塞意味着在一个通道上缺少数据,而在另一个通道上接收到数据时,不会阻塞操作的执行,此时AXI-Stream通道没有tready信号
Output Rounding:输出的舍入
- 截断
- 随机舍入选择:选择随机舍入时,启用CTRL通道。该通道的TDATA字段的第0位决定了操作数的特定类型的舍入
Core Latency:配置核延迟
- 自动:将延迟设置为使核心完全流水线化以获得最大性能
- 手动:允许用户选择最小延迟,当该值小于完全流水线延迟时,性能会下降
四、复数乘法器IP核仿真
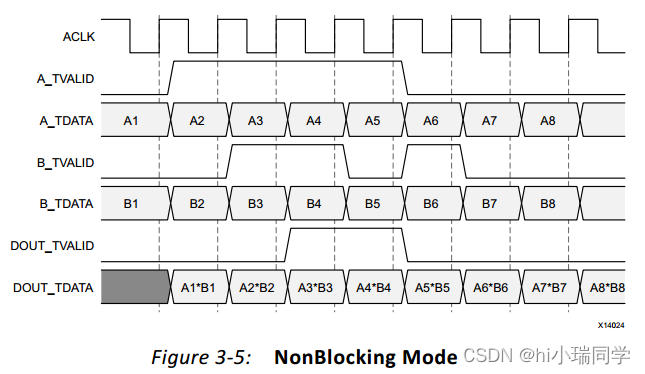
①非阻塞模式、资源优化:
非阻塞模式的时序图:
仿真结果:
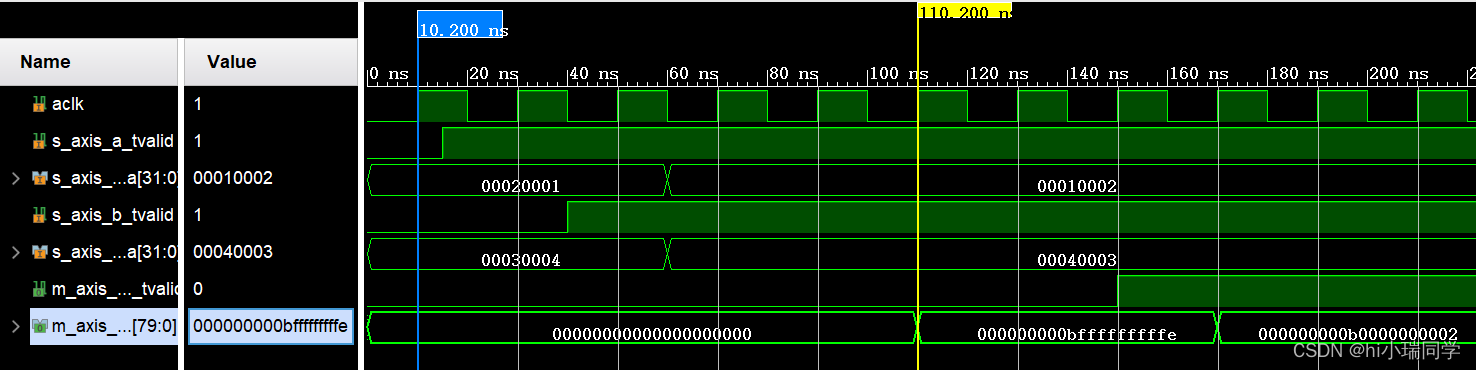
📄输出数据位宽为80是因为AXI-Stream接口要字节对齐,这样前40bit为输出虚部,后40bit为输出实部。
📄以16进制显示,输入数据分别为1+2j、4+3j和2+j、3+4j,结果应为-2+11j和2+11j。输出较输入滞后5个周期。而且输出并不受valid信号影响,输入有valid信号后,输出才会产生valid。
② 非阻塞模式、性能优化:
仿真结果:
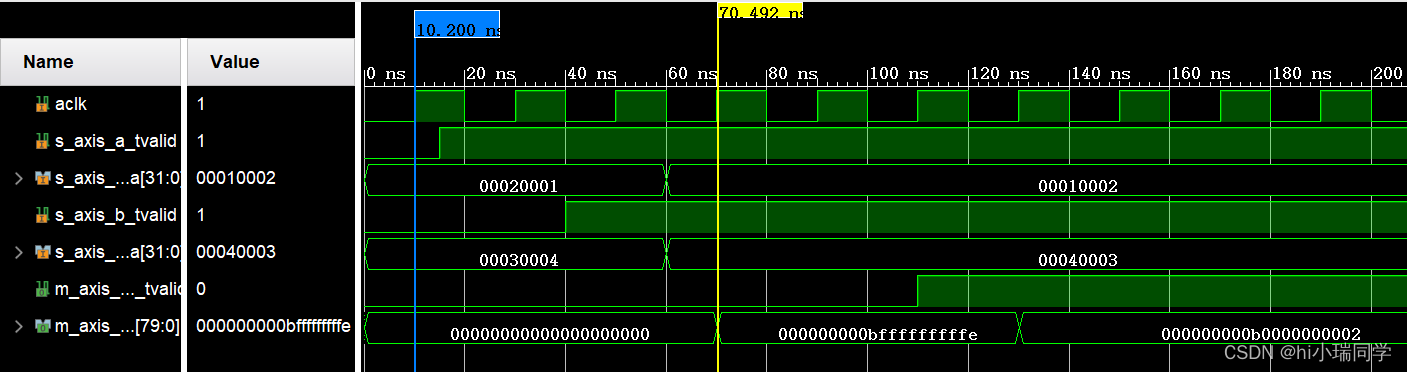
📄输出较输入滞后3个时钟周期。
③阻塞模式、性能优化:
说明:
1.所有通道都有新的有效数据之前不会执行操作。
2.tready信号为低时,数据会在输出缓冲区累积,从而不会更新。
3.当输入缓冲区满时,输入各自的tready被置0,以防止进一步输入。
4.tready信号为高时,输出为输入缓存区的数据执行操作后的结果。
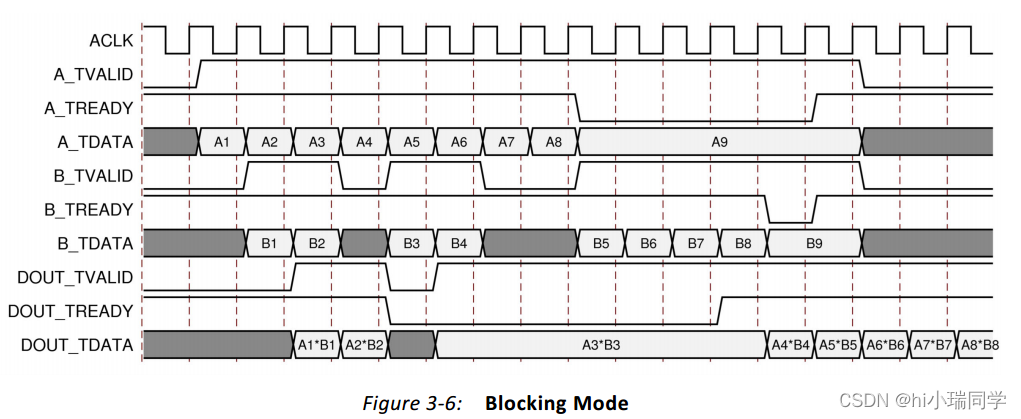
仿真结果:
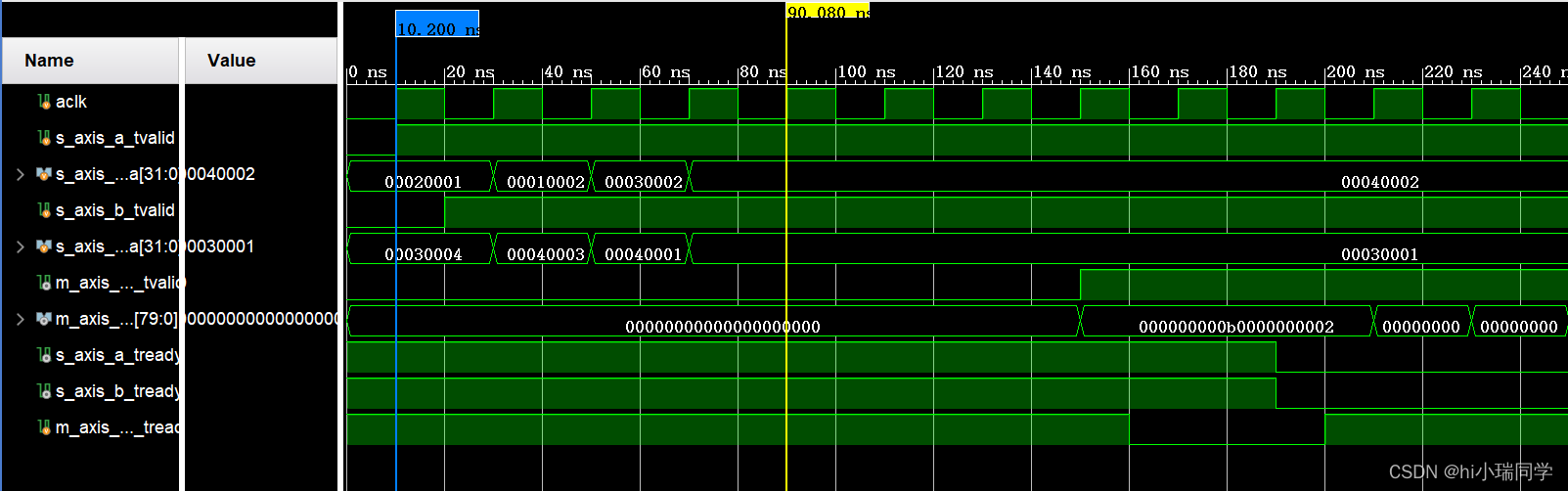
📄第一个输入的数据的运算结果未输出,这里有可能是IP核未将其视为有效的新数据。
📄在中间tready信号为0的一段时间,输出未更新*



















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











