







http://alpopkes.com/files/kl_divergence.pdf
Kullback-Leibler 散度
定义: Kullback-Leibler 散度用于度量两个分布的相似性(或差异)。
对于两个离散概率分布 P 和 Q ,在一个点集合 X 上 Kullback-Leibler 散度定义如下:
D
K
L
(
P
∣
∣
Q
)
=
∑
x
∈
X
P
(
x
)
l
o
g
(
P
(
x
)
Q
(
x
)
)
D_{KL}(P||Q)=\sum_{x\in X}^{}P(x)log(\frac{P(x)}{Q(x)} )
DKL(P∣∣Q)=x∈X∑P(x)log(Q(x)P(x))
对于连续变量上概率分布,求和变成积分:
D
K
L
(
P
∣
∣
Q
)
=
∫
−
∞
∞
p
(
x
)
l
o
g
p
(
x
)
q
(
x
)
D_{KL}(P||Q)=\int_{\mathrm{-\infty } }^{\infty } p(x)log\frac{p(x)}{q(x)}
DKL(P∣∣Q)=∫−∞∞p(x)logq(x)p(x)
其中 p 和 q 是 概率分布 P 和 Q 的 概率分布函数
Visual Example
在 Wikipedia entry 关于 KL divergence 有一张很 nice 的示意图
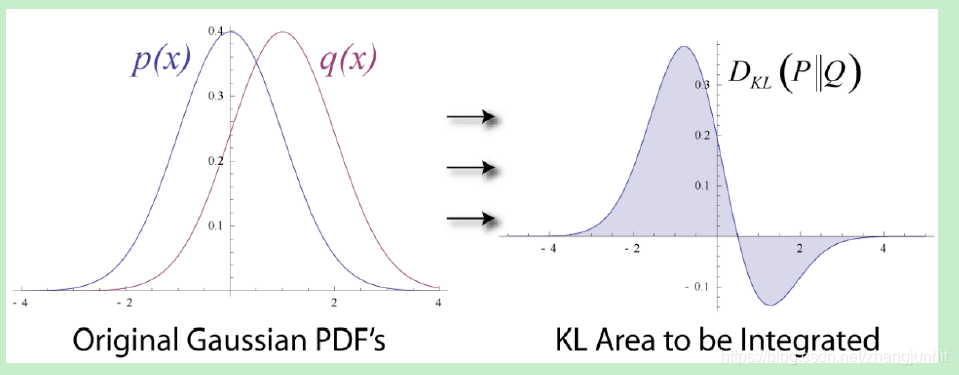
上图的左边我们看到两个高斯概率分布 p(x) 和 q(x)。 上图右边阴影面积就是对应于 p 和 q 的 KL divergence 计算积分值。我们知道
D K L ( P ∣ ∣ Q ) = ∫ − ∞ ∞ p ( x ) l o g p ( x ) q ( x ) = ∫ − ∞ ∞ p ( x ) ( l o g p ( x ) − l o g q ( x ) ) D_{KL}(P||Q)=\int_{\mathrm{-\infty } }^{\infty } p(x)log\frac{p(x)}{q(x)} =\int_{\mathrm{-\infty } }^{\infty }\mathrm{ p(x)\mathit{} } (\mathrm{log} p(x) -\mathrm{ log} q(x)) DKL(P∣∣Q)=∫−∞∞p(x)logq(x)p(x)=∫−∞∞p(x)(logp(x)−logq(x))
所以对于 x 轴上每个点 x i {x_{i}} xi , 我们计算 l o g p ( x i ) − l o g q ( x i ) {\mathrm{log} \,p(x_{i})-\mathrm{log} \,q(x_{i})} logp(xi)−logq(xi) 然后再乘上 p ( x i ) {p(x_{i})} p(xi) , 接着我们将最终结果作为 y 轴 进行绘制,我们得到上图右边的 y 轴。 KL divergence 对应上面右图的阴影面积
KL divergence in machine learning
在大多数的机器学习问题中,我们有一个数据集 X,它由一个未知的概率分布 P 生成的。 这个 P 分布就是 目标分布(真值分布),我们用一个 Q 分布来近似 P。然后我们可以用 KL divergence 来评估近似分布 Q 的好坏。在许多情况下,例如 variational inference , KL divergence 可作为最优化准则用于寻找最佳近似分布 Q。
Interpreting the KL divergence
Note : 这里我们采用一个概率角度来解释 KL divergence,这对机器学习来说是有用的。
Expected value 期望值
KL divergence 定义公式中用到了期望值,这里我们先回顾一下期望值定义。
对于离散变量
x
x
x,
f
(
x
)
f(x)
f(x)的期望值定义为
E
[
f
(
x
)
]
=
∑
x
f
(
x
)
p
(
x
)
E[f(x)]=\sum_{x}^{} f(x)p(x)
E[f(x)]=x∑f(x)p(x)
其中
p
(
x
)
p(x)
p(x) 是变量
x
x
x的 概率密度函数。
同样对于连续变量我们有
E
[
f
(
x
)
]
=
∫
−
∞
∞
f
(
x
)
p
(
x
)
E[f(x)]=\int_{-\infty }^{\infty} f(x)p(x)
E[f(x)]=∫−∞∞f(x)p(x)
Ratio p ( x ) / q ( x ) p(x)/q(x) p(x)/q(x)
我们仔细瞅瞅 KL divergence 的定义公式,我们可以发现KL divergence的定义很像 期望值的定义。当我们设置 f ( x ) = l o g ( p ( x ) q ( x ) ) f(x)=log(\frac{p(x)}{q(x)} ) f(x)=log(q(x)p(x)), 那么我们可以看到
E [ f ( x ) ] = E x ∼ p ( x ) [ l o g ( p ( x ) q ( x ) ) ] = ∫ − ∞ ∞ p ( x ) l o g p ( x ) q ( x ) d x = D K L ( P ∣ ∣ Q ) E[f(x)]=E_{x\sim p(x)} [log(\frac{p(x)}{q(x)} )] =\int_{\mathrm{-\infty } }^{\infty } p(x)log\frac{p(x)}{q(x)}dx =D_{KL}(P||Q) E[f(x)]=Ex∼p(x)[log(q(x)p(x))]=∫−∞∞p(x)logq(x)p(x)dx=DKL(P∣∣Q)
The KL divergence is simply the expected value of the log-ratio of the entire dataset.

















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









