









Loss Max-Pooling for Semantic Image Segmentation
CVPR2017
https://arxiv.org/abs/1704.02966
本文采用偏数学语言的角度来描述语义分割样本类别分布不均匀问题,提出一个方法 Pixel-Loss Max-Pooling
本文主要解决什么问题了? 针对语义分割训练样本类别分布不均匀问题
handle imbalanced (or skewed) class distributions, as often encountered in semantic segmentation datasets, within deep neural network training so far.
With imbalanced, we refer to datasets having dominant portions of their data assigned to (few) majority classes while the rest belongs to minority classes, forming comparably under-represented categories.
As (mostly undesired) consequence, it can be observed that classifiers trained without correction mechanisms tend to be biased towards the majority classes during inference
这里所说的不均匀,就是我们的训练数据库有少数类别的样本很多( (few) majority classes),剩下的类别的样本都比较少。 如果在训练的时候没有修正这个不均匀,那么学习到的分类器就会偏向于 那些少数样本很多的类。
解决这个问题目前有几个思路:
1)就是在建立数据库的时候就注意到样本的均匀分布问题,例如 ImageNet, Caltech101/256 or CIFAR10/100
2)通过对样本少的类别 over-sampling 或 对样本多的类别 under-sampling
over-sampling of minority classes or under-sampling from the majority classes when compiling the actual training data
3)通过引入样本类别分布的权值来改变算法行为
cost-sensitive learning changes the algorithmic behavior by introducing class-specific weights, often derived from the original data statistics
首先使用一个数学公式描述语义分割问题

其中 L 是 loss function penalizing wrong image labelings, R 是一个 regularizer
The loss function L commonly decomposes into a sum of pixel-specific losses as follows

The loss function defined in (2) weights uniformly the contribution of each pixel within the image.
上面定义的损失函数默认图像中每个像素的权重是均匀分布的
The effect of this choice is a bias of the learner towards elements that are dominant within the image (e.g. sky, building, road) to the detriment of elements occupying smaller portions of the image
这使得学习器偏向于图像中占比大的区域,相对忽略占比小的区域
In order to alleviate this issue, we propose to adaptively reweigh the contribution of each pixel
based on the actual loss we observe
Our goal is to shift the focus on image parts where the loss is higher, while re-taining a theoretical link to the loss in (2). The solution we propose is an upper bound to L, which is constructed by relaxing the pixel weighting scheme
这里主要是给每个像素的权值引入一个上限 L,就是占比大的像素权值有一个上限,这样防止学习到的分类器有偏向性。
如果从样本类别分布不均匀的角度来说,我们对每个样本类型乘以一个权重系数,达到归一化的目的。
Cityscapes validation set

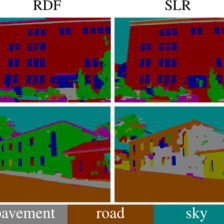
Evolution of semantic segmentation images during training

Cityscapes Pascal VOC 2012 validation

ResNet based results on Pascal VOC 2012 segmentation validation data
















 3070
3070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









