







1 介绍
现有的SLAM算法都是基于全图静止的假设的。所以场景中如果存在大量运动的话就会有问题。所以现在动态SLAM越来越热门。所以作者提出了个动态SLAM算法,包含计算相机pose,运动目标轨迹和静态结构建图。
作者计算这些参数用的是传统方法,识别运动目标和计算光流用的是深度学习。
算法的思想实际上就是:
- 利用深度学习或传感器获得RGBD数据
- 利用深度学习获取运动目标的mask,以及整图稠密的光流。
- 跟踪运动目标,利用静止目标计算相机pose
- 利用图优化对整体的精度进行优化refine
- 输出map,pose和trajectory。
2 方法
2.1 背景和符号
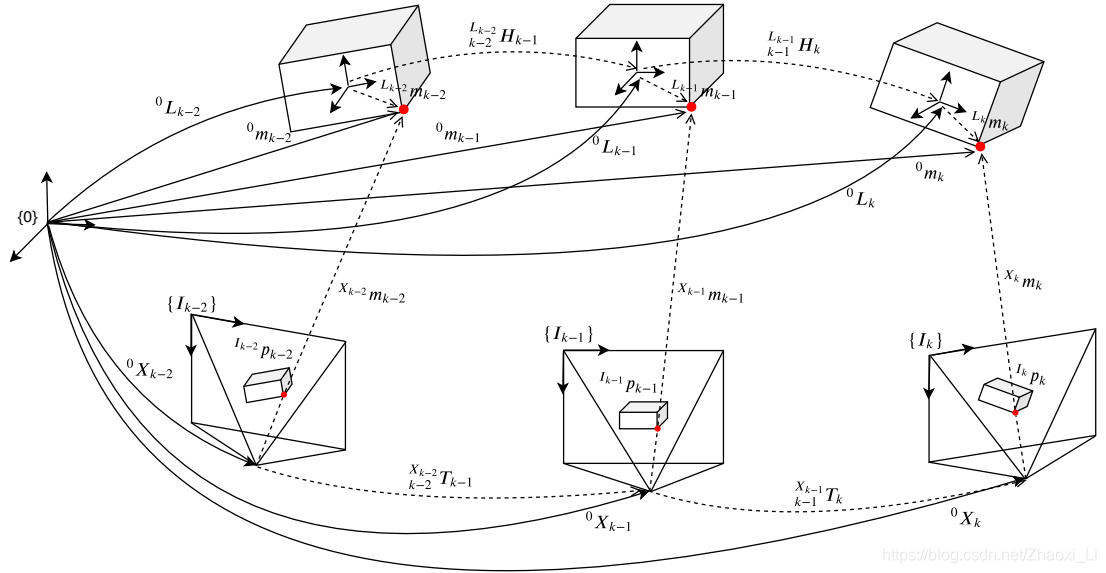
下面给出一些符号的定义,配着图看可能更容易理解。
- 0 X k , 0 L k ^0X_k,^0L_k 0Xk,0Lk表示本体到全局坐标系的变换矩阵,分别代表相机和目标3D的位姿。 k k k表示第几帧数据。
- 0 m k i = [ m x i , m y i , m z i , 1 ] T ^0m_k^i=[m^i_x,m^i_y, m^i_z,1]^T 0mki=[mxi,myi,mzi,1]T表示第k时刻,第i个点在全局坐标系下的齐次坐标,那么这个点在相机坐标系下的表示就为 X k m k i = 0 X k − 1 0 m k i ^{X_k}m^i_k=^0X^{-1}_k{^0m_k^i} Xkmki=0Xk−10mki。
- 定义 I k I_k Ik为k时刻的图像坐标系,则这个坐标系下的点的表示为 I k p k i = [ u i , v i , 1 ] ^{I_k}p^i_k=[u^i,v^i,1] Ikpki=[ui,vi,1]。利用相机内参 K K K可以构建2D-3D点之间的映射关系 π \pi π。
- 两个时刻同一个目标的对应像素点之间的移位表示光流,即 I k ϕ i = I k p k i − I k − 1 p k − 1 i ^{I_k}\phi^i={^{I_k}p^i_k} -{ ^{I_{k-1}}p^i_{k-1}} Ikϕi=Ikpki−Ik−1pk−1i
-
k
−
1
L
k
−
1
H
k
^{L_{k-1}}_{k-1}H_k
k−1Lk−1Hk表示两个相邻时刻间目标或相机的坐标系变换,
k
−
1
L
k
−
1
H
k
=
0
X
k
−
1
−
1
0
X
k
{^{L_{k-1}}_{k-1}H_k}={^0X^{-1}_{k-1}}{^0X_k}
k−1Lk−1Hk=0Xk−1−10Xk。
基于这些变换,可以得到世界坐标系和相机坐标系之间的变换关系。
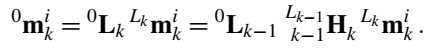
进一步可以得到在世界坐标系下两个不同时刻同一个点之间的变换关系:
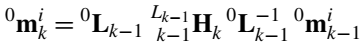
- 定义 k − 1 0 H k = 0 L k − 1 ⋅ k − 1 L k − 1 H k ⋅ 0 L k − 1 − 1 {^0_{k-1}H_k}={^0L_{k-1}}\cdot{^{L_{k-1}}_{k-1}H_k}\cdot{^0L^{-1}_{k-1}} k−10Hk=0Lk−1⋅k−1Lk−1Hk⋅0Lk−1−1表示不同时刻之间全局坐标系下空间点的变换矩阵。这个公式表示一个位姿变换的帧间变化,a frame change of a pose transformation。这个公式也是运动估计方法的核心。
2.2 相机位姿和目标运动估计
相机位姿估计。估计位姿需要构建一个目标函数,怎么判断相机位姿是否正确,思想很简单。在世界坐标系下,在k-1时刻得到一对静态目标的3D点,静止目标在世界坐标系下的坐标是永远不可能变得,因此将这些点利用相机位姿(待求量)转换到k时刻的相机坐标系下,再投影到图像上,理论上应该与对应特征点像素重合。实际上,由于误差的存在肯定不重合,这样就可以得到一组误差,这个误差是像素点差的向量。
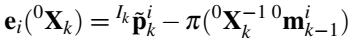
利用误差构建Loss函数,
ρ
h
\rho_h
ρh是Huber函数,协方差可以通过误差估计出来,利用LM算法最小化这个函数,即可得到相机位姿。
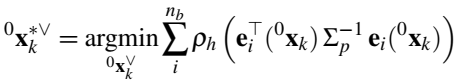
目标运动估计。思路与相机位姿估计是相似的,只不过运动目标多了一个运动补偿变换矩阵,但最后都是计算投影之后的像素点误差。计算方法都是一致的,也是用LM算法进行求解。这里面p是像素点,m是空间点。

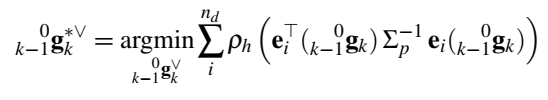
联合光流估计。相机位姿和目标运动估计都依赖良好的图像对应关系, 该过程的目的是利用光流来估计位姿和精炼光流信息,对于相机位姿估计问题,目标函数转为如下所示,实际上就是当前像素是由上一帧像素+光流构成。
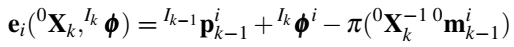
损失函数是一样的,只不过多了一个归一化项,归一化项目的是refined后的光流应该与原始光流差异不大。
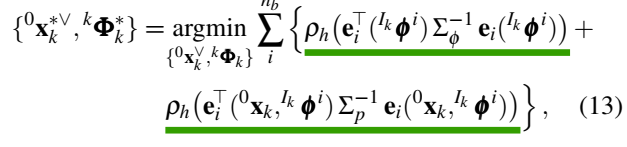
对于运动目标的运动估计,用法一样,都是用光流替代像素位置。
2.3 图优化
将一个动态SLAM问题变为一个图优化问题,用于refine 相机pose和目标运动,并建立一个全局一致图(包含动态和静态结构)。这个图整合了4种数据:3D测量点,视觉里程计,动态目标上点的运动i,和目标平滑运动。下面就针对这些输入点构造对于的误差函数。
3D点测量模型误差,投影到图像坐标系下点的误差。z应该是用RGBD数据算出的观测点。
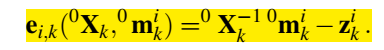
两帧之间相机的位姿变化应该与里程计提供的结果相似。
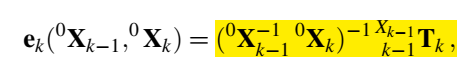
动态点帧之间的变化应该是匹配的。
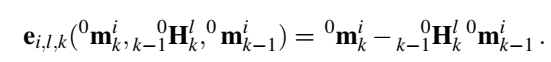
平滑性约束,认为两个时刻之间运动是相似的。
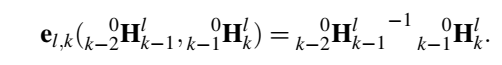
把所有这些loss构成个大Loss,就是目标函数。
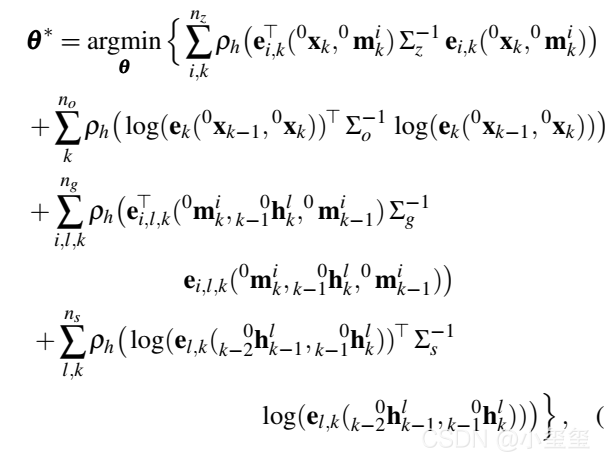
需要优化的参数包含观测出的3D点,相机Pose和运动变换H。这里面包含大量参数。求解也是用LM算法(→_→诡异)。
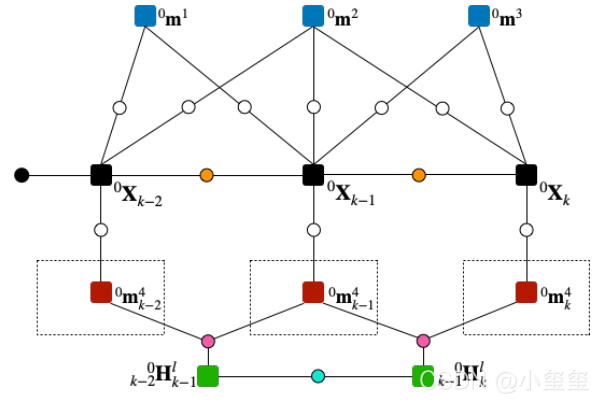
3 系统
这节提出了一个目标感知动态SLAM系统,可以同时估计相机和目标的运动以及环境的静态和动态结构。整个系统的结构如下图所示。系统的输入要求是RGBD图像,来源有三种,深度相机采集,单目深度估计,以及立体视觉深度估计。单目深度估计利用的是深度学习算法MonoDepth2。
预处理阶段,包含两个部分,分离静态背景和目标,然后确定需要长期跟踪的动态目标。作者利用实力分割算法来分割和识别场景中潜在的运动目标。利用一些合作信息,建筑和路永远是静止的,但是车辆可能是静止或运动的。实例分割可以输出一堆目标的Mask,因为分割精度较高,也包含了许多可以用于后续跟踪的特征点。
稠密的光流能够用来最大化用于目标跟踪的点的个数。作者假设大多数移动的目标仅有少量的遮挡(实际上就是约束要有足够多的特征点)。稀疏特征点匹配导致特征点不多,因此要用稠密特征点匹配算法PWC-Net,来预测一个稠密的光流。当语义分割失败的时候,光流还可以用来恢复目标的mask(因为跟踪的特征点特别多,所以有少量的丢失也不算啥)。
3.1 跟踪
跟踪过程包含两个部分,① 使用特征检测和相机位姿估计的部分模块实现自主跟踪。② 目标运动跟踪,包含动态目标跟踪与目标运动估计的部分模块。
特征检测。为了实现相机位姿的快速估计,作者利用角点检测算法(FAST)得到一组稀疏集合,然后利用光流去跟踪这些点。在每帧中,只有满足估计的相机运动的内部特征点用来建图,并用于跟踪下一帧相关的特征点。如果跟踪的点小于某个确定的阈值,就在增加新的点。这些稀疏特征覆盖在静态背景上,也就是不包含分割目标的图像区域。
相机位姿估计。相机位姿估计可以使用上一节介绍的3D和2D对应的那种计算方法得到。为了保证估计是鲁棒的,应用了一个模型生成方法用于初始化。特别地,方法生成两个模型,并基于再投影误差比对内部点的个数。一个是利用之前的运动来计算,另一个是利用P3P的方法。产生最多内在点的运动模型将会被选择用来初始化。
动态目标跟踪。分割出目标之后,根据上面算出的相机位姿,可以将当前3D点转到上一帧图像中,并与上一帧的图像点做差,得到场景光流。理论上,静止的目标,点应该是重合的,但由于误差的存在,静态的点会存在一些流,但是模很小,因此作者就设置了一个阈值来去除静止点。再统计每个实例中动态点的比例,大于30%则认为是运动目标。对于跟踪过程中目标区域的变化,作者使用了一个策略来更新这些点,(光看文字看不懂,细节只能看代码T_T)。
目标运动估计。目标一般在场景中很小的区域出现,这将会导致稀疏特征点不充足,进而影响跟踪和运动估计阶段。作者对每个目标mask采样了3个点,并进行跟踪。
3.2 建图
局部bach优化。这步目的是确保精确的相机位姿估计,以用于全局batch优化。位姿不对将会对目标运动的估计有很大的影响。建图仅使用静态结构,不使用动态区域。当图建立起来之后,使用一个图优化来refine这个图中的所有变量。并在全局图中进行更新。
全局batch优化。跟踪盆和局部batch优化的输出包含了相机的pose,目标的运动和内部结构。在所有输入的framer处理完之后,将会基于全局图构建出一个因子图。用于跟踪超过3个实例的点将会被加进全局图中。图在前面已经有介绍。优化结果作为整个系统的输出、。
4 实验结果
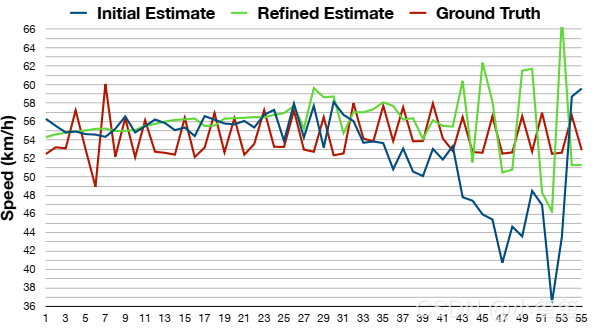
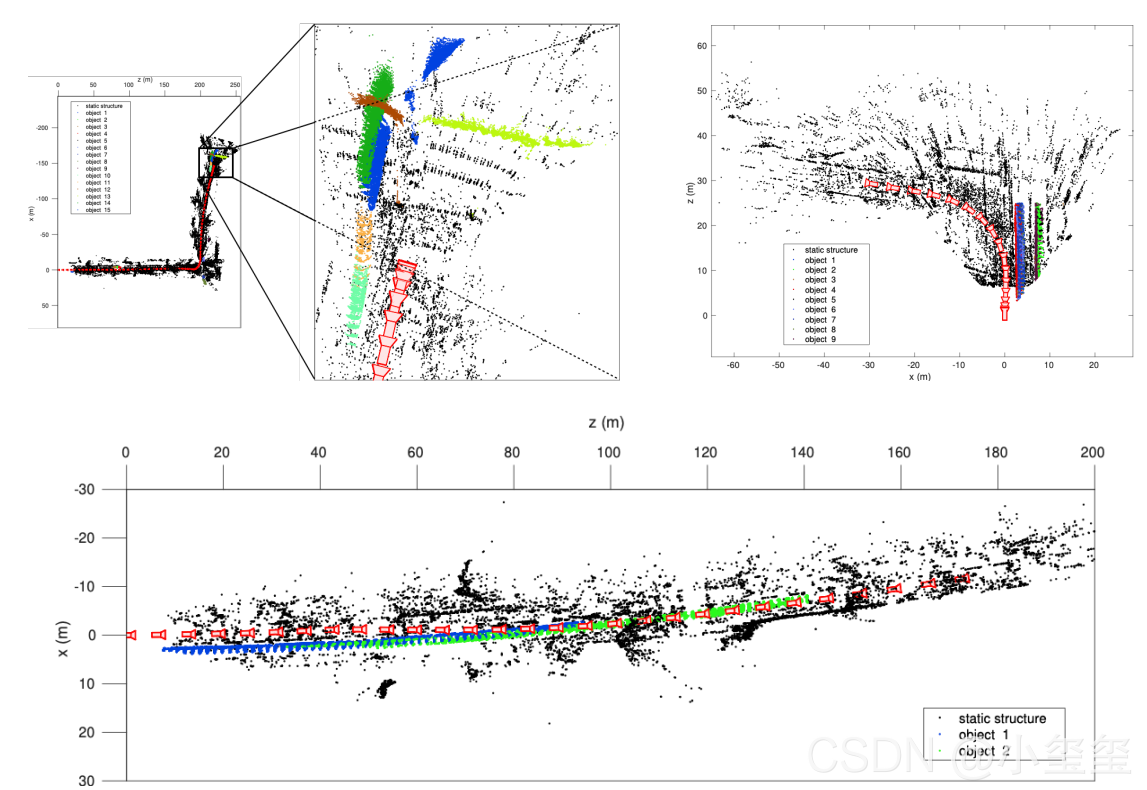
精炼部分确实能提高精度
运动目标一般不建图,主要是用来画轨迹
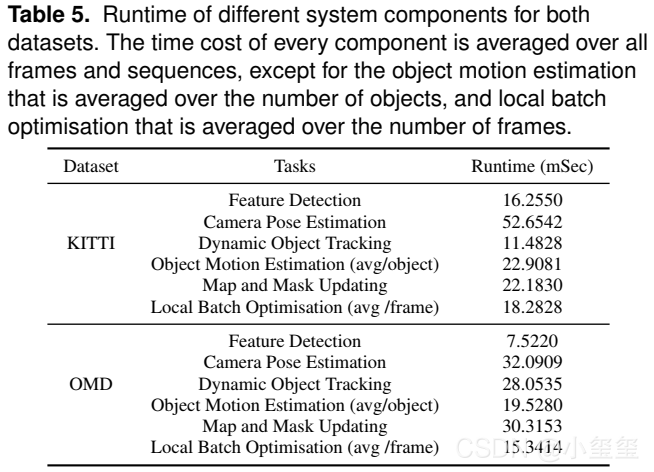
不同阶段的算法处理时间,将近200ms,如果后续打算基于这个的思想的话是一定要做程序优化的。
5 个人总结
算法核心是传统方法,能推动已经很不错了,其实所有部分都是在设计一个优化函数进行优化,后续要改进的话,一是需要分析误差比较大的情况,查找原因,确定是算法有问题还是优化函数有问题。其次,实时性需要进一步提升。














 3836
3836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









