







 本文探讨了在NVMe IO数据传输中,如何根据Linux内核中的条件选择使用PRP或SGL来描述Host内存地址。讲解了PRP和SGL的区别,以及内核如何决定使用哪种方式,涉及avg_seg_size和sgl_threshold的计算。此外,还提到了NVMe Controller的标识页面信息对SGL支持的查询以及在NVME over Fabrics场景中的应用。
本文探讨了在NVMe IO数据传输中,如何根据Linux内核中的条件选择使用PRP或SGL来描述Host内存地址。讲解了PRP和SGL的区别,以及内核如何决定使用哪种方式,涉及avg_seg_size和sgl_threshold的计算。此外,还提到了NVMe Controller的标识页面信息对SGL支持的查询以及在NVME over Fabrics场景中的应用。
在Host与Controller之间有数据交互时,Controller会多次访问Host内存。比如执行NVMe Read/Write:
-
当Host下发NVMe Write命令时,Host会先放数据放在Host内存中,然后通知Controller过来取数据。Controller接到信息后,会通过PCIe Memory Read TLP读取相应的数据,接着Host返回的PCIe Completion报文中会携带数据给Controller,最后再写入NAND中。
-
当Host下发NVMe Read命令时,Controller先从NAND中读出相应数据,然后通过PCIe Memory Write TLP将数据写入Host内存中。
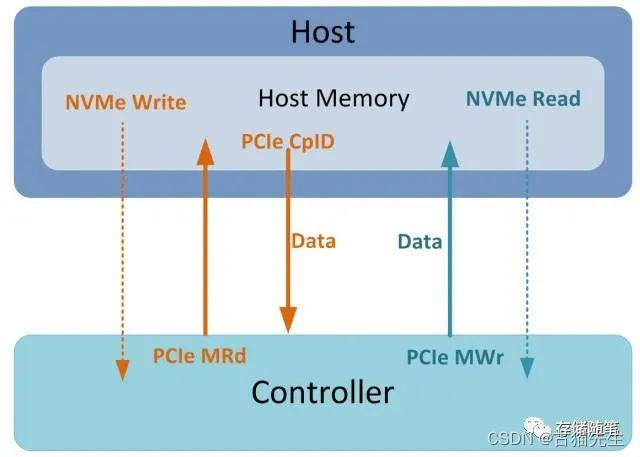
上述Read/Write均有访问Host内存进行数据交互,那么,问题来了:
-
NVMe Write时,Controller怎么知道数据在Host内存的具体位置?
-
NVMe Read时,Controller怎么知道要把数据写到Host内存中哪个位置?
不怕,NVMe给Host配备了两大"法宝":PRP和SGL。这两个模型均可以帮助Host告知Controller数据在Host内存中的具体地址。
PRP/SGL的背景知识,这里就暂时略过了,感兴趣的同学可以参考之前发布的文章。这里简单提下。存储随笔《NVMe专题》大合集及PDF版正式发布!
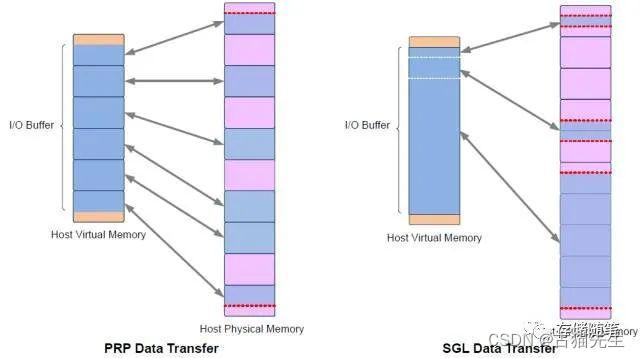
PRP和SGL是描述Host内存物理空间的两种方式,本质的不同是:PRP必须是物理页对齐的,而SGL则可以表述任意的物理空间。如下图。
在Linux内核中,Block层下发的IO请求以BIO表示。我们需要通过DMA发送这些数据,Command使用dma_alloc_coherent分配DMA地址,但是BIO是存放在普通的内核线程空间的(线程的虚拟空间不能直接作为DMA地址)。
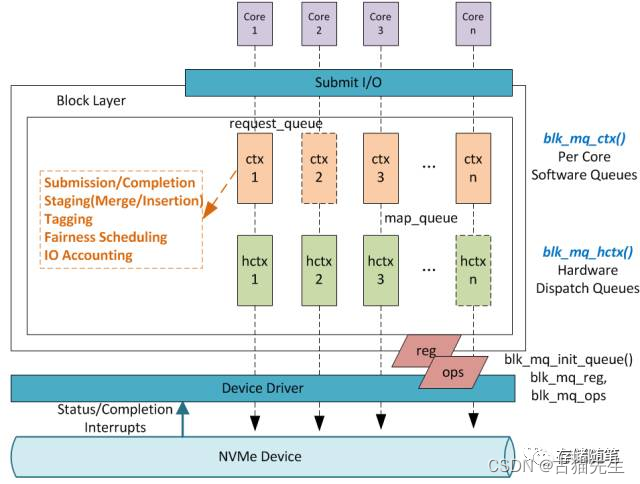
Linux函数nvme_map_data能够将虚拟空间地址(BIO数据存放地址)转换成DMA可用地址,并且多个IO请求的DMA地址可以通过scatterlist来表示。有了DMA地址就可以把BIO封装成NVMe Command发送出去。
所以,linux驱动中nvme_map_data中针对NVME Command的IO传输格式就有了很重要的设定。比如,函数nvme_map_data中有iod->use_sgl的结果可以觉得IO传输过程中是使用SGL还是PRP。

而iod->use_sgl的返回结果依赖函数nvme_pci_use_sgls的判断,主要有两种情况:
-
当SGL不支持的时,iod->use_sgl返回false,对应的IO数据传输就采用PRP了。
-
当平均请求大小avg_seg_size值小于SGL阈值sgl_threshold时,也返回false,需要采用PRP。也就是说,使用SGL情况,必须要要求avg_seg_size大于等于sgl_threshold。SGL比较适合大块数据的传输。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2610
2610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











