







连接CPU、GPU或加速器与内存的关键在于基板芯片。改进这种连接是克服内存限制的一种可能途径。由美光和英特尔等资助的初创公司Eliyan正在领导这一方向,他们推出的UMI自定义接口被用来与ASIC基板一起使用,该基板充当HBM堆栈或其它类型内存模块控制器的基础。这块芯片包含了内存控制器和与内存芯片的物理互连(PHY)。UMI外部连接到主机GPU,附着在主机的结构上。使用完整的CMOS工艺制造,它们可以快速且高效,使用先进的"Nulink"协议连接到主机,消除主机硅片上的内存控制器占用。


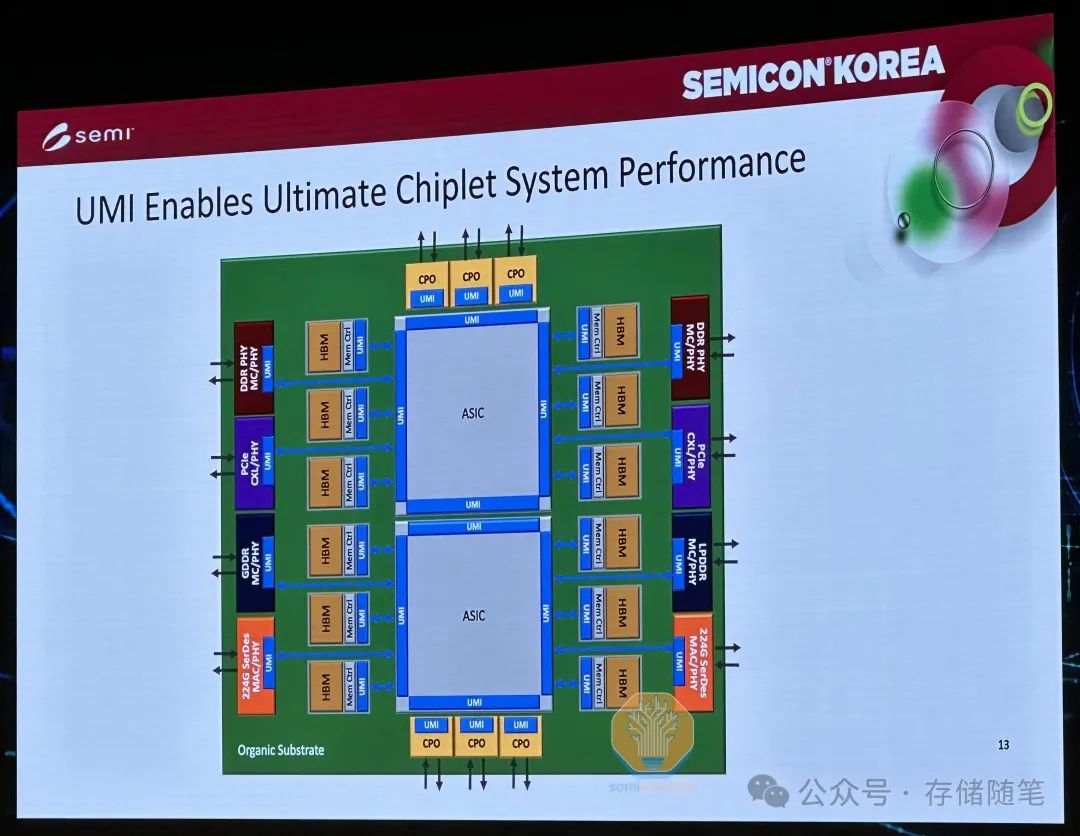
Eliyan的封装技术即使在标准衬底上也能工作,并且具有比常规先进封装更远的延伸范围。这可能允许HBM远离ASIC基板,意味着可以容纳更高的容量。他们的方法还减少了主机上的面积和海岸线,这意味着可以增加通道宽度。标准化的UMI内存芯片可以让HBM、DDR、CXL内存等多种内存类型被使用,而不必固定于某一特定类型,从而大大增加了灵活性。尽管这种方法可能会带来短期的改进,但它并没有解决HBM的基本成本问题。
尽管DRAM和NAND一直是主流,但研究更好的替代品一直在进行。这些替代品通常被称为“新兴内存”。目前还没有一种真正大规模商用化的新兴内存。鉴于AI领域的新挑战和激励机制,这些技术至少值得讨论。
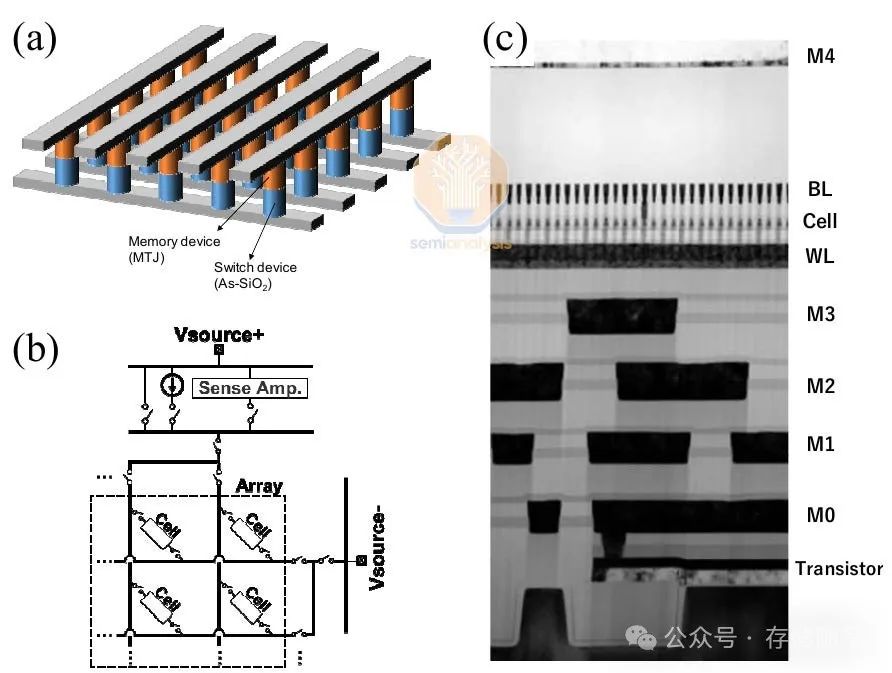
最有前景的应用独立器件的内存是铁电随机存取存储器(FeRAM)。FeRAM在存储电容器中使用铁电材料而不是绝缘材料,具有非易失性,即可以在关闭时保存数据,无需刷新,节省了电力和时间。
Micron在IEDM 2023上展示了密度可与他们的D1β DRAM相比的结果,并且具有良好的耐久性和保留性能。然而,由于制造复杂且使用了更多异国情调的材料,FeRAM目前并不具备竞争力。
磁阻式随机存取存储器(MRAM)是另一个有希望的研究领域。MRAM利用磁性方式而不是电荷来存储数据,大多数设计使用磁隧道结(MTJ)作为比特存储单元。SK海力士和Kioxia在IEDM 2022上展示了一款1选择器MTJ单元,实现了迄今为止最高的MRAM密度0.49Gb/mm²,超过了Micron的D1β DRAM的密度0.435Gb/mm²。他们的目标是以替代DRAM的形式将其商业化。
目前,没有任何一种替代内存能够在挑战DRAM方面占据有利位置。一些替代内存存在较大或较慢的单元,一些有更昂贵的工艺,大多数耐久性有限,还有一些良率低。实际上,目前出货的磁性或相变内存产品的容量是以MB计而不是GB。不过,随着大量资金投入,或许在不久的将来会出现赢家,但这还需要大量的设备和量产规模的工作。
DRAM从一开始就因其架构而受限。它是一个简单的状态机,没有控制逻辑,这有助于降低成本,但也意味着它依赖于主机(CPU)来控制。现代DRAM制造工艺高度优化和专业化,无法实际生产控制逻辑。JEDEC在制定新标准时也强制要求逻辑的最小介入。
内存内计算(Compute in Memory, CIM)的目标是将部分或全部计算能力移至靠近内存的位置,以减少数据传输带来的延迟和功耗。这种转变有望极大地提高计算效率,尤其是在处理大量数据集时。
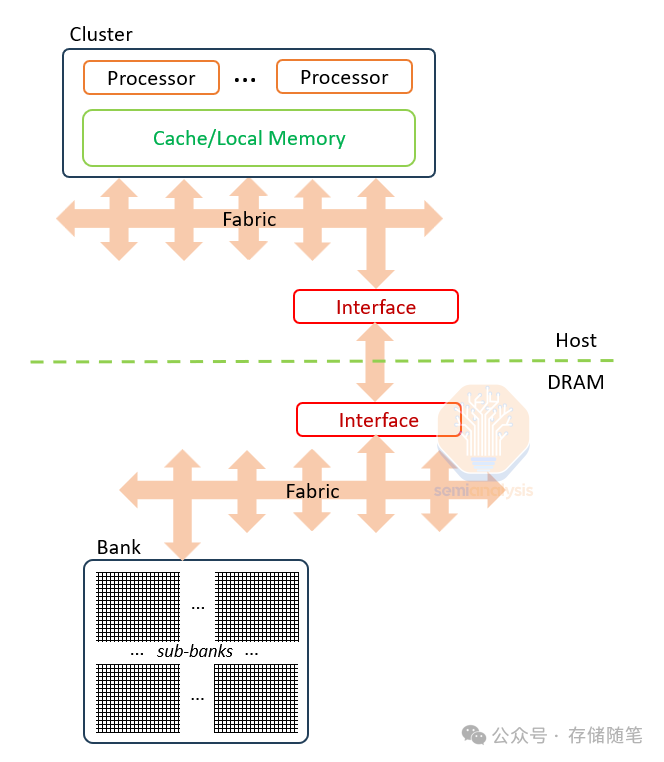
控制逻辑与内存分离,因此命令必须通过一个缓慢且低效的接口传递。这导致了DDR5 DIMM在服务器中最常见的形式,超过99%的读写能量消耗在主机控制器和接口上。HBM的能耗情况稍好一些,大约95%的能耗发生在接口上,5%发生在内存单元的读写上,但仍远未达到DRAM的全部潜力。功能的位置不当自然需要将控制逻辑移到正确的地方:即在芯片上与内存一起,这就是内存内计算(CIM)的概念。
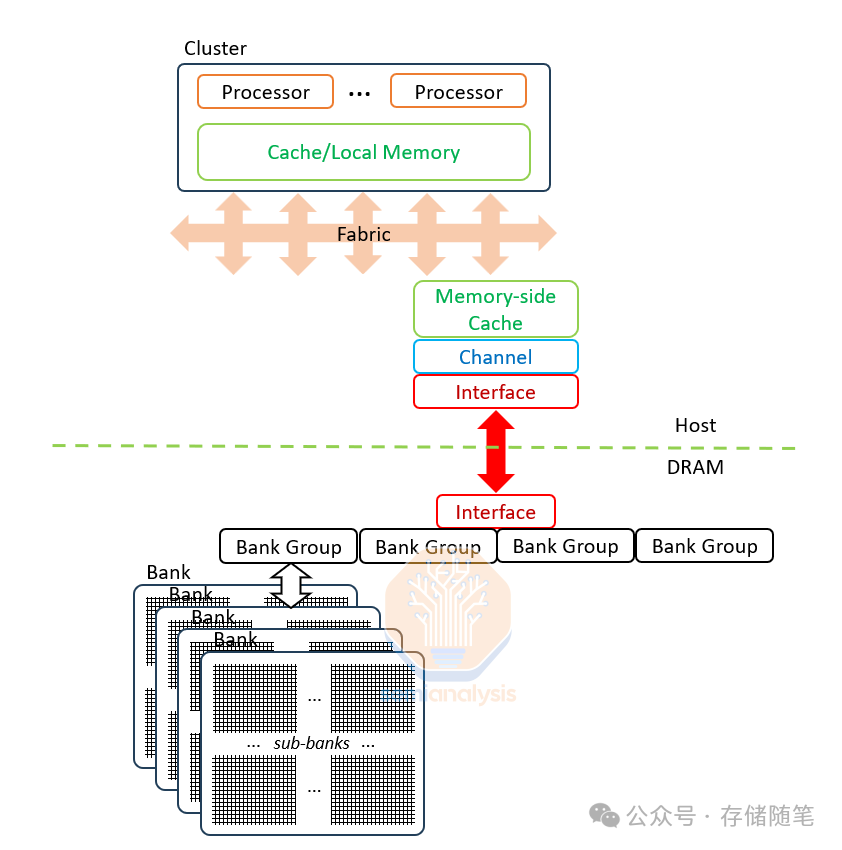
内存Bank拥有巨大的性能潜力,但由于接口限制而未能充分利用。Bank是DRAM的基本构建单位,每个Bank包含8个子Bank,每个子Bank具有64Mb(8k行×8k位)的内存。Bank一次激活并刷新一行8k位,但在任何I/O操作中只能传输其中的256位。这种限制源于来自感测放大器的外部连接:尽管一行由8k个感测放大器支持,但只有1/32(256位)的感测放大器连接出子Bank,这意味着读写操作限于256位。通过改进接口设计和引入更高效的内存控制逻辑,CIM有望释放DRAMBank的巨大潜能,提高数据处理效率和降低功耗。
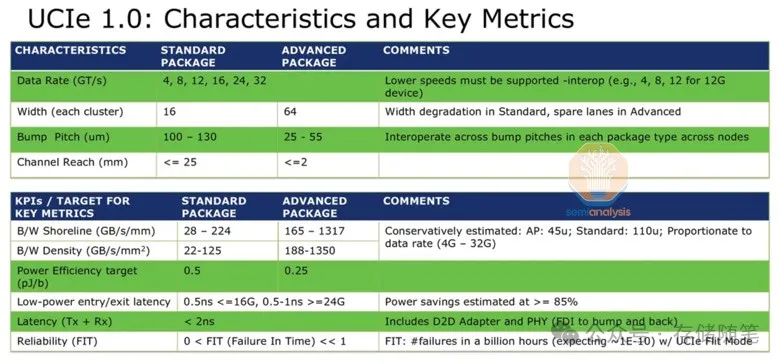
即使是最简单的理论例子也显示出了巨大的潜力。实现UCIe(通用芯粒互连)标准可以使每毫米边缘达到11 Tbps的吞吐量,几乎是HBM3E的12倍。每比特的能量消耗将从2pJ降低到0.25pJ。而且,UCIe甚至不是最新的解决方案——Eliyan的专有Nulink标准声称可以提供更大的改进。
向DRAM芯片添加逻辑并非易事。好消息是HBM包含了一个CMOS基板芯片,而当3D DRAM到来时,几乎可以肯定会在内存堆栈之上或之下键合优质的CMOS逻辑。换句话说,这种架构适合在内存内部加入一些计算功能,并且芯片制造商也会有动力这么做。
这里有许多低垂的果实可以摘取:如果HBM采用GDDR7的32Gbps数据线速率会发生什么?GDDR7证明了足够快的晶体管可以在DRAM芯片上制造,并且通过TSV(穿硅通孔)到达基板堆栈的垂直距离小于1mm,应该可以保持每比特0.25pJ的能量范围。这就引出了一个问题:为什么JEDEC不倾向于采用一个改进的标准?
基板上的外部接口可以大幅升级到现代设计,提供每毫米边缘超过1TB/s的带宽,每比特能量消耗为几分之一皮焦耳。在IP战争中,有人将赢得巨大胜利。虽然JEDEC有可能采用一种选择作为标准,但更有可能的是,行动更快的记忆体/GPU供应商组合会先采取行动,因为JEDEC通常需要数年时间来制定标准。
在HBM4中,第三方基板芯片已经被接受,这必然会引发实验。我们可能会看到卸载的通道控制、互联上的纯结构扩展、在几厘米距离内的每比特能耗降低,以及与远离主机的其他HBM行或像LPDDR这样的第二层级内存的菊花链连接。
通过这种方式,设计可以绕过在内存堆栈内部进行计算时遇到的功耗限制,而是使用基板芯片上的现代化接口,让相邻芯片拥有如同在内存中计算般的带宽和低能耗。
3D DRAM革命
接下来我们将讨论即将到来的DRAM革命:3D。这将对内存制造商和晶圆厂设备产生重大影响。以下是关于3D DRAM的一些基本概念、制造方式以及潜在的赢家和输家。
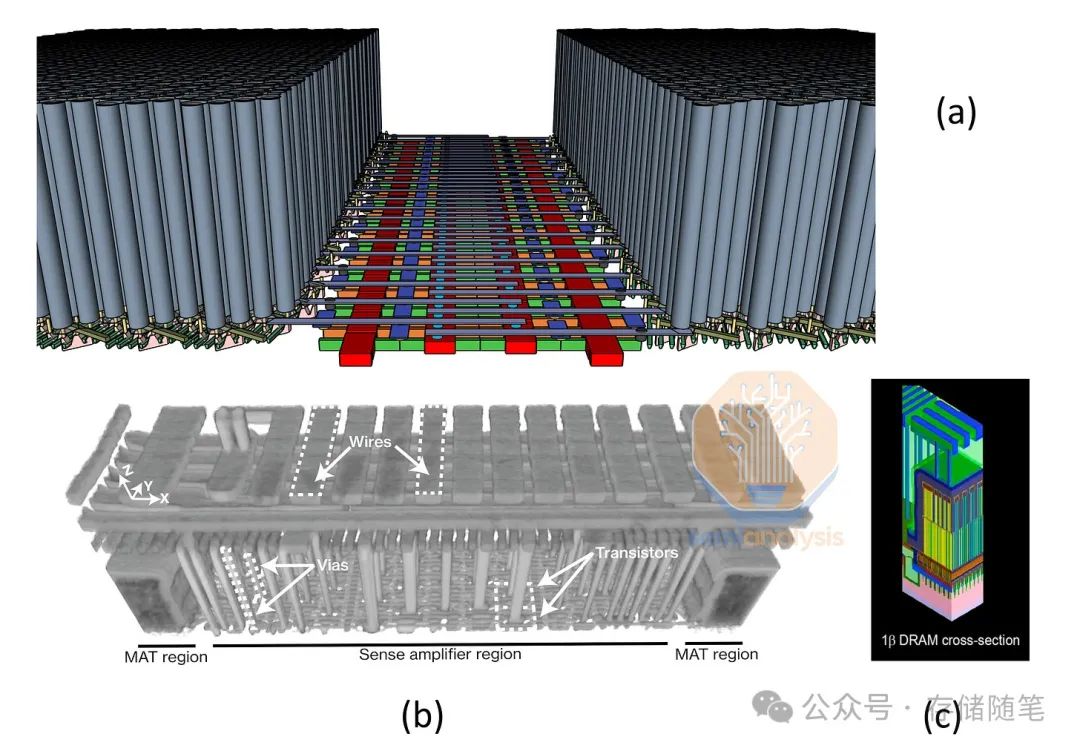
3D DRAM不仅仅是简单的垂直堆叠,它是通过先进的封装技术如TSV来实现的,这些技术允许在不同的内存层之间进行高效的数据交换。3D DRAM的设计和制造涉及到复杂的工艺流程,包括多层堆叠、热管理和信号完整性问题。
潜在的赢家:
-
那些拥有先进封装技术和工艺能力的公司。
-
在内存架构和设计上有深厚积累的企业。
-
能够与逻辑芯片供应商紧密合作以实现高效互联的厂商。
潜在的输家:
-
无法跟上技术进步步伐的传统内存制造商。
-
缺乏先进封装技术的公司可能会落后。
3D DRAM的发展不仅需要技术上的革新,也需要行业标准的更新和供应链的合作。未来的计算体系结构将越来越多地依赖于内存内计算的能力,以满足不断增长的数据处理需求。
展望未来
面对DRAM扩展放缓的挑战,业界正在探索各种解决方案。从延长HBM路线图的短期想法到更复杂的长期选项,如内存内计算(CIM)、新型内存类型如铁电RAM(FeRAM)或磁阻RAM(MRAM),以及即将到来的4F2 DRAM和3D DRAM。随着数百亿美元的AI资本支出投入,业界有强大的推动力来推进这些解决方案。
为了应对DRAM扩展难题,我们需要综合考虑技术创新、经济可行性和市场需求。只有这样,我们才能确保未来的计算系统能够在内存性能、容量、成本和功耗方面取得平衡,从而满足不断增长的数据密集型应用需求。
如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:



















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











