







随着人工智能(AI)、机器学习(ML)和高性能计算(HPC)应用的快速发展,对于高效能、大容量且低延迟内存的需求日益增长。NVIDIA在其GB系列GPU中引入了不同的内存模块设计,以满足这些严格的要求。
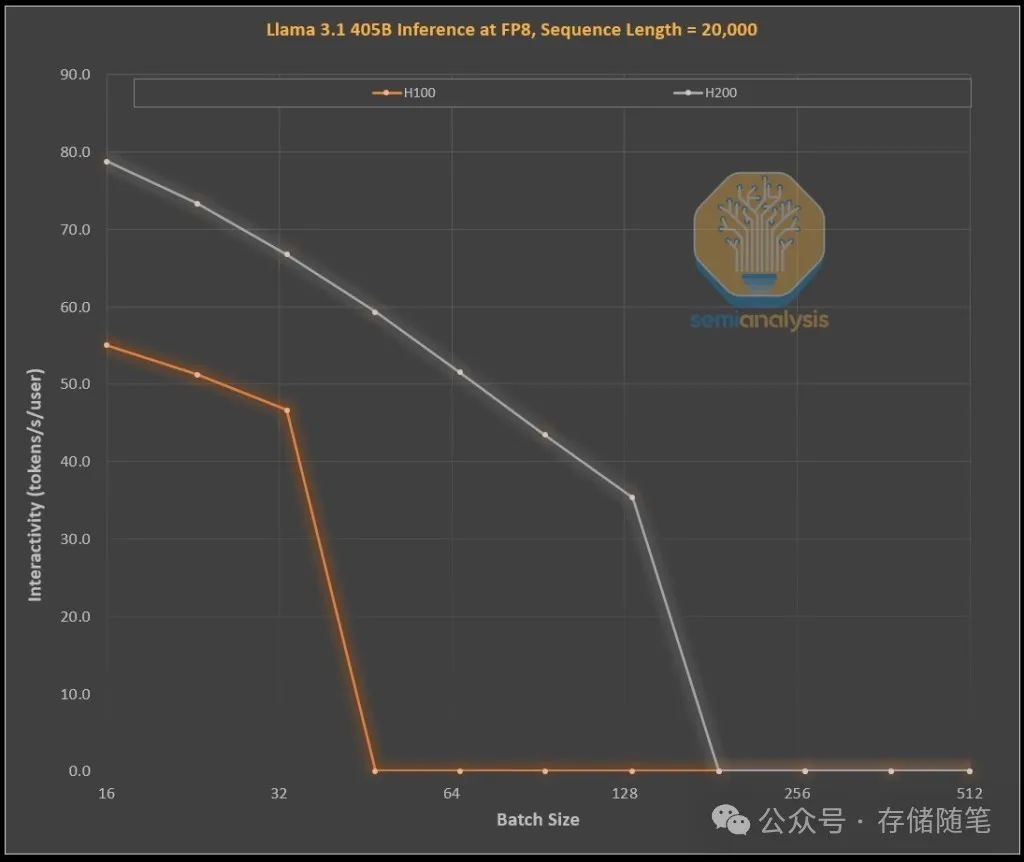
此前,当从H100升级到H200时,由于后者提供了更高的内存带宽(4.8TB/s对比H100的3.35TB/s),所有可比较的批处理大小上的交互性普遍提高了43%。得益于KVCache对总批处理大小的限制减少,H200能够以更高的批处理速度运行,从而每秒生成三倍数量的token。这使得整体运营成本降低了约三倍,远超出了单纯硬件规格所能带来的预期收益。
随着NVIDIA推出GB300 GPU,其供应链和提供的组件发生了重大变化。此前,针对GB200,NVIDIA提供了完整的Bianca板(包括Blackwell GPU、Grace CPU、512GB的LPDDR5X内存、VRM内容等集成在一个PCB上),以及交换托盘和铜背板。然而,对于GB300,NVIDIA采取了不同的策略,仅提供核心组件,并允许更多原始设备制造商(OEM)和原始设计制造商(ODM)参与计算模块的制造。
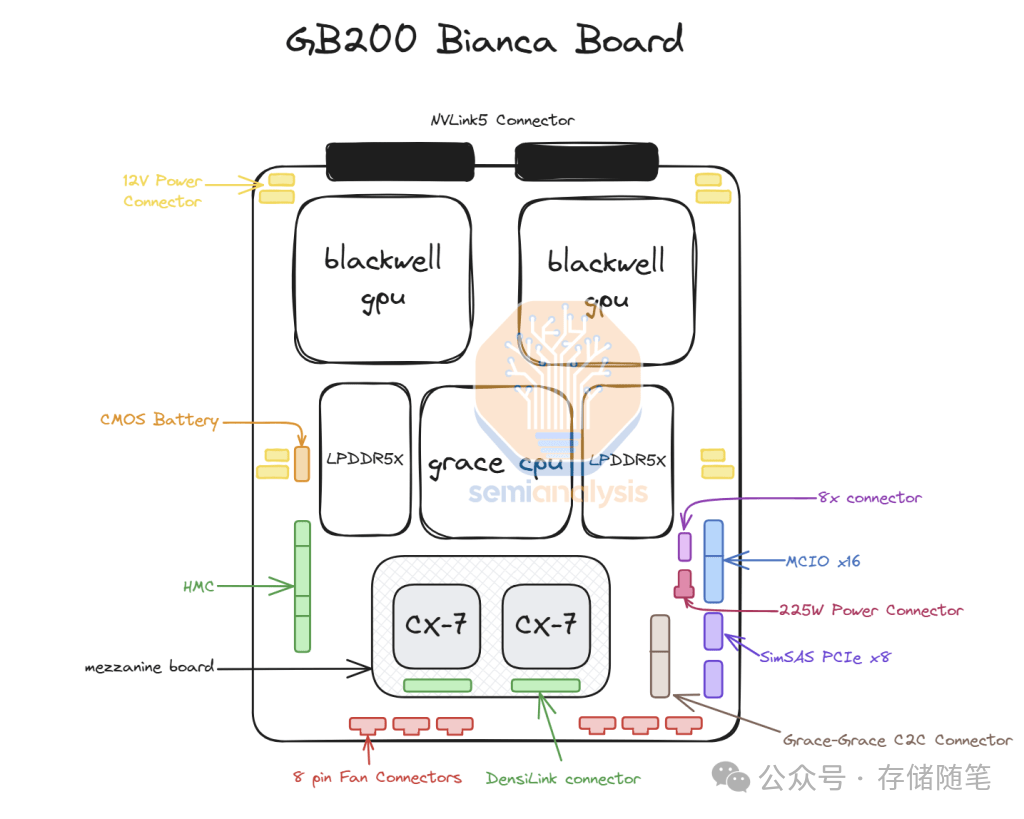
NVIDIA将只提供B300 GPU作为“SXM Puck”模块,而不是整个Bianca板。这种转变使得更多的OEM和ODM能够参与到计算模块的生产中来。Grace CPU将以BGA封装形式单独提供,不再集成在Bianca板上。高带宽内存(HBM)控制器(HMC)将由美国初创公司Axiado提供,取代了GB200上的Aspeed产品。
在GB200时代,NVIDIA选择了直接焊接在Bianca板上的512GB LPDDR5X作为主存方案。然而,在GB300的设计中,为了提高灵活性并降低成本,NVIDIA决定二级内存采用可插拔式的LPCAMM模块来替代传统的焊接内存,美光科技将成为这些模块的主要供应商。这一变化不仅简化了制造过程,还允许用户根据具体需求灵活配置内存容量和类型。
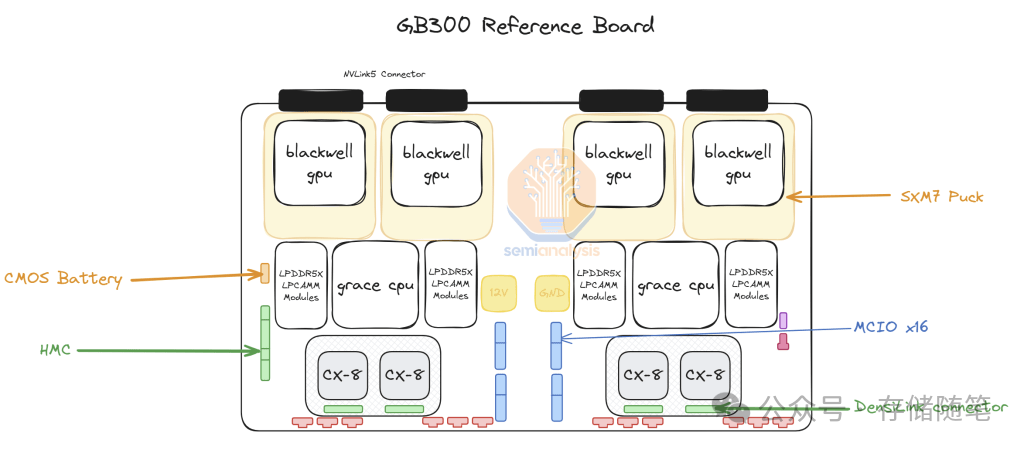
LPCAMM采用了标准化接口,使得不同供应商提供的内存模块可以互换使用,增强了供应链的多样性。由于是独立模块,未来如果需要增加或更换内存时,只需替换相应的LPCAMM模块即可,无需重新设计整个电路板。
相比焊接式内存,LPCAMM模块可以通过专门设计的散热器进行更有效的冷却,有助于提升系统的稳定性和性能。通过减少定制化硬件的需求,降低了整体生产成本,同时也为客户提供了一个更具性价比的选择。
| 参数 |
GB200 (LPDDR5X) |
GB300 (LPCAMM) |
| 内存类型 |
焊接式 |
可插拔式 |
| 容量 |
固定512GB |
根据需求灵活配置 |
| 接口标准 |
直接焊接 |
标准化CAMM接口 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











