







 本文深入探讨了FCN(全卷积网络)在图像语义分割中的应用,介绍了FCN如何通过全卷积层转换和上采样技术解决传统CNN在语义分割上的问题。FCN的优势在于接受任意大小输入并提高效率,但其结果不够精细,缺乏空间一致性。文章还涵盖了FCN的实现细节和优缺点,并提供了基于Caffe的代码实现链接。
本文深入探讨了FCN(全卷积网络)在图像语义分割中的应用,介绍了FCN如何通过全卷积层转换和上采样技术解决传统CNN在语义分割上的问题。FCN的优势在于接受任意大小输入并提高效率,但其结果不够精细,缺乏空间一致性。文章还涵盖了FCN的实现细节和优缺点,并提供了基于Caffe的代码实现链接。
在图像处理领域,图像的分割主要考虑像素灰度的变化,区分不同的前后景。之前的一个系列《图像分割技术(1)》对主流算法做了概述
图像的语义分割则不仅是区分每个像素的前后景,更需要将其所属类别预测出来,属于计算机视觉领域
CNN做图像分类甚至做目标检测的效果已经被证明并广泛应用,图像语义分割本质上也可以认为是稠密的目标识别(需要预测每个像素点的类别)
传统的基于CNN的语义分割方法是:将像素周围一个小区域作为CNN输入,做训练和预测。这样做有3个问题:
- 像素区域的大小如何确定
- 存储及计算量非常大
- 像素区域的大小限制了感受野的大小,从而只能提取一些局部特征
基于此,Berkeley团队提出 Fully Convolutional Networks(FCN)方法用于图像语义分割,将图像级别的分类扩展到像素级别的分类(图1),获得 CVPR2015 的 best paper
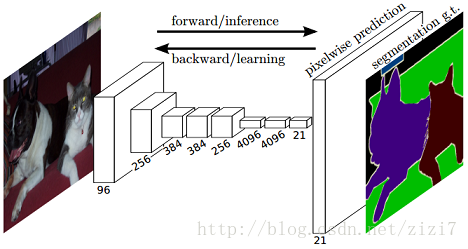
图1. FCN实现了 end-to-end 的图像语义分割
文章《【总结】图像语义分割之FCN和CRF》 认为,发展到现在,基于深度学习的图像语义分割“通用框架已经确定”:前端 FCN(包含基于此的改进 SegNet、DeconvNet、DeepLab)+ 后端 CRF/MRF (条件随机场/马尔科夫随机场)优化
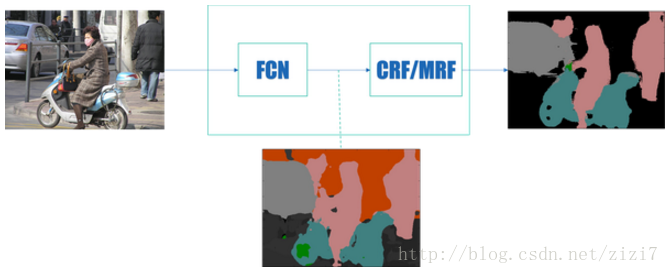
图2. 图像语义分割通用框架(摘自这里)
FCN原理
一句话概括就是:FCN将传统网络后面的全连接层换成了卷积层,这样网络输出不再是类别而是 heatmap;同时为了解决因为卷积和池化对图像尺寸的影响,提出使用上采样的方式恢复
全卷积层的转换
以 CaffeNet(参考这篇文章)为例(图3),重点关注最后3个全连接层 FC6、FC7、FC8
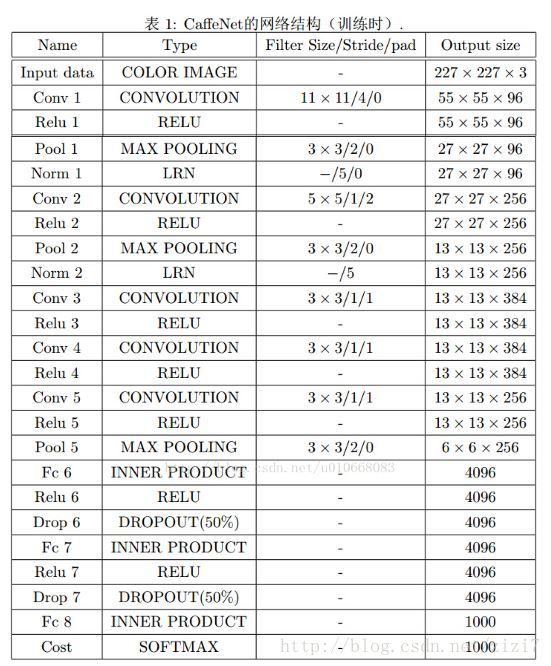
图3. CaffeNet 网络结构
- 对于FC6,使用尺寸为 6∗6∗4096 的卷积核,输出为 1∗1∗4096
- 对于FC7,使用尺寸为 1∗1∗4096 的卷积核,输出为 1∗1∗4096
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1478
1478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









