







图的深度学习近年来引起了人们的极大兴趣。然而,大多数工作都集中在(半)监督学习上,导致了标签依赖严重、泛化能力差、鲁棒性弱等缺点。为解决这些问题,自监督学习(SSL)通过精心设计的伪装任务提取信息性知识,而不依赖人工标签,已成为图数据的一种有前途和趋势的学习范式。与计算机视觉和自然语言处理等其他领域的SSL不同,图形上的SSL具有独特的背景、设计思想和分类方法。在图自监督学习的框架下,对对图数据采用SSL技术的现有方法进行了及时和全面的回顾。构建了一个统一的框架,从数学上形式化了graph SSL的范式。根据前置任务的目标,将这些方法分为4类:基于生成的方法、基于辅助属性的方法、基于对比的方法和混合的方法。进一步描述了graph SSL在各个研究领域的应用,并总结了graph SSL常用的数据集、评估基准、性能比较和开源代码。最后,讨论了该研究领域仍然存在的挑战和潜在的未来发展方向
图的深度学习缺点:
首先,人工标注标签的收集和标注成本过高,特别是对于具有大规模数据集(如引文和社交网络[9])或需要领域知识(如化学和医学[10])的研究领域。其次,由于过拟合问题,纯监督学习场景通常泛化能力较差,特别是当训练数据是稀缺的[11]时。第三,有监督的图深度学习模型易受标签相关的对抗攻击,导致图监督学习[12]鲁棒性弱
为了解决这些问题,自监督学习(SSL)通过巧妙设计前置任务(pretext tasks)提取信息知识,而不依赖手工标签的方式,逐渐成为一种有效且具有潜力的图数据学习范式。本文基于图结构的自监督学习的独特属性,对相关SSL范式进行了形式化,并根据前置任务将算法分为四类(如图2所示):
- 基于生成的模型(generation-based)
- 基于属性的模型(auxiliary property-based)
- 基于对比的模型(contrast-based)
- 混合模型(hybrid approaches)
并分别描述了图自监督学习的应用、数据集、评估标准、开源项目以及未来发展方向等内容。

相关术语:
Manual Labels Versus Pseudo Labels.一般情况下,伪标签的获取成本比手工标签低,在手工标签难以获取或数据量大的情况下具有优势。在自我监督学习设置中,可以设计特定的方法来生成伪标签,增强表征学习
Downstream Tasks Versus Pretext Tasks 下游任务是图分析任务,用于评估不同模型学习到的特征表示的质量或性能。典型应用包括节点分类和图分类。
前置任务是指为模型解决任务,比如图重建任务,而预先设计的任务,它帮助模型从无标记数据中学习更通用的表示,从而通过提供更好的初始化或更有效的正则化来惠及下游任务。通常,解决下游任务需要人工标签,而前置任务通常使用伪标签进行学习
3 框架和分类
在本节中,我们提供了graph SSL的统一框架,并从不同的角度对其进行了分类,包括前置任务、下游任务以及两者的结合(即自监督训练方案)。
3.1统一的图自监督学习框架和数学公式
我们构造了一个编码器-解码器框架来形式化图形SSL。


我们根据等式指定了四种graph SSL变体
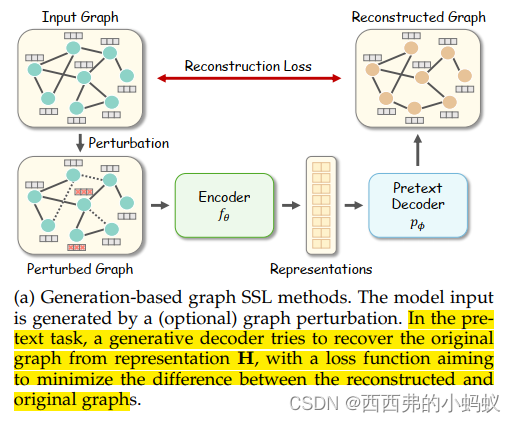
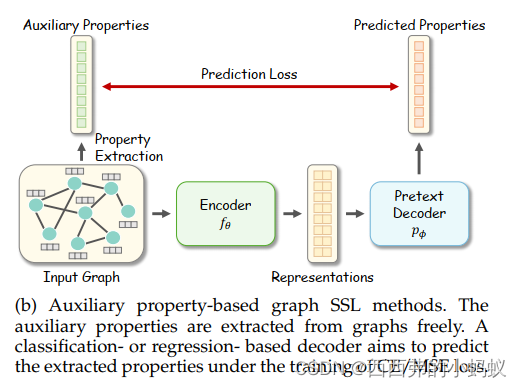
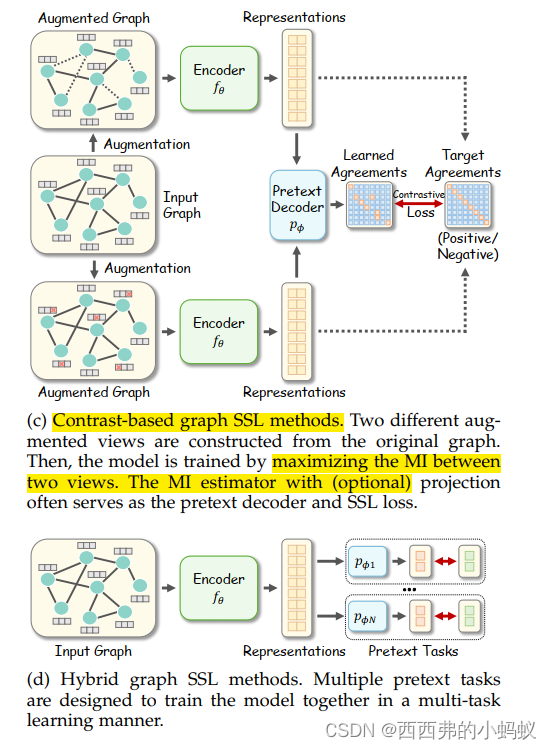
3.2 Taxonomy of Graph Self-supervised Learning
通过利用不同的伪装解码器和目标函数设计,Graph SSL在概念上可以分为四种类型,包括基于生成的、基于辅助属性的、基于对比的和混合的方法。
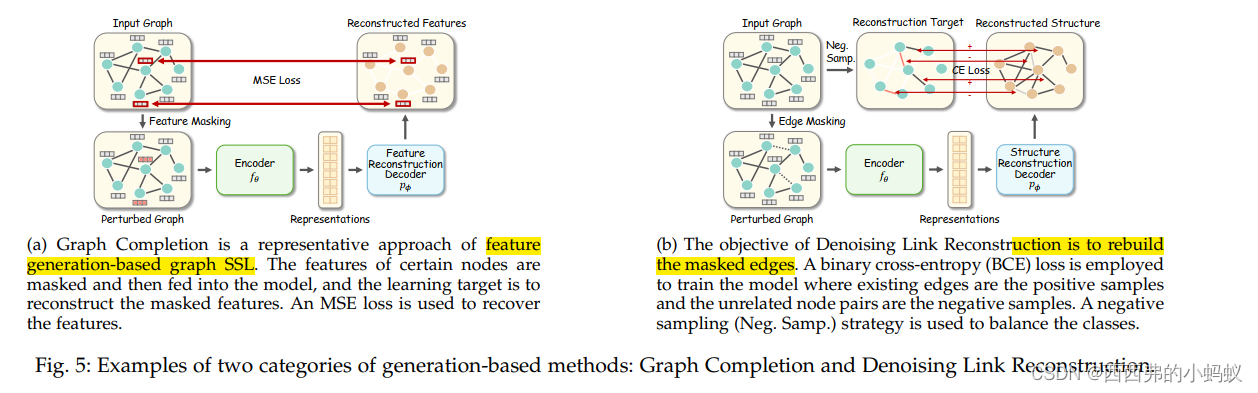
Generation-based Methods
从特征和结构两个角度将前置任务构成图数据重构。具体来说,它们专注于节点/边缘特征或/和图邻接性重建。


利用更大的属性图和拓扑图属性集来丰富监督信号,并进一步分为:基于回归的和基于分类的方法。


基于互信息(MI)最大化概念,最大化正对,最小化负对。

不同的图SSL方法有不同的属性:
基于生成:实现简单,构建容易,但耗内存;
基于属性:解码器和损失函数清晰,但属性的选择依赖知识与经验;
基于对比:设计更加灵活,应用广泛,但框架、增强策略和损失函数的设计依赖于实验(耗时);
混合方法:受益于多种前置任务,但如何平衡各组成部分仍然是一个挑战。
3.3自我监督培训方案的分类
根据图编码器、自监督前置任务和下游任务之间的关系,研究了3种类型的图自监督训练方案:预训练和微调(PF)、联合学习(JL)和无监督表示学习(URL)。图4给出了它们的简要管道
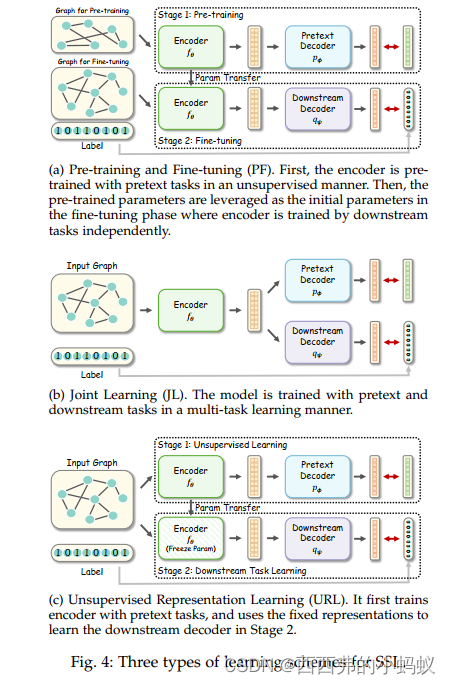
Pre-training and Fine-tuning (PF)
预训练和微调(PF)。首先,以无监督的方式利用前置任务对编码器进行预训练。然后,将预训练参数作为微调阶段的初始参数,其中编码器由下游任务独立训练


4 GENERATION-BASED METHODS
根据重构对象的不同,文章将该类别工作分为两类:
- 特征生成:学习重构图的特征信息
- 结构生成:学习重构图的拓扑结构信息


5 AUXILIARY PROPERTY-BASED METHODS
它们的区别在于标签的获取方式:在监督学习中,人工标注的标签需要人工标注,成本往往很高;在基于辅助属性的SSL中,伪标签是自动生成的,不需要任何代价



4.3 回归
回归与分类相比,最大的区别在于辅助属性是一定范围内的连续值,而不是有限集合内的离散伪标签。
5.2 Graph Contrastive Learning
对比学习的目的是最大化具有相似语义信息的实例之间的MI,因此可以构造不同的前置任务来丰富来自这些信息的监督信号。现有工作可以分为两大主流:同尺度对比学习和跨尺度对比学习。前者以相等的比例区分图实例(如节点-节点),而后者将对比放在多个粒度上(如节点-图)。图8展示了方法流程。
按照第3.2.3节中定义的基于对比的图SSL分类法,本文从三个角度调查了这一方法分支:(1)生成各种图实例的图增强;(2)图对比学习,在非欧氏空间上形成各种对比前置任务;(3)衡量实例间互信息的互信息估计,与特定的前置任务共同形成对比学习目标。
5.2.1 Graph Augmentations
图7展示了五种具有代表性的增广策略的例子。

5.2.2 Graph Contrastive Learning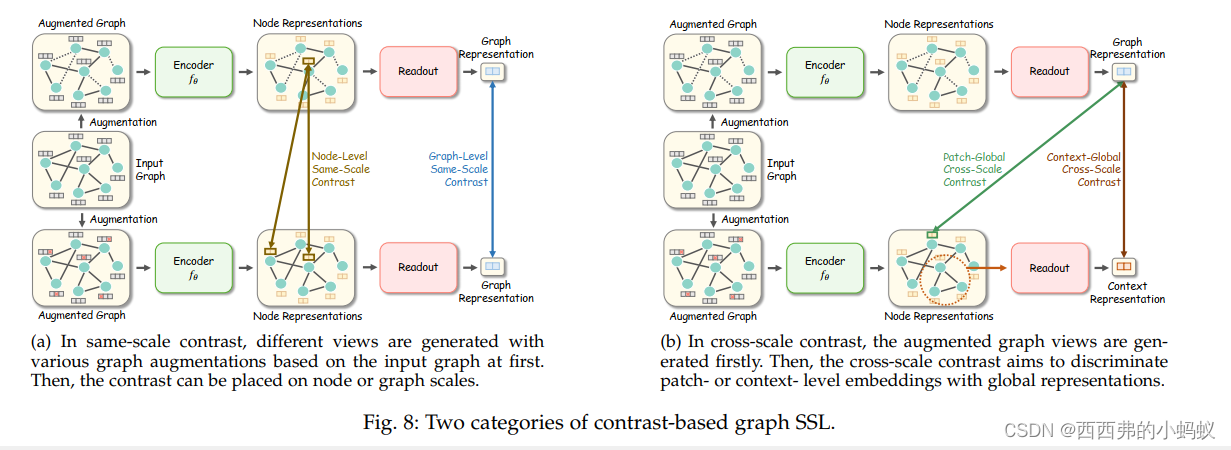
根据对比尺度,我们将相同尺度的对比学习方法进一步划分为两个子类型:节点级和图级。
6.2.1.1 Node-Level Same-Scale Contrast:

7 HYBRID METHODS
与前述仅利用单个前置任务训练模型的方法相比,混合方法采用多个前置任务来更好地发挥各类监督信号的优势。混合方法以多任务学习的方式将各种前置任务集成在一起,其中目标函数是两个或多个自监督目标的加权和

8. Empirical Study
文章总结了图表SSL实证研究的必要资源:对图学习中两种常用的下游任务,即节点分类和图分类的代表性方法进行了实验比较;为实证研究收集有用的资源,包括基准数据集和开源实现。
9. Practical Applications
图自监督学习应用在社会的多个方面,结合9.6提到的应用场景的future direction,目前常见的领域主要包括三个:推荐系统,异常检测,以及化学。
推荐系统领域,每个用户可以看做一个节点,那么图自监督学习可以为用户和商品构成的网络进行最优匹配,以及建模等工作,从而利用他们的潜在链接产生高质量的推荐。
异常检测领域,由于缺乏标注,图异常检测可以通过对特征和结构进行提取与分析,在无监督场景下进行异常捕获。通常该领域采用对比学习,混合模型以及辅助属性这三种主要类别方法。
9. Future Directions
9.1 Theoretical Foundation
尽管在各种任务和数据集上取得了巨大的成功,图SSL仍然缺乏一个理论基础来证明它的有效性。现有的方法大多采用直觉设计,并通过实证实验进行评价。虽然MI估计理论支持了一些关于对比学习的工作,但MI估计器的选择仍然依赖于实证研究。迫切需要为图形SSL建立一个坚实的理论基础,来弥合经验SSL和基本图理论之间的差距,如图信号处理和谱图理论。
9.2 Interpretability and Robustness
图SSL应用程序可能是风险敏感和隐私相关的,例如欺诈检测,需要一个可解释的,鲁棒的SSL框架以适应学习场景。然而,大多数现有的图SSL方法仅旨在通过黑盒模型在下游任务中获得更高的性能,忽略了学习表示和预测结果的可解释性。此外,除了一些考虑鲁棒性问题的开创性工作,大多数图SSL方法假设输入数据是完美的,但是现实中的数据经常是有噪声的,导致gnn容易受到敌对攻击。
9.3 Pretext Tasks for Complex Types of Graphs
目前的大多数工作集中于用于属性图的SSL,只有少数关注于复杂的图类型,例如异构或时空图。对于复杂的图,主要的挑战是如何设计借口任务来捕捉这些复杂图的独特数据特征。现有的一些方法使用MI最大化进行复杂图学习,其利用数据丰富信息的能力有限,例如时空/动态图中的时间动态。未来可以尝试为复杂的图数据生成各种SSL任务,或将SSL扩展到更普遍的图类型(例如超图)。
9.4 Augmentation for Graph Contrastive Learning
在CV的对比学习中,大量的增强策略(包括旋转、颜色扭曲、裁剪等)提供了不同的图像数据视图,在对比学习中保持了表示不变性。然而,由于图结构数据的性质,如非欧几里得结构,图上的数据增强方案没有得到很好的探索。现有的大多数图增广算法都考虑了均匀掩盖/变换节点特征、修改边缘或其他替代方法,如子图采样和图扩散,这些方法在生成多个图视图时,多样性有限,不确定不变性。为了填补空白,通过挖掘丰富的底层结构和属性信息,自适应地执行图增强、自动选择增强或联合考虑更强的增强样本将是进一步研究的有趣方向。
9.5 Learning with Multiple Pretext Tasks
现有图SSL方法通过解决一个前置任务来学习表示,而只有少数混合方法探索多个前置任务的组合。从之前的NLP训练前模型和综述的混合方法中可以看出,集成不同的任务可以从不同的角度提供不同的监督信号,这有利于图SSL方法产生更多的信息表示。因此可以考虑多前置任务多样性和适应性组合的混合方法。














 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









