







在深度q学习等基于值的强化学习方法中,众所周知,函数逼近误差会导致值估计过高和策略次优。该问题在actor-critic环境中仍然存在,并提出了新的机制来最小化其对actor和critic的影响。该算法建立在双q学习的基础上,通过取一对批评之间的最小值来限制高估。本文得出了目标网络和过估计偏差之间的联系,建议延迟策略更新,以减少每次更新误差,进一步提高性能。在OpenAI gym任务套件上评估了所提出方法,在每个测试环境中都优于最先进的方法。
背景:
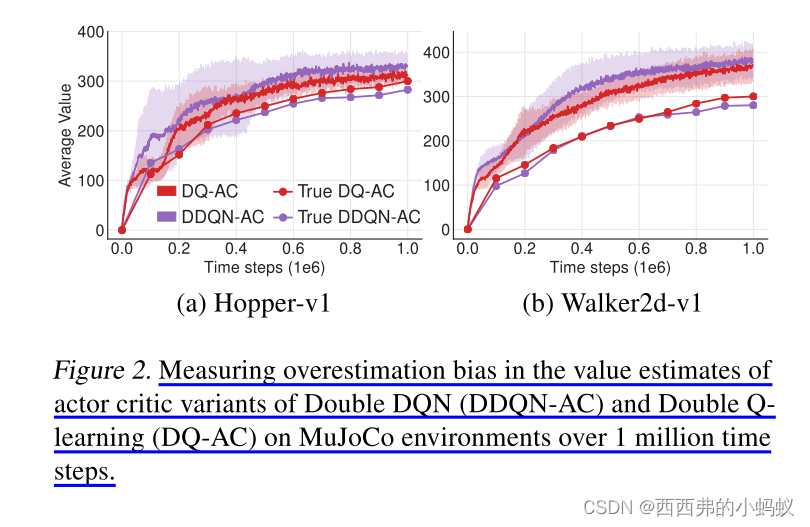
1)在这篇论文中,我们展示了在行动者-批评者的设置下,时间差分方法的高估偏差和误差累积。
2)在函数逼近设置中,由于估计器的不精确,噪声是不可避免的。由于高估偏差,这种累积的错误会导致任意糟糕的状态被估计为高值,从而导致次优的策略更新和发散的行为。
4.1. Overestimation Bias in Actor-Critic


















 4291
4291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









