







GNN-RAG arxiv: GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning

https://arxiv.org/abs/2405.20139
源码:https://github.com/cmavro/GNN-RAG
明尼苏达大学,公立常春藤
现在还挂载arxiv上
重点:GNN,RAG,QA
主要过程:
- 给定问题,GNN在稠密的KG子图上抽取候选答案
- 从kg里找到 从问题实体出发,到候选答案实体 的最短路径,作为推理路径
- 转换推理路径为文本作为LLM+RAG的输入
GNN作为子图推理器,抽取重要的图信息
此外,本文还提出了一种抽取增强的技巧。
数据集:WebQSP,CWQ。
背景
KGQA
给定kg
G
\mathcal{G}
G,自然语言问题
q
q
q,KGQA任务目标是从
G
\mathcal{G}
G中找到一组正确的答案实体
{
a
}
∈
G
\{a\} \in \mathcal{G}
{a}∈G。
根据之前的研究 [Lan et al., 2022],训练时会给出question-answer pairs,但不提供真实的推理路径。
抽取和推理
KG太大了,所以对于问题
q
q
q要抽取个子图
G
q
\mathcal{G}_q
Gq。
抽取需要entity linking和neighbor extraction。
理想情况下,所有的正确答案都被子图
G
q
\mathcal{G}_q
Gq覆盖。
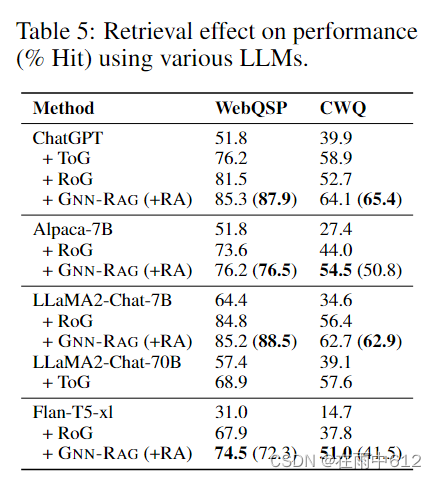
LLM-based Retriver
RoG(另一个RAG工作)抽取了从question entities到answers的最短路径,用于微调retriever。
基于抽取的路径,微调一个LLM(比如LLaMA2-Chat-7B)来生成给定问题
q
q
q下的推理路径:
LLM
(
prompt
,
q
)
⇒
{
r
1
,
→
⋯
r
t
}
k
\text{LLM}(\text{prompt},q) \Rightarrow \{r_1, \rightarrow \cdots r_t\}_k
LLM(prompt,q)⇒{r1,→⋯rt}k
方法
GNN:
训练时,给定question-answer pairs,把QA当成node- classification任务来训练(判断每个实体是answer还是 not answer),即L层GNN后获得每个实体的分数,然后打分。推理时,把超过一个分数阈值的实体都当成候选答案,并且给出每个answer对应的最短路径(从question entity到当前的answer)。
GNN的message-passing过程:
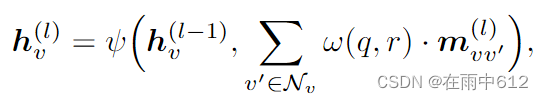
ω
\omega
ω是自定义的消息函数,例如神经网络。
 在实验中,本文没有尝试多种GNN架构,而是尝试神经网络的选择。
在实验中,本文没有尝试多种GNN架构,而是尝试神经网络的选择。
本文训了2个GNN,一个用的是预训练的
SBERT
\text{SBERT}
SBERT,一个用的是预训练的
LM
S
R
\text{LM}_{SR}
LMSR
LLM:
prompt如下

推理路径是前文说的,从question entities到answer entities的最短路。
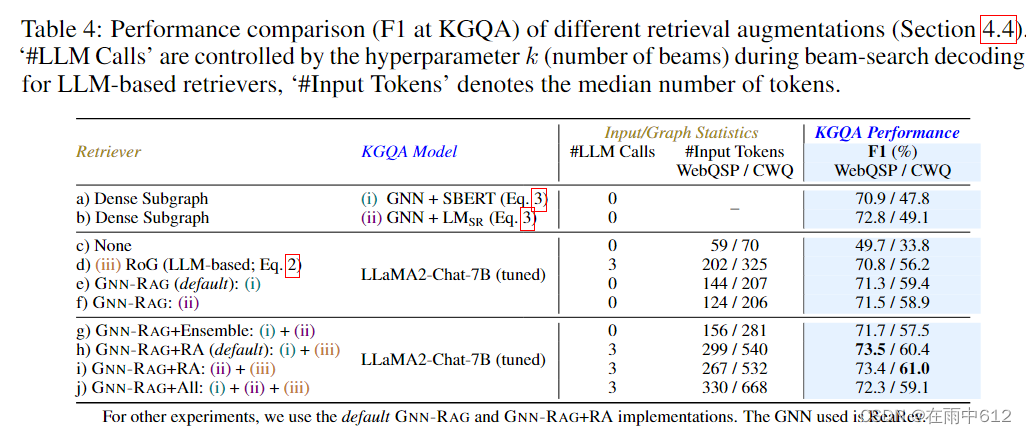
Retrieval Augmentation (RA)
GNN retriever 和 LLM-based retriever 结合,来抽取重要信息
实际使用中,GNN retriever抽取的路径、LLM-based抽取的路径结合起来传到LLM中
LLM-based retriver的缺点是,需要多轮生成。
不同的是,消融实验中,GNN-RAG+Ensemble用于抽取路径的两种GNN方案是:
- GNN \text{GNN} GNN+ SBERT \text{SBERT} SBERT
-
GNN
\text{GNN}
GNN+
LM
S
R
\text{LM}_{SR}
LMSR
只读取这两个GNN方法生成的路径,没有再调用LLM.
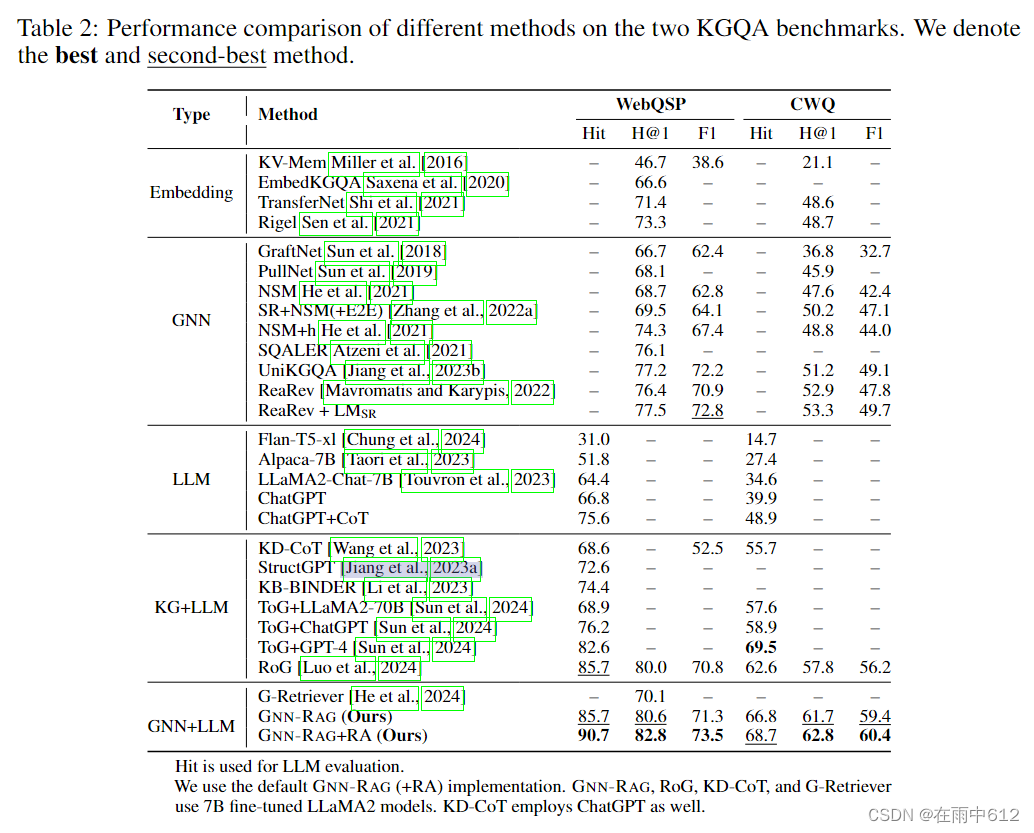
实验
KGQA数据集:WebQuestionSP(WebQSP),Complex WebQuestions(CWQ)。
WebQSP是基于Freebase的,最多2跳推理。
CWQ最多4跳推理。
实现细节:
使用linked实体和pargerank算法来抽取子图
GNN是ReaRev。

















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









