







 博主分享强化学习基础知识学习历程,后续会持续更新相关专栏。着重介绍了Discount factor,当trajectory步长无穷时引入该量避免算法分析难题,还阐述了其在TD方法和Monte Carlo中的情况,最终给出Actor - Critic算法。
博主分享强化学习基础知识学习历程,后续会持续更新相关专栏。着重介绍了Discount factor,当trajectory步长无穷时引入该量避免算法分析难题,还阐述了其在TD方法和Monte Carlo中的情况,最终给出Actor - Critic算法。
作为一个新手,写这个强化学习-基础知识专栏是想和大家分享一下自己学习强化学习的学习历程,希望对大家能有所帮助。这个系列后面会不断更新,希望自己在2021年能保证平均每日一更的更新速度,主要是介绍强化学习的基础知识,后面也会更新强化学习的论文阅读专栏。本来是想每一篇多更新一点内容的,后面发现大家上CSDN主要是来提问的,就把很多拆分开来了(而且这样每天任务量也小一点哈哈哈哈偷懒大法)。但是我还是希望知识点能成系统,所以我在目录里面都好按章节系统地写的,而且在github上写成了书籍的形式,如果大家觉得有帮助,希望从头看的话欢迎关注我的github啊,谢谢大家!另外我还会分享深度学习-基础知识专栏以及深度学习-论文阅读专栏,很早以前就和小伙伴们花了很多精力写的,如果有对深度学习感兴趣的小伙伴也欢迎大家关注啊。大家一起互相学习啊!可能会有很多错漏,希望大家批评指正!不要高估一年的努力,也不要低估十年的积累,与君共勉!
Discount factor
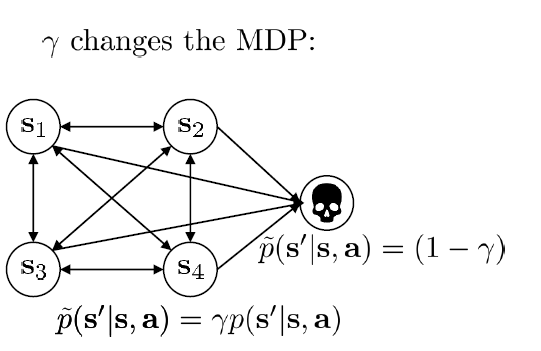
Discount factor其实在我们前面讲return(Goal函数)的时候就已经讲到了,当trajectory的步长变成无穷时,估计中就会出现无穷大量, 这就会导致算法整体难以分析。所以我们就引入discount factor这个量, 对后续的reward进行discount, 而避免无穷的问题:
在TD方法中, target可以转化为如下的形式:.
y
i
,
t
≈
r
(
s
i
,
t
,
a
i
,
t
)
+
γ
V
^
ϕ
π
(
s
i
,
t
+
1
)
y_{i, t} \approx r\left(\mathbf{s}_{i, t}, \mathbf{a}_{i, t}\right)+\gamma \hat{V}_{\phi}^{\pi}\left(\mathbf{s}_{i, t+1}\right)
yi,t≈r(si,t,ai,t)+γV^ϕπ(si,t+1)
据此得到gradient
∇
θ
J
(
θ
)
≈
1
N
∑
i
=
1
N
∑
t
=
1
T
∇
θ
log
π
θ
(
a
i
,
t
∣
s
i
,
t
)
(
r
(
s
i
,
t
,
a
i
,
t
)
+
γ
V
^
ϕ
π
(
s
i
,
t
+
1
)
−
V
^
ϕ
π
(
s
i
,
t
)
)
\nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N} \sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}\left(\mathbf{a}_{i, t} \mid \mathbf{s}_{i, t}\right)\left(r\left(\mathbf{s}_{i, t}, \mathbf{a}_{i, t}\right)+\gamma \hat{V}_{\phi}^{\pi}\left(\mathbf{s}_{i, t+1}\right)-\hat{V}_{\phi}^{\pi}\left(\mathbf{s}_{i, t}\right)\right)
∇θJ(θ)≈N1i=1∑Nt=1∑T∇θlogπθ(ai,t∣si,t)(r(si,t,ai,t)+γV^ϕπ(si,t+1)−V^ϕπ(si,t))
在Monte Carlo中,这个问题就有两种不同的情况:
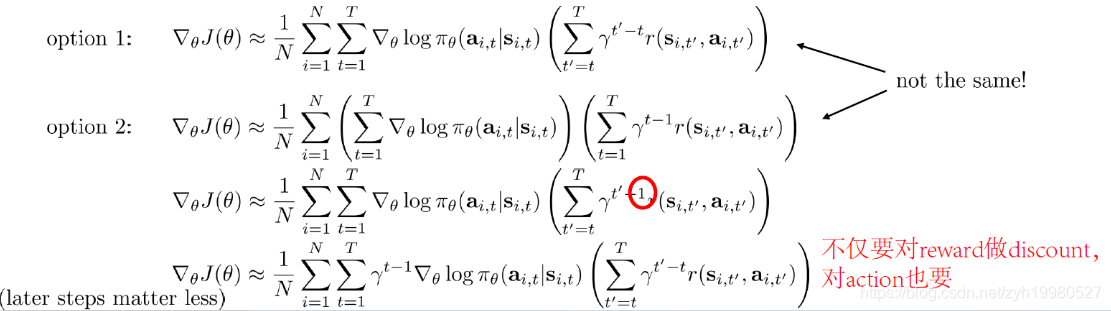
在第一种形式中,对causality后的reward从舍去部分开始计算discount,也就是说前面切掉的部分对discount的累乘没有影响。而第二种形式中,先引入了discount,再计算causality,故而对于被舍去的部分它的discount效应仍然存在,在这种情况下,越往后的steps的对结果的影响会相对第一种更小。
在实际中我们通常是使用第一种方式,因为对于后面的状态我们也是希望对网络有贡献的,如果factor过小,那么就会导致后面的状态一直不太准确,影响整体结果。
我们最终得到的Actor-Critic的算法为下图所示:前者采样一个batch再进行学习,后者按照单个样本进行学习,学完之后就把这个样本丢弃。

上一篇:强化学习的学习之路(三十七)_2021-02-06: Actor Critic - Evaluation for value function
下一篇:强化学习的学习之路(三十九)_2021-02-08: Actor Critic -Design Decisions


















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











