







深度学习
文章目录
前言
本篇介绍使用YOLOV9模型训练以及训练数据之后我们需要一些评判标准来告诉我们所训练的效果究竟如何,关于yolov9的一些简单说明,主要是txt文件、训练结果分析等的相关资料。
一、YOLO训练数据格式
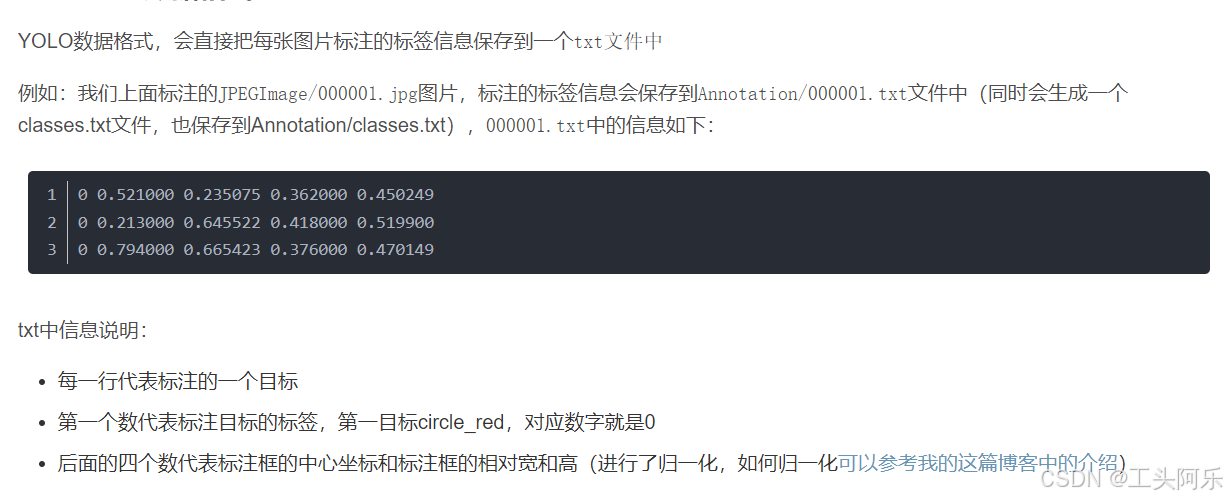
二、YOLO输入文件格式

三、训练不好的原因
- 欠拟合:
在训练集上表现很差,测试集上表现也很差的现象可能是欠拟合导致的,是因为泛化能力太强,误识别率较高解决办法:
1)增加数据集的正样本数, 增加主要特征的样本数量
2)增加训练次数
3)减小正则化参数 - 过拟合:
在训练集上表现很好,在测试集上表现很差(模型太复杂)解决办法:
1)增加其他的特征的样本数, 重新训练网络.
2)训练数据占总数据的比例过小,增加数据的训练量 - loss值不再变小就说明训练好了
四、训练结果文件分析

我们可以从结果文件中看到其中共有文件22个,后9张图片是根据我们训练过程中的一些检测结果图片,用于我们可以观察检测结果,有哪些被检测出来了,那些没有被检测出来,其不作为指标评估的文件。
1. Weights文件夹
我们先从第一个weights文件夹来分析,其中有两个文件,分别是best.pt、last.pt,其分别为训练过程中的损失最低的结果和模型训练的最后一次结果保存的模型。
2. hyp.yaml
保存了我们训练过程中的一些参数
3. args.yaml
保存一些我们训练时指定的参数
4. opt.yaml
这个文件里面包含了我们所有的参数,上面的yaml文件只包含了训练过程中的超参数,但是还有一些其他的参数类似于数据集的地址,权重地址,项目名称等一系列设置性参数
5. confusion_matrix.png(混淆矩阵)
混淆矩阵是一种用于评估分类模型性能的表格形式。它以实际类别(真实值)和模型预测类别为基础,将样本分类结果进行统计和汇总。
对于二分类问题,混淆矩阵通常是一个2×2的矩阵,包括真阳性(True Positive, TP)、真阴性(True Negative, TN)、假阳性(False Positive, FP)和假阴性(False Negative, FN)四个元素。
6. F1_curve:
F1分数与置信度之间的关系。F1分数(F1-score)是分类问题的一个衡量指标,是精确率precision和召回率recall的调和平均数,最大为1,最小为0, 1是最好,0是最差
7. labels.jpg
第一个图 classes:每个类别的数据量
第二个图 labels:标签
第三个图 center xy
第四个图 labels 标签的长和宽
8. labels_corrrelogram.jpg 目前不知道
9. P_curve.png :
准确率precision和置信度confidence的关系图
10. PR_curve.png:
PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。PR曲线下围成的面积即AP,所有类别AP平均值即Map.
如果PR图的其中的一个曲线A完全包住另一个学习器的曲线B,则可断言A的性能优于B,当A和B发生交叉时,可以根据曲线下方的面积大小来进行比较。一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好)
Precision和Recall往往是一对矛盾的性能度量指标;
提高Precision == 提高二分类器预测正例门槛 == 使得二分类器预测的正例尽可能是真实正例;
提高Recall == 降低二分类器预测正例门槛 == 使得二分类器尽可能将真实的正例挑选
11. R_curve.png :召回率和置信度之间的关系
results.csv记录了一些我们训练过程中的参数信息,包括损失和学习率等,这里没有什么需要理解大家可以看一看,我们后面的results图片就是根据这个文件绘画出来的。
12. results.png:
这个图片就是生成结果的最后一个了,我们可以看出其中标注了许多小的图片包括训练过程在的各种损失,我们主要看的其实就是后面的四幅图mAP50、mAP50-95、metrics/precision、metrics/recall四张图片。
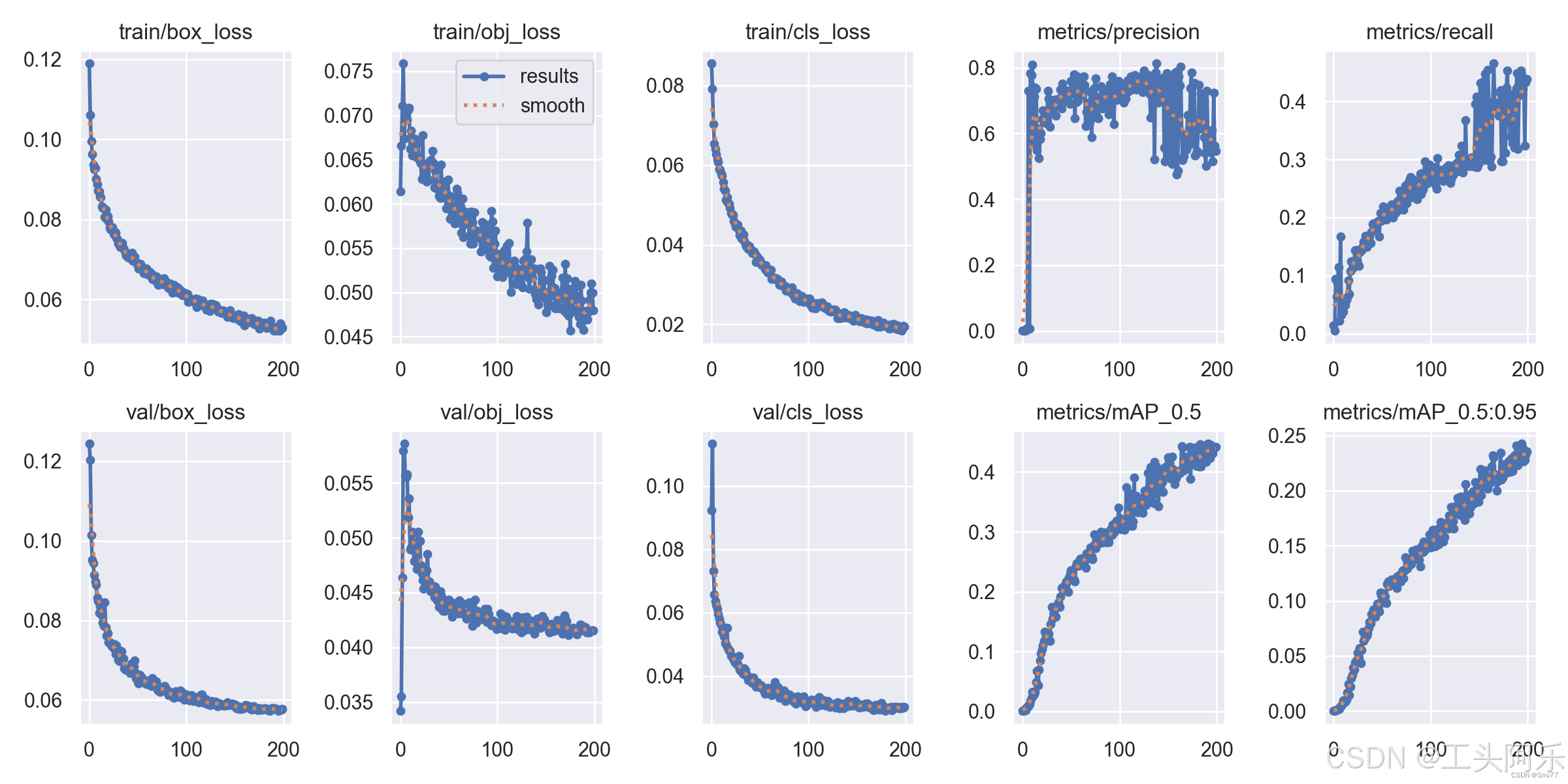
mAP50:mAP是mean Average Precision的缩写,表示在多个类别上的平均精度。mAP50表示在50%的IoU阈值下的mAP值。
mAP50-95:这是一个更严格的评价指标,它计算了在50-95%的IoU阈值范围内的mAP值,然后取平均。这能够更准确地评估模型在不同IoU阈值下的性能。
metrics/precision:精度(Precision)是评估模型预测正确的正样本的比例。在目标检测中,如果模型预测的边界框与真实的边界框重合,则认为预测正确。
metrics/recall:召回率(Recall)是评估模型能够找出所有真实正样本的比例。在目标检测中,如果真实的边界框与预测的边界框重合,则认为该样本被正确召回。
其它参数
FPS和IoU是目标检测领域中使用的两个重要指标,分别表示每秒处理的图片数量和交并比。
FPS:全称为Frames Per Second,即每秒帧率。它用于评估模型在给定硬件上的处理速度,即每秒可以处理的图片数量。该指标对于实现实时检测非常重要,因为只有处理速度快,才能满足实时检测的需求(推理速度有关系等于nms时间 +预处理时间 然后用1000除以这三个数就是fps,现在轻量化提高FPS是一个比较流行的发论文方向且比较简单一些)。
IoU:全称为Intersection over Union,表示交并比。在目标检测中,它用于衡量模型生成的候选框与原标记框之间的重叠程度。IoU值越大,表示两个框之间的相似性越高。通常,当IoU值大于0.5时,认为可以检测到目标物体。这个指标常用于评估模型在特定数据集上的检测准确度。
在目标检测领域中,处理速度和准确度是两个重要的性能指标。在实际应用中,我们需要根据具体需求来平衡这两个指标。
参考
[1] https://blog.csdn.net/weixin_46575013/article/details/142954825
[2] https://www.cnblogs.com/itzixueba/p/18410587


















 4556
4556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









