









前言:
DNC的论文上了Nature,对其中的NTM机制很不了解,还是得看一下NTM原始介绍。对原文意思理解稍微有点偏颇,如有异议,请拜访原文。原文链接:http://arxiv.org/pdf/1410.5401.pdf
NTM实现了简单思维逻辑在物理机制上的重现,从策略到机制的公理化,才是可信性的来源。NTM对存储进一步扩展,从LSTM的内部cell扩展到外部存储器,并对简单的底层逻辑进行底层机制上的重演。引入内存机制,实现从语法到语义的演进。
NTM的内存机制对于时序分析有天然的优越性,理论上时序模式识别和NLP方向应该比LSTM有更好的效果。
NTM的前身可以视为RNN:DNN演进结构Hsitory-之RNN
NTM的维基百科介绍:
此篇译文评论第一个评论里面给出一个翻译链接
翻译到了这个地方,有兴趣可以去看一下

本文参考链接:深度|NTM-Lasagne:基于Lasagne的神经图灵机函数库
0.Abstract摘要
1.Introduction简介
2. Foundational Research基础研究
2.1 Psychology and Neuroscience心理学和神经科学
工作记忆的概念在心理学中已经得到较为深入的研究,用来解释涉及到短期信息操作时的任务性能。其大致的画面是一个“中央执行器”聚焦于注意力和操作记忆缓存中的数据(Baddeley等, 2009)。心理学家已经广泛地研究了工作记忆的容量限制,通常使用信息“大块”的数量来量化,这种信息块可被轻松地唤醒/回忆(Miller,1956)。容量限制导致/使得,我们能够理解人类工作记忆系统中的结构性约束,但是在我们的工作中我们依然乐意执行的(记忆系统功能)。
2.2 Cognitive Science and Linguistics认知科学和语言学
历史性的,认知科学和语言学作为学科兴起,与人工智能学科几乎是同时的,并都深受计算机科学影响(Chomsky, 1956) (Miller, 2003)。他们的目的都是基于信息或符号处理来解释人的精神活动。早在20世纪80年代,两个领域都认为递归式和过程式(基于规则)符号处理是认知的最高级形式。并行分布处理 (PDP) 或者联结主义发生改变,抛弃符号处理隐喻而更青睐于对思考过程的所谓的“子集符号”描述(Rumelhart et al., 1986).
Fodor和Pylyshyn (Fodor and Pylyshyn, 1988) 发表了两个关于神经网络对认知模型的局限性的苛刻/深刻证明。他们首先指出联结理论无法处理变量绑定问题,(语义级别)即不能对指派/分配 数据结构中特定槽位(slot) 赋值 特定的数据。语言中,变量绑定是普遍现象,例如,当人说出或者翻译“Mary spoke to John”这种形式的句子的时候,会将Mary视为主语,John视为宾语,而“spoke to”则赋值为谓语。Fodor和Pylyshyn也讨论到 绑定定长输入域 的神经网络无法产生 像人类这样对变长结构处理的能力。作为这个论断的回应,神经网络研究者们,包括Hinton (Hinton, 1986), Smolensky (Smolensky, 1990), Touretzky (Touretzky, 1990), Pollack (Pollack, 1990), Plate (Plate, 2003), and Kanerva (Kanerva, 2009)在内,调研了在联接框架内可以支持变量绑定和变量结构 的特定机制。我们的架构借鉴、并增强了这项工作。
对变长结构的递归处理一直被认为是人类认知的特质。在过去十年里,语言学社区有一个论点使一些人对其他人产生了对抗,此问题是递归处理是否是“独特人类”产生语言独有的进化创新,是特别为语言准备的,此观点得到Fitch, Hauser, and Chomsky (Fitch等, 2005)等人支持。或者是否还有多种其他的变化来负责人类语言的进化,而递归处理早于语言出现(Jackendoff and Pinker, 2005)?不管递归处理的进化源头是什么,所有人都认为它是人类认知灵活性的核心。
2.3 Recurrent Neural Networks递归神经网络
递归神经网络(RNN)是一大类带有动态状态的机器;即是,它有 状态可以依靠输入状态和当前的内部状态进行演化。对比隐马尔可夫模型,这种同样包含动态状态的模型,RNN具有分布式的状态,因而有更大更富裕的存储能力和计算能力。动态状态十分关键,因为它给予了基于上下文的计算的可能性;在某一时刻给出的一个刺激信号能够改变后面特定时刻的网络行为。
我们的工作的一些其他重要前提还包括通过递归网络,构建注意力可微模型(Graves, 2013) (Bahdanau等, 2014)和程序搜索(Hochreiter等, 2001b)(Das等, 1992)。
3. Neural Turing Machines神经网络图灵机
神经网络图灵机架构包含两个基本组件:神经网络控制器和内存池。图1展示了NTM的一个高层逻辑流程图。像多数神经网络,控制器通过输入输出向量与外界交互,但不同于标准网络的是,它还与一个带有选择性读写操作的内存矩阵进行交互。类似于图灵机,我们将执行读写操作的网络输出称为“头/读写头”。
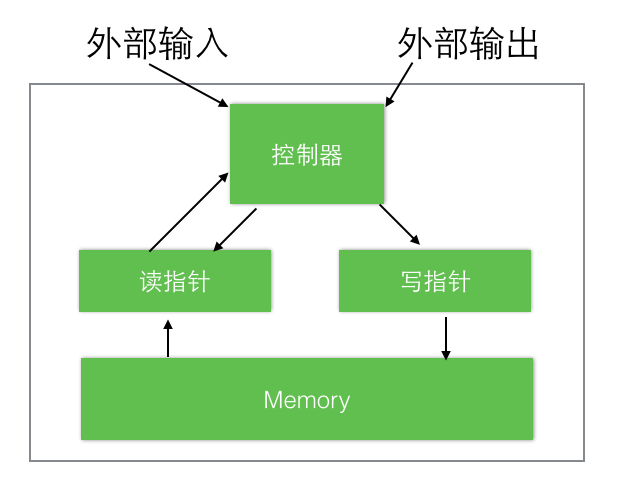
至关重要地是,架构中的每个组件都是可微分的,这可直接使用梯度下降训练。
为此,我们定义了“模糊”读写的概念,即可以通过更多或者更少的权重(可到达度)与内存中的全部元素进行交互(而不是单一元素寻址操作,通用图灵机和数字计算机中使用此操作)。“模糊度”的由注意力“聚焦”机制确定,此机制约束/限定 每一个读/写操作交互到 一小片内存,同时忽略其他部分。由于与内存的交互高度离散,NTM网络更偏向于/擅长存储数据同时很少受到干扰。带入注意力焦点的内存地址由读写头上的特定输出决定。这些输出定义了一个归一化的权值,通过内存矩阵的每一行(称为内存“地址集合”)。
每个读写头上附有的每一个权值,定义了它的读写头在各个地址的读写比重。由此,一个读写头,既可以精确访问单一地址,也可以弱定位在各个内存位置。
3.1 读
令M_t代表时刻t的N×M内存矩阵。(N代表地址数或行数,M代表每个地址的向量大小)。令W_t在时刻 t 读写头在 N 个地址的读写比重,由于所有的权重都进行了归一化,所以W_t向量的内部元素W_t(i)满足:
3.2 写
给定t时刻的写头权重w_t,以及一个擦出向量e_t,其中M个元素均在0~1范围内,则t-1时刻的内存向量Mt-1(i)在t时刻将按下式进行更新:
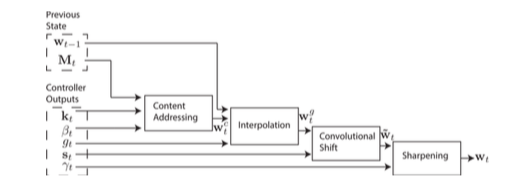
3.3 Addressing Mechanisms寻址机制
尽管前面我们显示了读写的公式,但我们没有说明权重是如何产生的。这些权重是由综合两种寻址机制及一些其他补充机制的共同作用产生的。第一种机制,“基于内容的寻址”,聚焦于(基于依据控制器提供的值与当前值的相似度来决定的)内存地址。这个机制与Hopfield网络(Hopfield, 1982)的地址寻址是相关的。基于地址寻址的优点是检索/定位非常简单,仅仅需要控制器产生一个与存储数据的一部分相似的数据即可,这个数据被用来与内存比较,然后产生的额外的提取存储值。
3.3.1 Focusing by Content按内容聚焦


3.3.2 Focusing by Location按位置聚焦
Prior to rotation, each head emits a scalar interpolation gate gt in the range (0; 1). The value of g is used to blend between the weighting wt
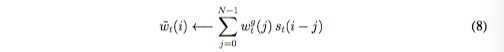
where all index arithmetic is computed modulo N. The convolution operation in Equation (8) can cause leakage or dispersion of weightings over time if the shift weighting is not sharp. For example, if shifts of -1, 0 and 1 are given weights of 0.1, 0.8 and 0.1, the rotation will transform a weighting focused at a single point into one slightly blurred over three points. To combat this, each head emits one further scalar t 1 whose effect is to sharpen the final weighting as follows:
其中,所有的索引算法时间复杂度为N,如果位移权重不是聚焦sharp的,那么公式8中的卷积操作能够导致权重随时间发散。例如,如果给-1,0,1的对应的权重0.1,0.8和0.1,则旋转就会将一个聚焦在一个点上的权重变成轻微模糊在三个点上。为了解决这个问题,每个读写头最后会给出一个标量γ_t ≥ 1用来sharpen最终的权重:
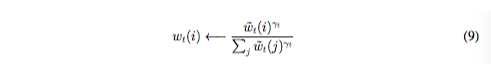
结合权重插值、内容寻址和地址寻址的寻址系统可以在三种补充模式下工作。第一,权重列表可以由内容系统来自主选择而不被地址系统所修改。第二,有内容系统产生的权重可以再选择和位移。这允许焦点能够跳跃到通过内容寻址产生的地址附近,而不是只能在其上。在计算方面,这使得读写头可以访问一个相邻/连续的数据块,并访问这个块中特定数据。第三,来自上一个时刻的权重可以在没有任何内容系统输入的情况下被旋转,以便权重可以以相同的时间间隔,连续地访问一个地址序列。
3.4 Controller Network控制网络
4. 实验
此节阐述了一些列的普通算法任务比如复制和排序数据序列。目的不仅是阐述确定NTM能够解决上述问题,而且能够通过学习压缩内部程序。这些解决方案的特质是他们超出了训练数据的界限。例如,我们更对这种事情好奇:是否这个网络框架能够被训练用于复制长度超过20的序列,在不增加更多训练(数据和过程)的情况下。
我们对比了三个结构:相对于前馈控制器、LSTM控制器、一个标准LSTM框架。因为所有的任务都是偶发性的,我们重组了每一个输入序列的初始状态。对于LSTM来说,这意味着,设定一个先前状态等价于学习一个向量偏置。所有的监督学习任务有两个目标:所有带有逻辑斯特回归输出层的网络使用交叉熵目标函数训练。序列预测错误以每序列多少bit的形式评价。试验更多的细节在4.6章节中。
4.1 复制任务--线性查找
复制任务用来测试NTM能否存储并回忆起一个任意信息的长序列。首先想网络输入一个任意二进制向量组成的序列,并跟随一个定界符。跨域长时间周期对信息进行存储和访问对RNN和其他动态架构来说一个难题。我们对NTM比LSTM是否能胜任更长的时间更有兴趣。
如图3所示,NTM( 使用前馈或者还是LSTM的控制器 )比LSTM本身学习的更快,消耗更小的学习代价。NTM和LSTM学习曲线的差距,足以戏剧性的说明这已经是质的不同,而不仅仅是量的不同。
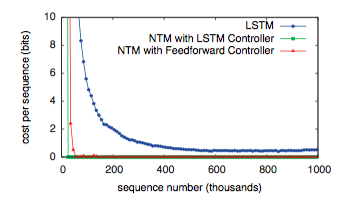
We also studied the ability of the networks to generalise to longer sequences than seen during training (that they can generalise to novel vectors is clear from the training error).Figures 4 and 5 demonstrate that the behaviour of LSTM and NTM in this regime is radically different. NTM continues to copy as the length increases2, while LSTM rapidly degrades beyond length 20.
我们研究了网络在训练过程不只是看到而是能否归纳更长的序列的能力(很显然他能否从训练错误中学习到在面对新的向量时要更加通用。)图4和图5说明这个过程中LSTM和NTM的行为是完全不同的。NTM能够随着长度的增加持续进行复制工作,而LSTM在超过20后迅速失效。
The preceding analysis suggests that NTM, unlike LSTM, has learned some form of copy algorithm. To determine what this algorithm is, we examined the interaction between the controller and the memory (Figure 6). We believe that the sequence of operations performed by the network can be summarised by the following pseudocode:
后续的分析表明,NTM不像LSTM能够学习到复制算法的某种形式。为了确定这是一种什么算法,我们查看了控制器与内存之间的交互信息(图6),最后确认网络所进行的操作序列可以总结成一下伪代码:
initialise: move head to start locationwhile input delimiter not seen doreceive input vectorwrite input to head location increment head location by 1end whilereturn head to start locationwhile true doread output vector from head locationemit outputincrement head location by 1
end while
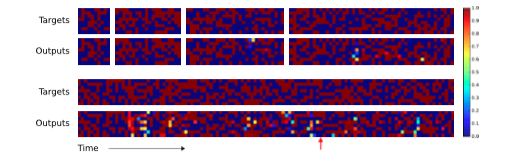
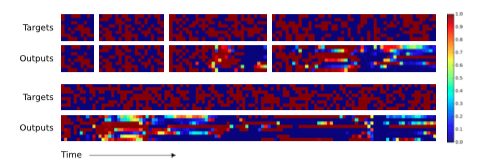
这实际上描述了人类程序员如何在执行相同任务时使用低级语言代码。从数据结构方面来说,NTM已经学会了如何创建和遍历数组/迭代数组。注意,该算法结合了内容寻址(跳到序列开始)和地址寻址(沿着序列移动)。还要注意到(如果没有基于前一时刻的读写权重进行修改相对位移的能力(公式7))迭代器也无法具有处理更长序列的能力,且如果如果没有焦点锐化/权重聚焦(focus-sharpening)能力(公式9)的话,权重就会随着时间的推移开始失真。
4.2 循环复制--循环
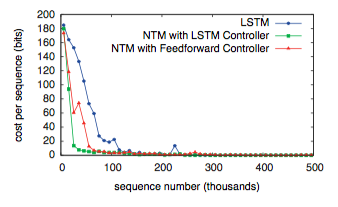
图7显示NTM学习这个任务比LSTM快得多,但两者都能完美的执行这个任务。在被问及针对训练数据的泛化时,两个架构的不同才变得清晰。这个案例中,我们对两个维度的泛化感兴趣:序列长度和重复次数。
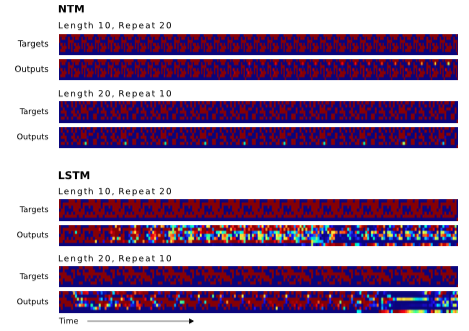
图8阐述了两次复制的效果,其中LSTM两个测试都失败了,而NTM在更长的序列上都成功了,并且能否成功执行超过十次;但是它不能记录他已经重复完成了多少次,所以无法正确地输出结束标记。这也许是因为使用小数表示循环次数的原因,因为在固定的范围它很难被泛化。
图9显示NTM学习了前面章节中一个复制算法的扩展,序列化读取被认为在必要时重复很多次。
4.3 Associative Recall 联想记忆--指向型
前面的任务展示了, NTM可以应用算法到相对简单、线性数据结构上。下一个复杂性就出现在带有“指针”数据的结构上——其中的项指向另一个。我们测试了 NTM 学习这类更加有趣的结构的实例上,通过构造一个项目列表,以此查询其中一个项目需要网络返回其后续的项目(查询指针指向的后续数列)。更详细地说,我们定义一个项目作为二元向量的序列(通过终止符来进行左右绑定)。在几个项目已经被反传给网络后,我们通过展示一个随机的项目进行查询,我们让网络生成这个项目的下一个元。在我们的实验中,每个项目包含3个 6 bit 的二元向量(总共就是 18 bit 每项目)。在训练的时候,在每个时间片段,我们使用最小 2 项目和最大 6 个项目。
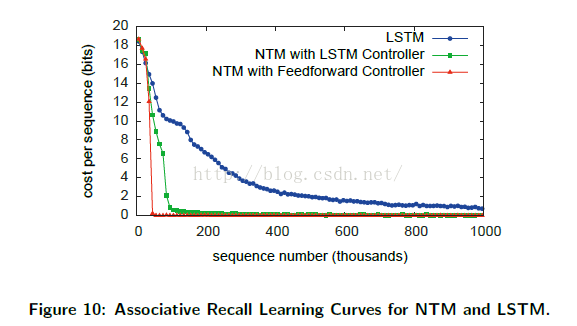
图 10 展示了 NTM学习的速度明显快于 LSTM,在接近 30,000 时间片段的时趋近于 0 的代价,而 LSTM 并没有在 100 万 时间片 后达到 0 的代价。此外,使用前驱控制器的 NTM 比使用 LSTM 控制器的 NTM 学习的速度更快。
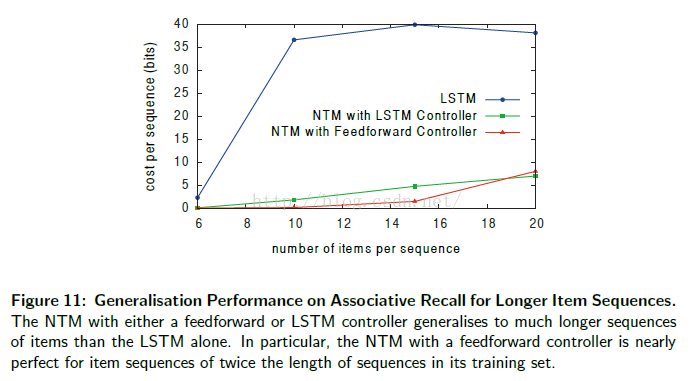
这两个结果表明与 LSTM 的内部存储相比, NTM 的外存的确是更加有效的一种维持数据结构的方式。NTM 同样比 LSTM 在更加长的序列上有着更好的泛化性能,可以在图 11 中看出。使用前驱控制器的 NTM 对 接近 12个项目(两倍于训练数据的最大长度)的情形下拥有接近完美的效果,且仍然处理 15 个项目的序列时,有低于每序列 1 bit 的平均代价。
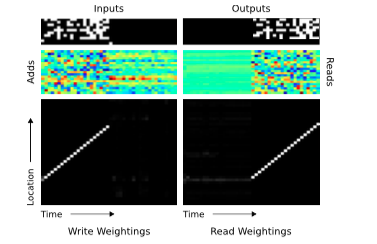
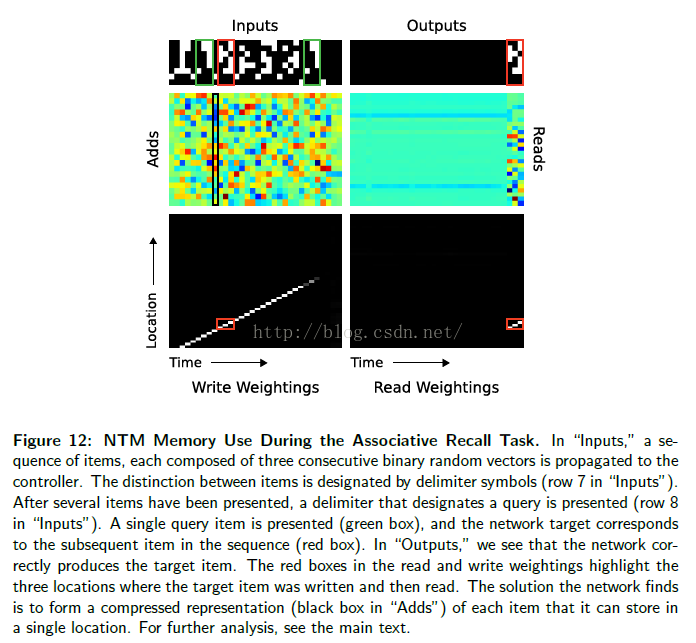
在图 12 中,我们展示了在一个单个测试时间片段内,通过一个 LSTM 控制读头的 NTM 内存操作。在“Inputs”中,我们看到输入代表项目的分隔符在第 7 行作为单一的 bit。在项目的序列被反传后,在第 8 行的一个分隔符让网络准备接受一个查询项目。这种情况下,查询项目对应于在序列中(在绿色盒子中)的第二个项目。在“Outputs”中,我们看到了网络给清楚地输出在训练中的项目 3 (在红色盒子中)。在“Read Weightings”中,在最后三个时间步,我们看到控制器从连续位置上读取了项目 3 存储的的时间分片。令人奇怪的是,因为看起来网络已经直接跳到正确的存储项目 3 的位置。然而,我们可以(通过查看“写权重”)解释这个行为。这里我们发现,内存甚至(在序列输入包含一个分隔符的时候)也进行了写操作。我们可以在“Add”确认这个数据实际上(在给定分隔符的时候)已经写入内存(比如,在黑色盒子中的数据);而且,每次分隔符出现,加入到内存中的向量是不同的。
更多的分析揭示出网络在通过使用基于内容的查找产生位移权值,获得了在读取后相应的位置后,移动到下一个位置。另外,使用内容查找的 key ,对应了添加到这个黑色盒子的向量。这其实展示了下面的内存存取算法:每个项目分隔符出现,控制器写入一个该项目的前三个时间片的压缩表示。当一个查询到达,控制器重计算同样的查询的压缩表示,使用基于内容的查找,来寻找第一次写表示的位置,然后偏移 1 位来产生后续的序列中的项目,这样就把基于内容的查找和基于位置的偏移结合起来。
4.4 Dynamic N-Grams动态N元文法描述
N元动态文法任务是为了测试NTM是否能快速地适应于新的预测分布。在一些时候,我们感兴趣데是,是否它能够作为一个可重写表(能够保持转移统计结果),通过模拟一个N元文法模型。
We considered the set of all possible 6-Gram distributions over binary sequences. Each 6-Gram distribution can be expressed as a table of 2^5 = 32 numbers, specifying the probability that the next bit will be one, given all possible length five binary histories. For each training example, we first generated random 6-Gram probabilities by independently drawing all 32 probabilities from the Beta( 1/2,1/2 ) distribution.
我们考虑了所有的在二进制序列中的所欲可能的6-Gram分布。每一个6-Gram分布能够表示为一个表(2^5=32个元素),这个表列出了所有可能长度为5的二进制历史序列下一个bit为1的概率。对于每一个训练样本,我们首先从Beta( 1/2,1/2 )分布中独立采样,所有32个概率中随机产生6-Gram的概率。
We then generated a particular training sequence by drawing 200 successive bits using the current lookup table[4]. The network observes the sequence one bit at a time and is then asked to predict the next bit. The optimal estimator for the problem can be determined by Bayesian analysis (Murphy, 2012):
我们生成特定的训练序列,通过当前查找表,采样200个按bit位产生的序列。网络一个观测一个bit位,然后预测下一个bit的值。问题的最优预测由贝叶斯决策决定(Murphy, 2012):
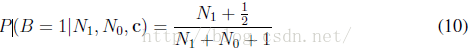
其中c为前束上下文中的5bit,B是下一个bit值,N0和N1表示目前为止,已经观测到的序列中的0和1的数目。我们因此可以对NTM和LSTM的最优预测子进行对比。为获得此对比结果,我们使用了一个1000게长度为200bit的序列验证集合,从相同데Beta分布中采样而来的,作为训练数据集合。正如Figure13中展示的,NTM得到了一个小的,但是更有明显更优的表现(相对于LSTM),但是仍然没有得到最优结果。
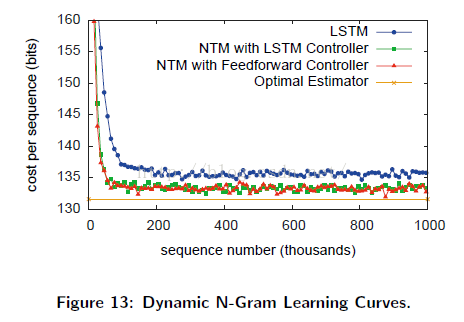

两种构架在观测新的输入时不断进化,结果在Figure14中显示,对比于最优预测。最近的NTM的内存使用分析,Figure15 显示控制器使用内存计数 多少 0 和 1 在不同的上下文中被观测到,允许 NTM执行 接近最优的算法。
4.5 Priority Sort优先级排序
此任务测试NTM是否能够完成数据排序——一个重要的基本算法。一个随机生成的二进制序列作为网络输入,并附加一个标量优先级。优先度为从[-1,1]中均匀采样,目标序列包含了通过优先级排序的所有二进制向量,描述在Figure16中。
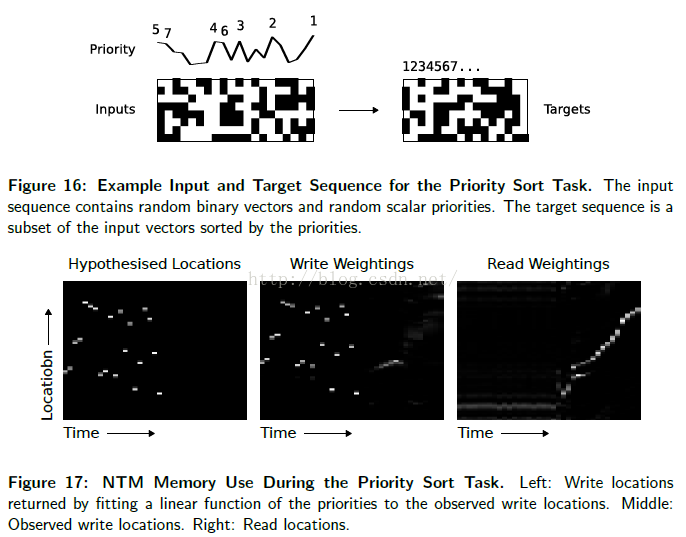
每个输入序列包含20게二进制向量集合(附带优先级),每个目标序列是16게最高优先级的向量[5]。查看NTM的内存使用,可以引领我们假设优先级决定레每一个相对데写位置。为验证这个假设,我们拟合레一个优先级线性方程(对于观测到的写位置)。FIgure17显示通过线性方程返回的写位置紧密地与写位置贴合。同样还展示了,网络是以增序方式读取内存,即是遍历已排序好的序列。
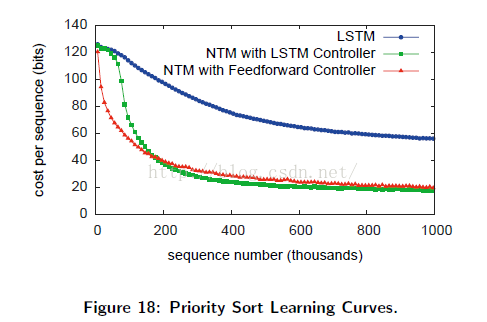
Figure18中的学习曲线显示了NTM(使用了前向控制器和LSTM控制器)都表现超过LSTM(在此任务上)。注意,8个并行读/写头(使用前向控制器的)具有最优的性能。这同时也反映出,使用一元向量对向量排序的困难。
4.6 试验细节
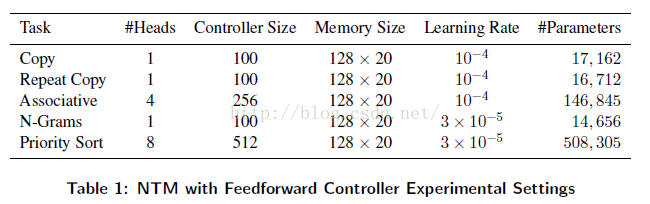
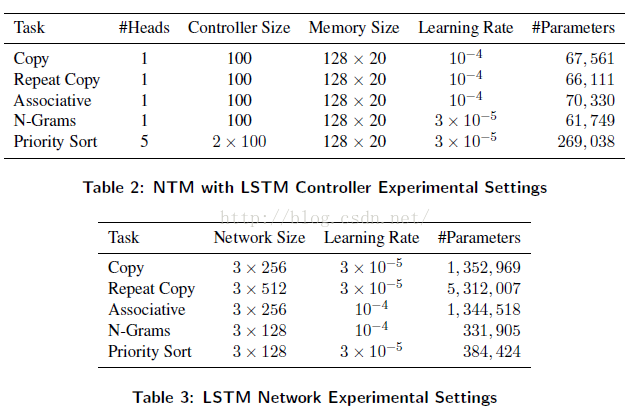
在所有的试验中,RMSProp算法用于模型训练(以描述在(Graves, 2013)的形式 ,使用momentum 为0.9)。 Tables 1到3 给出了细节关于,试验中的网络配置和使用的学习速率。所有데LSTM网络有三个堆叠隐藏层。注意,LSTM데参数以隐藏元的平方比率增长(因为隐藏层的递归链接)。对比于NTM ,NTM参数的数量并不会随着内存位置的数量增加而增加。在反传算法进行训练中,所有데梯度组分被限制到区间[-10,10]。
5. 结语
受生物学中工作记忆和数字计算机的设计启发,我们介绍了神经网络图灵机。跟传统神经网络一样,该架构是端到端可微的,可以被梯度下降算法训练。我们的实验证明,这个架构可以从样本数据中学会简单的算法,并可以很好地在训练框架之外应用这个学到的算法。
6 Acknowledgments
References
- Baddeley, A., Eysenck, M., and Anderson, M. (2009). Memory. Psychology Press. Bahdanau, D., Cho, K., and Bengio, Y. (2014). Neural machine translation by jointly
- learning to align and translate. abs/1409.0473.
- Barrouillet, P., Bernardin, S., and Camos, V. (2004). Time constraints and resource shar- ing in adults’ working memory spans. Journal of Experimental Psychology: General, 133(1):83.
- Chomsky, N. (1956). Three models for the description of language. Information Theory, IEEE Transactions on, 2(3):113–124.
- Das, S., Giles, C. L., and Sun, G.-Z. (1992). Learning context-free grammars: Capabil- ities and limitations of a recurrent neural network with an external stack memory. In Proceedings of The Fourteenth Annual Conference of Cognitive Science Society. Indiana University.
- Dayan, P. (2008). Simple substrates for complex cognition. Frontiers in neuroscience, 2(2):255.
- Eliasmith, C. (2013). How to build a brain: A neural architecture for biological cognition. Oxford University Press.
- Fitch, W., Hauser, M. D., and Chomsky, N. (2005). The evolution of the language faculty: clarifications and implications. Cognition, 97(2):179–210.
- Fodor, J. A. and Pylyshyn, Z. W. (1988). Connectionism and cognitive architecture: A critical analysis. Cognition, 28(1):3–71.
- Frasconi, P., Gori, M., and Sperduti, A. (1998). A general framework for adaptive process- ing of data structures. Neural Networks, IEEE Transactions on, 9(5):768–786.
- Gallistel, C. R. and King, A. P. (2009). Memory and the computational brain: Why cogni- tive science will transform neuroscience, volume 3. John Wiley & Sons.
- Goldman-Rakic, P. S. (1995). Cellular basis of working memory. Neuron, 14(3):477–485. Graves, A. (2013). Generating sequences with recurrent neural networks. arXiv preprint
- arXiv:1308.0850.
- Graves, A. and Jaitly, N. (2014). Towards end-to-end speech recognition with recurrent neural networks. In Proceedings of the 31st International Conference on Machine Learn- ing (ICML-14), pages 1764–1772.
- Graves, A., Mohamed, A., and Hinton, G. (2013). Speech recognition with deep recurrent neural networks. In Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on, pages 6645–6649. IEEE.
- Hadley, R. F. (2009). The problem of rapid variable creation. Neural computation, 21(2):510–532.
- Hazy, T. E., Frank, M. J., and O’Reilly, R. C. (2006). Banishing the homunculus: making working memory work. Neuroscience, 139(1):105–118.
- Hinton, G. E. (1986). Learning distributed representations of concepts. In Proceedings of the eighth annual conference of the cognitive science society, volume 1, page 12. Amherst, MA.
- Hochreiter, S., Bengio, Y., Frasconi, P., and Schmidhuber, J. (2001a). Gradient flow in recurrent nets: the difficulty of learning long-term dependencies.
- Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8):1735–1780.
- Hochreiter, S., Younger, A. S., and Conwell, P. R. (2001b). Learning to learn using gradient descent. In Artificial Neural Networks?ICANN 2001, pages 87–94. Springer.
- Hopfield, J. J. (1982). Neural networks and physical systems with emergent collective computational abilities. Proceedings of the national academy of sciences, 79(8):2554– 2558.
- Jackendoff, R. and Pinker, S. (2005). The nature of the language faculty and its implications for evolution of language (reply to fitch, hauser, and chomsky). Cognition, 97(2):211– 225.
- Kanerva, P. (2009). Hyperdimensional computing: An introduction to computing in dis- tributed representation with high-dimensional random vectors. Cognitive Computation, 1(2):139–159.
- Marcus, G. F. (2003). The algebraic mind: Integrating connectionism and cognitive sci- ence. MIT press.
- Miller, G. A. (1956). The magical number seven, plus or minus two: some limits on our capacity for processing information. Psychological review, 63(2):81.
- Miller, G. A. (2003). The cognitive revolution: a historical perspective. Trends in cognitive sciences, 7(3):141–144.
- Minsky, M. L. (1967). Computation: finite and infinite machines. Prentice-Hall, Inc. Murphy, K. P. (2012). Machine learning: a probabilistic perspective. MIT press.
- Plate, T. A. (2003). Holographic Reduced Representation: Distributed representation for cognitive structures. CSLI.
- Pollack, J. B. (1990). Recursive distributed representations. Artificial Intelligence, 46(1):77–105.
- Rigotti, M., Barak, O., Warden, M. R., Wang, X.-J., Daw, N. D., Miller, E. K., and Fusi, S. (2013). The importance of mixed selectivity in complex cognitive tasks. Nature, 497(7451):585–590.
- Rumelhart, D. E., McClelland, J. L., Group, P. R., et al. (1986). Parallel distributed pro- cessing, volume 1. MIT press.
- Seung, H. S. (1998). Continuous attractors and oculomotor control. Neural Networks, 11(7):1253–1258.
- Siegelmann, H. T. and Sontag, E. D. (1995). On the computational power of neural nets. Journal of computer and system sciences, 50(1):132–150.
- Smolensky, P. (1990). Tensor product variable binding and the representation of symbolic structures in connectionist systems. Artificial intelligence, 46(1):159–216.
- Socher, R., Huval, B., Manning, C. D., and Ng, A. Y. (2012). Semantic compositionality through recursive matrix-vector spaces. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Lan- guage Learning, pages 1201–1211. Association for Computational Linguistics.
- Sutskever, I., Martens, J., and Hinton, G. E. (2011). Generating text with recurrent neural networks. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), pages 1017–1024.
- Sutskever, I., Vinyals, O., and Le, Q. V. (2014). Sequence to sequence learning with neural networks. arXiv preprint arXiv:1409.3215.
- Touretzky, D. S. (1990). Boltzcons: Dynamic symbol structures in a connectionist network. Artificial Intelligence, 46(1):5–46.
- Von Neumann, J. (1945). First draft of a report on the edvac.
- Wang, X.-J. (1999). Synaptic basis of cortical persistent activity: the importance of nmda
- receptors to working memory. The Journal of Neuroscience, 19(21):9587–9603.















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









