







 本文介绍ICLR2016最佳论文DEEP COMPRESSION,通过网络剪枝、训练量化和哈夫曼编码压缩深度神经网络,降低参数量而不影响性能。在AlexNet和VGG-16上实验表明,压缩后参数显著减少,运行速度提升,能量消耗降低。
本文介绍ICLR2016最佳论文DEEP COMPRESSION,通过网络剪枝、训练量化和哈夫曼编码压缩深度神经网络,降低参数量而不影响性能。在AlexNet和VGG-16上实验表明,压缩后参数显著减少,运行速度提升,能量消耗降低。
DEEP COMPRESSION:
DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING
github 源码地址
Introduce
本篇论文是ICLR2016年的best paper,主要讲述关于深度学习网络参数的压缩工作。论文主要从下三点出发:
- pruning
- train quantization
- huffman coding
本文首先对网络进行剪枝,只保留重要的连接;第二步通过参数共享量化权重矩阵;第三步对量化值进行huffman编码,进一步压缩。整个网络在不影响性能的情况下,能够将参数量降低到原来的1/49~1/35。
在ImageNet数据集上,压缩后的网络的实验结果如下所示:
1. AlexNet在不影响精度的前提下,参数从240M减少到6.9M,35 ×
2. VGG-16在不影响精度的前提下,参数量从552M减少到11.3M,49 ×
3. 模型能够在DRAM运行。
4. 运行速度提高3-4倍。
5.消耗能量减少到原来的1/7~1/3。
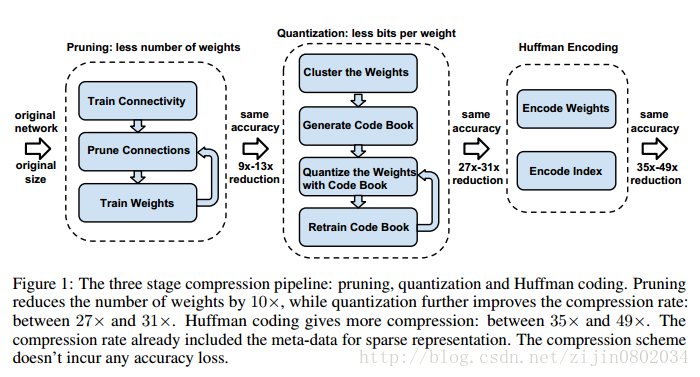
从图1可以看出网络的基本流程,首先移除冗余的连接,只保留权值比较大的连接,得到剪枝后的网络;第二步,权重进行量化,然后多个连接共享一个参数,只保存码本和索引;第三步,使用huffman编码,压缩量化的值。
Network pruning
在深度学习训练的过程中,会学到连接的参数。剪枝的方法也很简单,连接的权值小于一定阈值的直接移除,最终就得到了稀疏的网络连接。剪枝这一步骤能够将VGG-16(AlexNet)参数降低到原来的1/13(1/9)。
稀疏矩阵用compressed sparse row(CSR)和compressed sparse column(CSC)的格式进行压缩,总共需要2a+n+1个存储单元,a是非零元素个数,n是行数或者列数。
网络剪枝的过程如figure 2所示:

一个4*4的矩阵可以用一维16数组表示,剪枝时候,只保留 权值大于指定阈值的数,用相对距离来表示,例如idx=4和idx=1之间的位置差为3,如果位置差大于设定的span,那么就在span位置插入0。例如15和4之间距离为11大于span(8),所以在4+8的位置插入0,idx=15相对idx=12为3。这里span阈值在卷积层设置为8,全连接层为5。
Train Quantization And Weight Shared
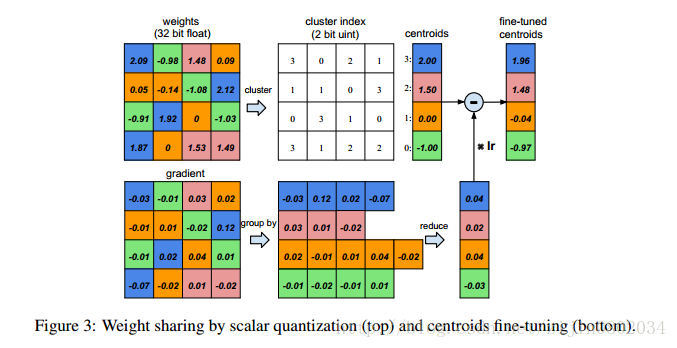
图3假定某层有4个输入单元4个输出单元,权重矩阵为4*4,梯度同样为4*4。假设权重被量化为4类,用四种颜色标识。用每类量化的值代表每类的权值,得到量化后的权值矩阵。用4个权值和16个索引就可以计算得到4*4权重矩阵连接的权值。梯度矩阵同样量化为4类,对每类的梯度进行求和得到每类的偏置,和量化中心一起更新得到新的权值。
压缩率计算方法如下公式所示:
公式(1)n代表连接数,b代表每一个连接需要b bits表示,k表示量化k个类,k类只需要用 log2(k) 个bit表示,n个连接需要 nlo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









