






一,Fast R-CNN
1,名词解释
1,似然性是从观测结果b出发,分布函数的参数为a的可能性大小;概率是在已知参数a的情况下,发生观测结果b可能性大小。最大似然估计可以说是应用非常广泛的一种参数估计的方法。原理是利用已知的样本,找出最有可能生成该样本的参数。
2,对数损失是用于最大似然估计的。一组参数在一堆数据下的似然值等于每一条数据在该组参数下的条件概率之积,而损失函数一般是每条数据的损失之和,为了把积变为和,就取了对数。再加个负号是为了让最大似然值和最小损失对应起来。
3,逻辑回归(Logistic Regression)是一种用于解决二分类(0 or 1)问题的机器学习方法,用于估计某种事物的可能性。得到的结果并非数学定义中的概率值,不可以直接当做概率值来用,而往往用于和其他特征值加权求和,而非直接相乘。
4,特征映射:当逻辑回归问题较复杂,原始特征不足以支持构建模型时,可以通过组合原始特征成为多项式,创建更多特征,使得决策边界呈现高阶函数的形状,从而适应复杂的分类问题。
5,softmax 的作用是把 一个序列,变成概率。
6,ROI(region of interest),感兴趣区域。从被处理的图像以方框、圆、椭圆、不规则多边形等方式勾勒出需要处理的区域,称为感兴趣区域。
7,偏移量,是指存储单元的实际地址与其所在段的段地址之间的距离称为段内偏移,也称为有效地址或偏移量。段地址左移四位,与有效地址相加,就构成了逻辑地址。一般而言,段地址是cpu自己独立编制的,但是偏移量是程序员编写的。偏移量就是程序的逻辑地址与段首的差值。
8,艾弗森括号(Iverson bracket),用来表示命题真假性到整数集 {0,1} 的映射:
书面形式:

数学形式:
![]()
9,L1 Loss(L1鲁棒损失,也称为平均绝对值误差(MAE))是指模型预测值f(x)和真实值y之间绝对差值的平均值,公式如下:
![]()
曲线分布如下:

L2 Loss(也称为均方误差(MSE)),是指模型预测值f(x)和真实值y之间差值平方的平均值,公式如下:
![]()
曲线分布如下:

Smooth L1 Loss(平滑L1鲁棒损失):L1,与L2的结合,公式如下:
![]()
曲线分布如下:


10,argmax:

11,对图像进行放大和缩小的变换的这个过程,称为尺度调整。
12,图像金字塔是图像多尺度调整表达的一种重要的方式,原理是:将参加融合的的每幅图像分解为多尺度的金字塔图像序列,将低分辨率的图像在上层,高分辨率的图像在下层。
13,SVD(奇异值分解,Singular Value Decomposition)是对矩阵进行分解
![]()

14,马尔科夫随机场(MRF):有向图,将图像模拟成一个随机变量组成的网格,便于分析因果关系。其中的每一个变量具有明确的对由其自身之外的随机变量组成的近邻的依赖性(马尔科夫性)。
15,级联在计算机科学里指多个对象之间的映射关系,建立数据之间的级联关系提高管理效率
16,准确率,精准率,召回率

2,特点
(1)流程:将一整张图像和一组目标建议作为输入。首先用几个卷积和最大池化层来处理整个图像,产生一个conv特征图。然后,针对每个目标提议,一个感兴趣区域(RoI)池化层从特征映射中提取一个固定长度的特征向量。每个特征向量被馈送到一个全连接层的序列中,最终分支成两个兄弟输出层:一个层对K个对象类和一个全面的“背景”类产生softmax概率估计,另一个层为K个对象类中的每个对象类输出K个类中的一个边界盒位置。
(2)训练是单阶段的,使用多任务损失。多任务训练避免了管理一系列顺序训练的任务。
(3)训练可以更新所有网络层。
(4)通过最小化置信度和边界盒回归的损失,可以对所有层进行端到端的微调
(5)通过RoI池层反向传播训练所有网络权值。
(6)使用随机梯度下降(SGD)小批量分层采样,在微调阶段共同优化softmax分类器和边界盒回归器
(7)使用截断奇异值分解。无需在模型压缩后执行额外的微调
二,SSD: Single Shot MultiBox Detector
1,名词解释
1,mAP(mean Average Precision)在机器学习中的目标检测领域,是十分重要的衡量指标,用于衡量目标检测算法的性能。一般而言,全类平均正确率(mAP,又称全类平均精度)是将所有类别检测的平均正确率(AP)进行综合加权平均而得到的。
2,Jaccard相似系数又称Jaccard系数,两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的Jaccard相似系数,用符号J(A,B)表示。
![]()
Jaccard相似系数是衡量两个集合相似度的一种指标。
又称IOU,全名为Intersection over Union,又称为交并比,IOU值越大,代表预测框和真实框的重叠面积越大,说明预测框预测的越为精准。
计算公式为:
![]()

3,置信度:在统计学中,置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度。这个概率被称为置信度。
4,过拟合:一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。
5,卷积:卷积是一种数学运算,常用于信号处理和图像处理等领域,它用数学形式描述了一个动态的过程。卷积核就是图像处理时,输入图像中一个小区域中像素加权平均后成为输出图像中的每个对应像素,其中权值由一个函数定义,这个函数称为卷积核。
6,池化(池化层pool):池化操作是卷积神经网络中的一个特殊操作,主要就是在一定区域内提取出该区域的关键性信息。这个计算过程可以是选择最大值、选择最小值或计算平均值,分别对应:最大池化(maxpool)、最小池化(minpool)和平均池化

7,全连接层是每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来,一般其参数是最多的。
8,PriorBox又称先验框,是特定尺度下一个固定大小和宽高比的矩形框。在物体检测中,需要先生成一系列PriorBox,再对这些框进行分类,回归等操作
9,鲁棒性:鲁棒是Robust的音译,也就是健壮和强壮的意思。它也是在异常和危险情况下系统生存的能力。比如说,计算机软件在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃,就是该软件的鲁棒性。
10,硬负面挖掘(hard negative mining)就是多找一些hard negative加入负样本集进行训练,这样会比easy negative组成的负样本集效果更好。 主要体现在虚警率更低一些(也就是false positive少)。
11,地面真值盒(Ground Truth Box)是用于计算机视觉任务中的目标检测和物体识别的工具之一。它是一个矩形框,用于标记图像或视频中的目标位置和边界框。地面真值盒通常由人工标注员手动绘制,以提供训练数据集中目标的位置和大小信息。
12,光度量扭曲是指在相对论中,由于质量或能量的存在,光线传播路径发生弯曲或偏移的现象。
13,AlexNet整体的网络结构包括:1个输入层(input layer)、5个卷积层(C1、C2、C3、C4、C5)、2个全连接层(FC6、FC7)和1个输出层(output layer)

14,Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如图所示。

15,SGD( 随机梯度下降算法),就是在每次更新的时候使用一个样本进行梯度下降,可以随机用一个样本来表示所有的样本,因为这个样本是随机的,所以每次迭代没有办法得到一个准确的梯度,这样一来虽然每一次迭代得到的损失函数不一定是朝着全局最优方向,但是大体的方向还是朝着全局最优解的方向靠近,直到最后,得到的结果通常就会在全局最优解的附近
16,范数是一种衡量向量大小的方法。
L0范数:用来统计向量中非零元素的 个数。
L1范数(曼哈顿范数)是将向量中各个元素的绝对值相加。
L2范数(欧氏范数)是最常见的一种范数,它计算向量中各个元素的平方和的平方根。
L∞范数(无穷范数)是向量中绝对值最大的元素。
17,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。
18,学习率是一个超参数,控制我们要多大程度调整网络的权重,以符合梯度损失。 值越低,沿着梯度下降越慢。 虽然使用较小学习率可能是一个好主意,以确保我们不会错过任何局部最低点,但也可能意味着我们将花费很长的时间来收敛,特别是当我们卡在平稳区域的时候。
19,次采样是一次抽样检验的延伸,它要求对一批产品抽取至多两个样本即做出批接收与否的结论,当第一个样本不能判定批接收与否时,再抽第二个样本,然后有两个样本的结果来确定批是否被接受
20,NMS(非极大值抑制)就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。
算法流程:
- 给出一张图片和上面许多物体检测的候选框(即每个框可能都代表某种物体),但是这些框很可能有互相重叠的部分,我们要做的就是只保留最优的框。假设有N个框,每个框被分类器计算得到的分数为Si, 1<=i<=N。
- 建造一个存放待处理候选框的集合H,初始化为包含全部N个框;建造一个存放最优框的集合M,初始化为空集。
- 将所有集合 H 中的框进行排序,选出分数最高的框 m,从集合 H 移到集合 M;
- 遍历集合 H 中的框,分别与框m计算交并比(Interection-over-union,IoU),如果高于某个阈值(一般为0~0.5),则认为此框与 m重叠,将此框从集合 H 中去除。
- 回到第2步进行迭代,直到集合 H 为空。集合 M 中的框为我们所需。
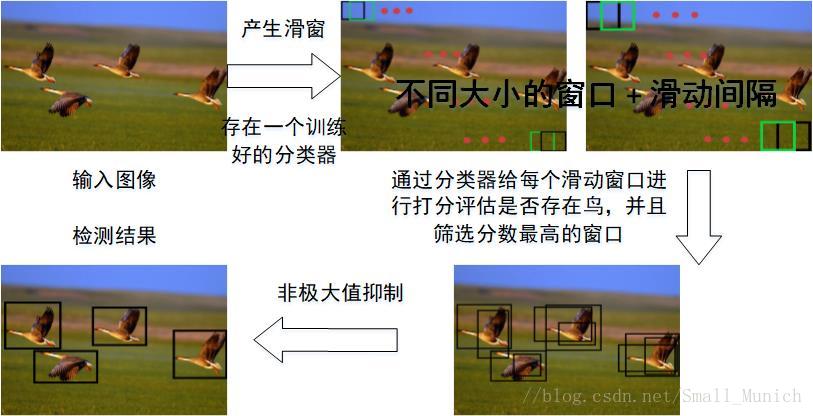
21,滑窗法主要思路:首先对输入图像进行不同窗口大小的滑窗进行从左往右、从上到下的滑动。每次滑动时候对当前窗口执行分类器(分类器是事先训练好的)。如果当前窗口得到较高的分类概率,则认为检测到了物体。对每个不同窗口大小的滑窗都进行检测后,会得到不同窗口检测到的物体标记,这些窗口大小会存在重复较高的部分,最后采用 NMS进行筛选。最终,经过NMS筛选后获得检测到的物体
22,选择性搜索:用候选区域方法(region proposal method)创建目标检测的感兴趣区域(ROI)。概括为:从图片中找出物体可能存在的区域。
23,HOG(方向梯度直方图,histogram of oriented gradients)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。
24,LBP(Local Binary Pattern,局部二值模式)是一种用来描述图像局部纹理特征的算子;它具有旋转不变性和灰度不变性等显著的优点。
25,DPM(Deformable Part Model)可变形的组件模型,是一种基于组件的检测算法,这种模型将目标对象建模成几个部件的组合。
26,在几何中,超平面指的是比所处空间少一个维度的子空间。
一维切二维:

二维切三维:

27,分类器就是用来把输入的数据进行分类的模型(本质上是函数)
线性分类器就是用一个“超平面”将两个样本隔离开:

非线性分类器就是用一个“超曲面”或者多个超平(曲)面的组合将两组样本隔离开
28,松弛的意思即为放松约束,对于一个标准化为求最小值的优化问题,松弛有可能使得到目标函数值更小的解,换言之,松弛可以求得原问题的一个下界。
29,松弛变量:当约束条件为"≤"("≥")类型的线性规划问题,可在不等式左边加上(或者减去)一个非负的新变量化为等式。. 这个新增的非负变量称为松弛变量(或 剩余变量 )。
30,SVM(支持向量机),它的基本模型是定义在特征空间上的间隔最大的线性分类器。在线性可分时,在原空间寻找两类样本的最优分类超平面;在线性不可分时,加入松弛变量并通过非线性映射将低维输入空间的样本映射到高维空间使其变为线性可分,再在该特征空间中寻找最优分类超平面。
31,边框回归:对于bbox一般使用四维向量(x,y,w,h)来表示, 分别表示bbox的中心点坐标和宽高。 图 中红色的框 P 代表原始的Proposal, 绿色的框 G 代表目标的 Ground Truth, 边框回归是寻找一种关系使得 P 经过映射得到一个跟 G 更接近的回归窗口G‘。

32,在进行浅层特征提取时,此时特征图每个像素点对应的感受野重叠区域还很小,能捕获更多细节,浅层有更高的分辨率。
在进行深层特征提取时,随着下采样或卷积次数增加,感受野和感受野之间重叠区域逐渐增加,此时像素点代表的是一个区域的信息,获得的是这块区域或相邻区域之间的特征信息,相对不够细粒度、分辨率较低,但语义信息丰富。
低级特征来源于浅层网络,富含空间信息(它用来表示物体的位置、形态、大小分布等各方面的信息,是对现实世界中存在的具有定位意义的事物和现象的定量描述。),空间信息的特征分辨率比较高。高级特征来源于深层网络,富含语义信息(处理单元和周围单元之间的关联性),语义信息的特征分辨率比较低。
33,YOLO是目标检测模型,全称是you only look once,指只需要浏览一次就可以识别出图中的物体的类别和位置。
34,损失函数(loss function)就是用来度量模型的预测值f(x)与真实值Y的差异程度的运算函数,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
35,归一化就是把需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。
36,Softmax分类器能够扩大识别分数的差距,即使得分函数的分数结果差别都不大,通过softmax分类器,就能够使得分数的差距进一步拉大,使得分类效果更加明显。
2,特点
(1)不需要对边界框假设的像素或特征进行重采样,速度大大提高。
(2)核心是用应用于特征映射的小卷积过滤器来预测一组固定的默认边界框的类别分数和框偏移,使用单独的预测器(过滤器)进行不同的宽高比检测,并将这些过滤器应用于来自网络后期阶段的多个特征映射,以便在多个尺度上执行检测。
(3)在不同的尺度上使用多层进行预测,使我们可以用相对较低的分辨率输入实现高精度。
(4)基于前馈卷积网络,该网络生成固定大小的边界框集合和这些框中存在的对象类实例的分数,然后通过非最大抑制步骤生成最终检测。
(5)将卷积特征层添加到截断的基本网络的末端。这些层的尺寸逐渐减小,允许在多个尺度上预测探测。
(6)卷积预测检测。每个添加的特征层(或可选的来自基础网络的现有特征层)可以使用一组卷积滤波器产生一组固定的检测预测。
(7)硬负面挖掘。不使用所有的负面示例,而使用每个默认框的最高置信度损失对它们进行排序,并选择顶部的示例,使负面和正面之间的比率最多为3:1。
(8)在大型对象上的表现非常好,在小对象上的性能要比大对象差得多。
(9)在不同的输出层上使用不同规模的默认盒。
三,YOLOv3: An Incremental Improvement
1,名词解释
1,聚类(Clustering)就是一种寻找数据之间内在结构的技术。
2,锚框:以每个像素为中心,生成多个缩放比和宽高比不同的边界框, 这些边界框被称为锚框。
3,二元交叉熵是用来评判一个二分类模型预测结果的好坏程度的,即对标签y,如果预测值p(y)趋近于1,那么损失函数的值应当趋近于0。反之,如果此时预测值p(y)趋近于0,那么损失函数的值应当非常大,这非常符合log函数的性质。
4,使用的数据存储在多维 Numpy 数组中,也叫张量(tensor)。
标量(0D 张量)
向量(1D 张量):
![]()
矩阵(2D 张量):

立方体(3D 张量):

5,上采样(或图像插值)即放大图像。下采样(或降采样)即缩小图像。
6,数据粒度指的是一份数据的细化程度
7,细粒度识别就是比普通的图像识别(分类)再精细化一些,比如不但要识别这是一条狗,还要说出它是拉布拉多还是哈士奇
2,特点
1,使用维度聚类作为锚框来预测边界框,使用逻辑回归预测每个边界框的对象得分,如果先前的边界框与地面真实对象的重叠超过任何其他先前的边界框,则该值应为1。使用k-means聚类来确定我们的边界盒先验。
2,每个框使用多标签分类预测边界框可能包含的类。我们没有使用softmax,使用独立的逻辑分类器。在训练过程中,我们使用二元交叉熵损失进行类预测。
3,在基本特征提取器中,添加了几个卷积层。最后一个预测了一个3-d张量编码边界框、对象和类预测。
4,YOLOv3对焦点丢失试图解决的问题具有鲁棒性,因为它具有单独的对象预测和条件类预测。















 1693
1693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









