







buffer在芯片物理上一般指的是SRAM,也可以指寄存器组。buffer的作用是用来在逻辑芯片上暂时存储数据,但不会是大量的数据。如果是大量数据一般会使用DRAM(典型的指DDR)作为存储芯片,用来存储大密度数据。line buffer可以理解为是存储数据结构为line方式的SRAM,主要用来存储二维行列数据中的行数据,最典型例子的就是图像的一行像素。
目录
一、Line Buffer的实质
在经典计算机体系结构理论中,系统使用分层的存储器体系结构。越靠近cpu的存储器速度越快容量越小,单位容量的存储成本越高;反之则速度越慢容量越大,单位容量的存储成本越低。概括来说,line buffer就是存储器体系结构中处于寄存器和DRAM之间的缓存(cache)。line buffer与CPU的cahce作用在很大程度上是相似的,就是为了充分利用SRAM和DRAM各自的优点,尤其是在利用数据的局部性原理上是一致的。尤其是在图像信号处理(ISP)领域,图像处理的数据局部性更确定,局部性更高,所以line buffer非常适合在处理过程中来缓存数据。
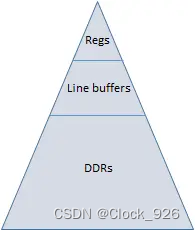
在图像处理IP中,数据的访问一般非常有规律性,大部分情况下都是行扫描方式处理,不需要像cache那样的复杂数据结构。在CPU体系结构里,cache为寄存器缓存了数据,DDR为cache缓存了数据。而在图像处理IP里,line buffer为寄存器缓存了像素,DDR为line buffer缓存了像素。
再更进一步,在CPU体系结构里,存储系统是由逻辑电路和操作系统共同管理的;而在图像信号处理IP里,存储系统是由逻辑电路和驱动软件共同管理的,例如图像的内存分配交换等过程。
我们都知道buffer在逻辑设计中无处不在,buffer的主要作用是缓冲连接的两端的速度变化,而line buffer也可以起到缓冲的作用。
(1)缓冲过程
仍旧拿ISP举例,假设有master和slave两个模块,master模块处理像素的速度与slave模块处理的速度完全相同,而且是任意时刻的速度和长时间的吞吐量都相等,那么master和slave之间则只需要简单的起始、结束信号来进行握手,就可以完成数据的交互。
假设master和slave两个模块之间一段时间数据吞吐量是一致的,但是某时刻master和slave模块的处理速度不相同,此时就需要一个FIFO来处理这些速度的不同,否则的话slave会时常拿不到master的数据或者master吐出的速度过快而导致丢数据。FIFO可以平滑master模块的速度抖动,使得slave能不停止的运行且数据不被丢弃。当然前提是master的吞吐量小于slave,否则FIFO会出现数据溢出。
假设master是按照行扫描顺序进行运算的,最典型的是卷积运算。为了让master和slave模块对接,必须等待master计算完成N行后,才可以开始slave模块的第一个块的计算,也可以理解为速率匹配。这个时候就可以用line buffer将master和slave连接起来。总结来说,line buffer被用于匹配不同的运算顺序。
二、使用意义
buffer在芯片物理上一般指的是SRAM,也可以指寄存器组。buffer的作用是用来在逻辑芯片上暂时存储数据,但不会是大量的数据。如果是大量数据一般会使用DRAM(典型的指DDR)作为存储芯片,用来存储大密度数据。line buffer可以理解为是存储数据结构为line方式的SRAM,主要用来存储二维行列数据中的行数据,最典型例子的就是图像的一行像素。
(1)带宽要求
我们知道相比SRAM来说,DRAM会更加便宜,导致DRAM更加适合大数据存储。既然line buffer可以理解为是存储数据结构为line方式的SRAM,那么为什么还要使用line buffer呢?
根本原因是对带宽的要求而不是速度。DDR的带宽是有限的,而SRAM的带宽则近乎于无限。这样考虑下来,DDR的带宽成本会要远高于SRAM的带宽成本。
在SoC芯片周围能够摆放的DDR数量肯定是有限的,DDR的频率是有限的,DDR的数据位宽也是有限的,这些诸多因素加起来就意味着一个SoC系统的DDR带宽一定是受到限制的。并且在整个SoC系统中有大量模块抖需要访问DDR,而DDR的带宽是共享的,所以分配给某个模块的带宽就更加是有限的。
相比而言,SRAM的带宽则可以近乎无限。因为SRAM带宽是某个特定模块单独使用的,使用的时候为某个模块开一块buffer,在后续使用过程中只有这一个模块对这部分buffer进行读写。甚至于有需要的话,在该模块内的某个子模块,也会开一块单独的buffer来使用。可以依此类推再继续细分下去,一整个大块的buffer被划分为多个小块buffer。对于SRAM的操作,可以灵活的进行分配组织使用,以获取更高的数据位宽,即带宽。在现在的设计中合理利用line buffer等逻辑结构是非常重要的一环。
(2)带宽消耗对比举例
在图像信号处理中,往往需要对图像进行滤波降噪等处理,这个时候需要对图像进行开窗卷积运算。假设我们使用卷积核为3x3像素,可以对比一下使用和不使用line buffer时分别所使用的带宽:
设图像像素总数为n,讨论以下几种情况:
① 没有line buffer暂存像素数据,也没有寄存器暂存读入像素的情况:每次需要从DDR读3x3=9个像素到卷积计算单元中,然后计算过程才能开始。由于卷积在水平和垂直方向的滑动步长为1,总共需要读取的数据量为n*9,也就是9倍图像带宽。
② 没有line buffer暂存像素数据,但是有9个寄存器暂存读入像素的情况:此时卷积寄存器可以以滑动的方式向右移动(也就是滑窗的过程)。除去每行的开始第一次需要从DDR读取3x3=9个像素数据,之后就只需要读取右边一列3个像素,然后丢弃左边一列3个像素,如此循环直到结束,一行卷积运算完成读取了3行像素。因为没有line buffer可以暂存已经读入的像素,所以在进行下一行卷积时仍然需要从DDR读取3行像素。总共需要读取的数据量为n*3,所以总的带宽是图像像素的3倍,即3倍图像带宽。
③ 有一行line buffer可以暂存像素数据,还有9个寄存器暂存读入像素的情况:依旧是滑窗,但是line buffer可以将第N行像素行保存下来,当卷积到N+1行时,最上面的3个像素可以从这行line buffer中读出,而不再需要从DDR中读取,每次只需要从DDR中读取最右边一列的下面2个像素。总共需要读取的数据量为n*2,所以总的带宽是图像像素的2倍,即2倍图像带宽。
④ 有两行line buffer可以暂存像素数据,还还有9个寄存器暂存读入像素的情况:此时line buffer增加到两行,当卷积到N+1行时,最上面6个像素都可以从这两行line buffer中读出,并不需要从DDR中读取,每次只需要从DDR中读取3x3窗中最右下角的1个像素。总共需要读取的数据量为n,所以总的带宽是图像像素的1倍,即1倍图像带宽。
此时如果再增加line buffer到三行,则不再有意义,除非增大卷积核开窗大小。寄存器可以在水平方向节省卷积运算的DDR带宽,line buffer可以降低垂直方向卷积运算的DDR带宽。卷积核的高度决定了将DDR带宽降低到1倍图像带宽的line buffer行数,即N-1(N为卷积核高度)。


















 2452
2452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











