









在本文中,我们将介绍一种提高RAG(Retrieval-Augmented Generation)模型检索效果的高阶技巧,即窗口上下文检索。
我们将首先回顾一下基础RAG的检索流程和存在的问题,然后介绍窗口上下文检索的原理和实现方法,最后通过一个实例展示其效果。
文章目录
通俗易懂讲解大模型系列
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型技术交流群,本文完整代码、相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流
基础RAG存在的问题及解决方案
基础RAG检索流程
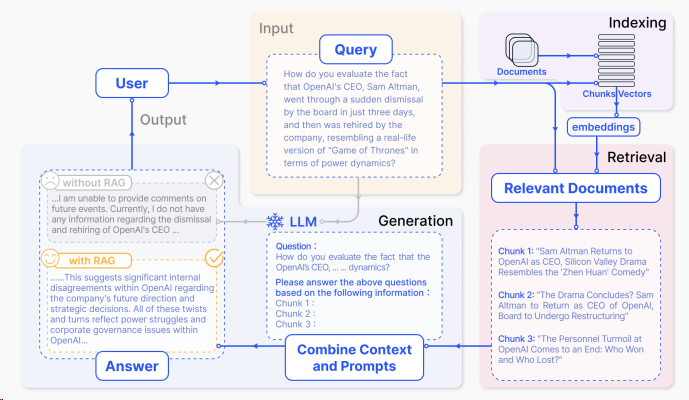
RAG是一种结合了检索和生成的AI应用落地的方案,它可以根据给定的问题生成回答,同时利用外部知识库(例如维基百科)来增强生成的质量和多样性。RAG的核心思想是将问题和知识库中的文档进行匹配,然后将匹配到的文档作为生成模型的输入,从而生成更加相关和丰富的回答。

RAG的检索流程可以分为以下几个步骤:
-
load:加载文档,将各种格式的文件加载后转化为文档,例如将pdf加载为文本数据,或者将表格转换为多个键值对。
-
split:将文档拆分为适合向量存储的较小单元,以便于与向量存储,以及检索时的文档匹配,例如将“我是kxc。我喜欢唱跳,rap,和篮球。”拆分为“我是kxc。”和“我喜欢唱跳,rap,和篮。”两个数据分块(一般称之为chunk)。
-
embedding:将文档用向量表示,例如使用BERT或TF-IDF等模型进行向量化。
-
store: 将向量化后的数据分块,存入向量数据库。
-
retrive:根据问题和文档的向量,计算它们之间的相似度,然后根据相似度的高低,选择最相关的文档作为检索结果,例如使用余弦相似度或点积等度量进行排序。
-
query:将检索到的文档作为生成模型的输入,根据问题生成回答,例如使用GPT-3或T5等模型进行生成。
基础RAG存在的问题
基础RAG的检索流程虽然简单,但是也存在一些问题,主要是在split和retrive两个步骤中。这些问题会影响RAG的检索效果,从而导致生成的回答不准确或不完整。
-
split拆分的块太大,在retrive时,同一块中非相关的内容就越多,对问题的检索匹配度影响越大,会导致检索的不准确。例如,如果我们将维基百科中的一篇文章作为一个文档,那么这个文档可能包含很多不同的主题和细节,与问题的相关性会很低。如果我们将这个文档作为检索结果,那么生成模型可能会从中提取出一些无关或错误的信息,从而影响回答的质量。
-
split拆分的块太小,检索的匹配度会提高,然而在最后的query环节,提供给llm使用的信息会由于缺少上下文的信息支撑,导致回答不准确。例如,如果我们将维基百科中的一篇文章拆分为多个句子,那么每个句子可能只包含一小部分的信息,与问题的相关性会很高。如果我们将这些句子作为检索结果,那么生成模型可能会从中提取出一些有用的信息,但是也可能会忽略一些重要的上下文信息,从而影响回答的完整性。
解决方案-窗口上下文检索
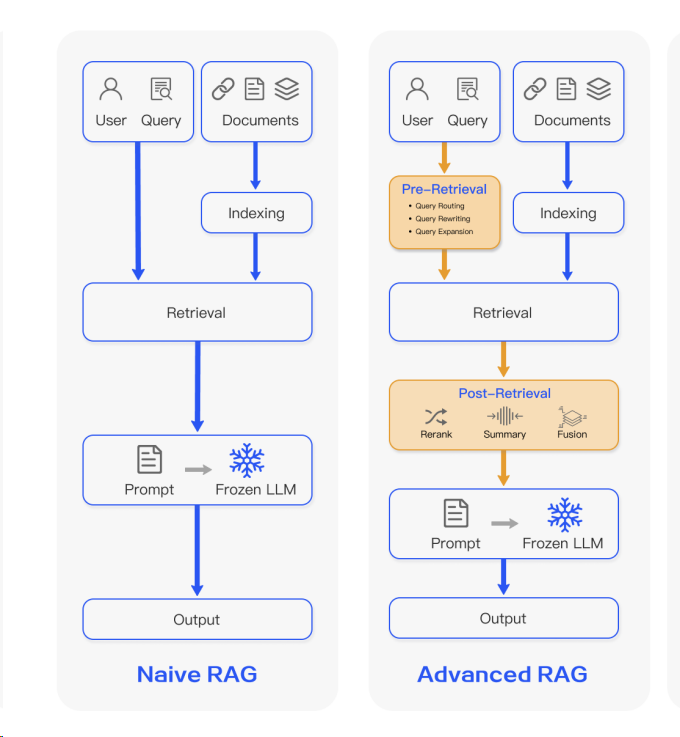
解决这个问题一般采取的方案是,在split拆分时,尽量将文本切分到最小的语义单元。retrive时,不直接使用匹配到doc,而是通过匹配到的doc拓展其上下文内容后整合到一起,在投递到LLM使用。这样,既可以提高检索的精度,又可以保留上下文的完整性,从而提高生成的质量和多样性。
具体来说,这种方案的实现步骤如下:
-
在split拆分时,将文本切分为最小的语义单元,例如句子或段落,并给每个单元分配一个唯一的编号,作为其在文本中的位置信息。
-
在retrive检索时,根据问题和文档的向量,计算它们之间的相似度,然后选择最相关的文档作为检索结果,同时记录下它们的编号。
-
在query生成时,根据检索结果的编号,从文本中获取它们的上下文信息,例如前后若干个单元,然后将它们拼接成一个完整的文档,作为生成模型的输入,根据问题生成回答。
窗口上下文检索实践
上下文检索实现思路
我们从最终要实现的目标着手,也就是在retrive时要能通过匹配到doc拓展出与这个doc内容相关的上下文。要想实现这个目标,我们就必须建立每个doc与其上下文的关联关系。这个关系的建立其实十分简单,只需要按顺序给拆分出来的每个doc进行编号,在检索时通过当前文档的编号就能匹配到相关上下文doc的编号,进而获取上下文的内容。
基于chroma向量库的代码实践
想要实践以上思路,需要在split环节基于文档顺序,将文档编码写入元数据。在检索时,则通过元数据中的顺序分块编码来查找上下文。具体的代码如下:
- 1.split时对分块编码并写入元数据
import bs4,uuid
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
doc = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
docs = text_splitter.split_documents(doc)
# 这里给每个docs片段的metadata里注入file_id
file_id = uuid.uuid4().hex
chunk_id_counter = 0
for doc in docs:
doc.metadata["file_id"] = file_id
doc.metadata["chunk_id"] = f'{file_id}_{chunk_id_counter}' # 添加chunk_id到metadata
chunk_id_counter += 1
for key,value in doc.metadata.items():
if not isinstance(value, (str, int, float, bool)):
doc.metadata[key] = str(value)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
- 2.retrive时通过元数据中的顺序分块编码来查找上下文
def expand_doc(group):
new_cands = []
group.sort(key=lambda x: int(x.metadata['chunk_id'].split('_')[-1]))
id_set = set()
file_id = group[0].metadata['file_id']
group_scores_map = {}
# 先找出该文件所有需要搜索的chunk_id
cand_chunks = []
for cand_doc in group:
current_chunk_id = int(cand_doc.metadata['chunk_id'].split('_')[-1])
group_scores_map[current_chunk_id] = cand_doc.metadata['score']
for i in range(current_chunk_id - 200, current_chunk_id + 200):
need_search_id = file_id + '_' + str(i)
if need_search_id not in cand_chunks:
cand_chunks.append(need_search_id)
where = {"chunk_id": {"$in": cand_chunks}}
ids,group_relative_chunks = get(where)
group_chunk_map = {int(item.metadata['chunk_id'].split('_')[-1]): item.page_content for item in group_relative_chunks}
group_file_chunk_num = list(group_chunk_map.keys())
for cand_doc in group:
current_chunk_id = int(cand_doc.metadata['chunk_id'].split('_')[-1])
doc = copy.deepcopy(cand_doc)
id_set.add(current_chunk_id)
docs_len = len(doc.page_content)
for k in range(1, 200):
break_flag = False
for expand_index in [current_chunk_id + k, current_chunk_id - k]:
if expand_index in group_file_chunk_num:
merge_content = group_chunk_map[expand_index]
if docs_len + len(merge_content) > CHUNK_SIZE:
break_flag = True
break
else:
docs_len += len(merge_content)
id_set.add(expand_index)
if break_flag:
break
id_list = sorted(list(id_set))
id_lists = seperate_list(id_list)
for id_seq in id_lists:
for id in id_seq:
if id == id_seq[0]:
doc = Document(page_content=group_chunk_map[id],
metadata={"score": 0, "file_id": file_id})
else:
doc.page_content += " " + group_chunk_map[id]
doc_score = min([group_scores_map[id] for id in id_seq if id in group_scores_map])
doc.metadata["score"] = doc_score
new_cands.append(doc)
return new_cands
总结
在本文中,我们介绍了提高RAG模型检索效果的高阶技巧-窗口上下文检索。我们首先回顾了基础RAG的检索流程和存在的问题,然后介绍了窗口上下文检索的原理和实现方法,最后通过一个实例展示了其效果。
我们希望这篇文章能够帮助你理解和使用窗口上下文检索这个高阶技巧,从而提高你的RAG模型的检索效果。如果你对这个技巧有任何疑问或建议,欢迎在评论区留言。谢谢你的阅读。😊
今天的内容就到这里,如果老铁觉得还行,可以来一波三连,感谢!
PS:AI小智技术交流群(技术交流、摸鱼、白嫖课程为主)又不定时开放了,感兴趣的朋友,可以在下方公号内回复:666,即可进入。
老规矩,道友们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!
















 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









