







Teach Me How to Denoise: A Universal Framework for Denoising Multi-modal Recommender Systems via Guided Calibration
原文地址: 这里
【 GUIDER 】题目翻译:“教我如何去噪:一种基于引导校准的通用多模态推荐系统去噪框架”
这篇文章提出了一个通用的多模态推荐去噪框架 GUIDER,通过细粒度模态相似度校准和基于最优传输的知识蒸馏,有效抑制多模态噪声,显著提升了推荐系统的准确性和鲁棒性。
摘要
摘要 随着多媒体内容的激增,多模态推荐系统(MMRecs)应运而生,通过整合文本、图像、视频和音频等多种模态,实现更个性化的推荐。然而,由于各模态内容之间存在错配,以及模态语义与推荐语义的差异,MMRecs 面临噪声数据的挑战;而传统的去噪方法因多模态数据的复杂性,难以有效应对此类问题。为此,我们提出了一种通用的引导同步蒸馏去噪框架 GUIDER(Guided In-sync Distillation for Denoising),旨在通过去除用户反馈中的噪声来提升 MMRecs 的性能。具体而言,GUIDER 首先采用再校准策略,从多模态内容中识别出干净交互与噪声交互;然后引入去噪化贝叶斯个性化排序(DBPR)损失函数,以去除隐式用户反馈中的噪声;最后利用基于最优传输(OT)距离的去噪知识蒸馏目标,指导模态表示向推荐语义空间的映射。GUIDER 可以即插即用地集成到现有的多模态推荐方法中,作为推荐去噪的通用解决方案。在四个公开数据集上的实验结果表明,该框架在多种 MMRecs 方法上均展现了良好的有效性和普适性。
一、引言
推荐系统作为强大的信息过滤引擎,在电商【36】、短视频分享【30, 47】和社交媒体平台【14】等多种场景中得到广泛应用。传统推荐系统以 ID 为基础【19, 20, 33】,为每个用户/物品分配唯一标识符(ID),并将其转换为嵌入向量,从用户–物品交互中学习偏好。为了利用丰富的多媒体内容挖掘用户兴趣,多模态推荐系统(MMRecs)【3, 6, 24, 45, 47, 51, 52】通过特定模型的编码器融合物品的多模态内容(如商品文本描述和图片封面),并挖掘模态间的细粒度关系以捕捉模态特定的用户偏好。这一范式转变能够缓解冷启动问题【22】并展现更好的可迁移性【8–10, 27, 28, 41, 51】,随着诸如 GPT-4【1】、CLIP【31】、DALLE【32】和 LLaMa【40】等强大多模态基础模型的出现,这一方向得到进一步普及。
开发高性能推荐系统的一个重大障碍是噪声交互问题。与基于 ID 的推荐系统(IDRecs)类似,多模态推荐系统(MMRecs)也会受到伪造用户反馈带来的噪声交互影响,这些噪声可能源于误点击或出于好奇的行为,无法准确反映用户真实偏好。此外,在多模态推荐环境下进行去噪还面临独特挑战,如图 1 所示。第一个挑战是来自模态内容的噪声,文本或图像描述可能具有误导性或与实际不相关(图 1(a) 和 2(b))。第二个挑战是映射不一致,不同类别的物品(例如背带、智能手机和婴儿服)在视觉上可能非常相似,导致推荐中的语义不对齐(图 1©)。
图1
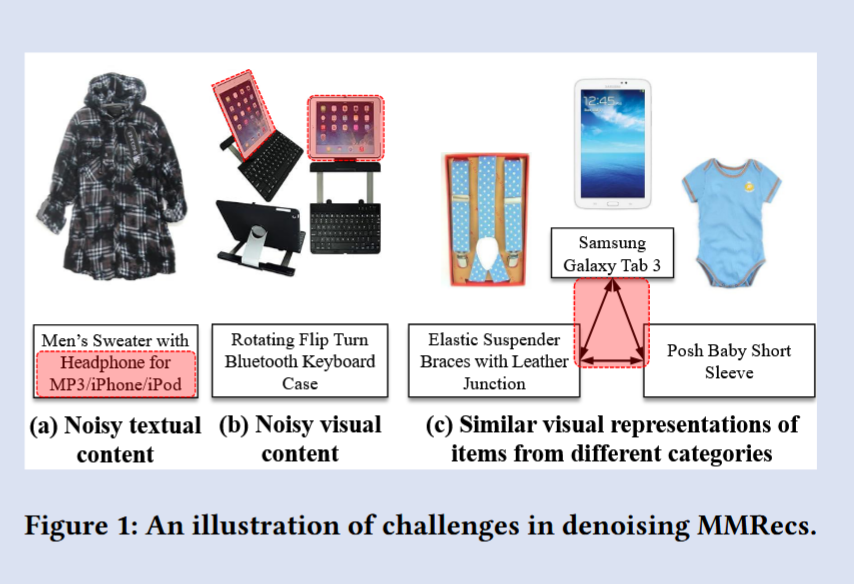
Figure 1 从三个角度直观地展示了多模态推荐系统在去噪时所面临的典型困难:
(a)文本模态噪声(Noisy textual content)
如图中所示,不同商品的标题或描述可能包含冗余、误导甚至不相关的信息——例如“Elastic Suspender Braces with Leather Junction”与“Rotating Flip Turn Bluetooth Keyboard Case”都属于完全不同的商品类别,但文本描述并未准确反映它们的实际用途或类别。这种噪声会导致模型在挖掘用户偏好时,将注意力放在与真实兴趣无关的关键词上。(b)视觉模态噪声(Noisy visual content)
即便图像内容本身清晰,也可能与推荐任务毫无关联。比如一个商品图可能只是展示品牌logo或包装细节,而并未传递出用户真正关心的属性(如功能、款式等)。模型如果直接将这些视觉特征与用户历史交互关联,就容易将“无关”信息误判为用户喜好。(c)跨类别视觉相似性(Similar visual representations across categories)
不同类别的物品在视觉上可能非常相似,比如某些婴儿服装的柔和色调和设计,与成人服饰在色彩和纹理上并无明显区分;又或是挂钩类配件与电子产品的外观轮廓相似。这样的“视觉语义”错位会使得模型倾向于在错误的类别间建立联系,从而降低推荐的准确性。这三个子图共同说明,仅靠单一模态(文本或图像)去噪,或简单地基于 ID 嵌入空间去清洗噪声,都不足以解决 MMRecs 中的复杂噪声污染问题。因此,GUIDER 框架正是通过跨模态的协同校准与最优传输蒸馏,来分别识别并剔除这三种类型的噪声。
为缓解噪声交互问题,现有大多数研究集中于基于 ID 的方法,主要通过样本选择【39, 42】或样本重加权【11, 12, 42】来对隐式反馈进行去噪。这些方法的直觉是:噪声的用户–物品交互较难被推荐模型拟合,因此通常表现为较低的相似度分数并带来较大的损失值。然而,我们在第 3.2 节的实验表明,这一假设在 IDRec 环境下虽然成立,但在多模态推荐环境中由于 ID 嵌入空间与多模态表示空间之间存在显著差异而不再适用,如图 2 所示。在多模态空间中,噪声交互(例如 (u₂, i₁))在 ID 嵌入空间中虽表现出低相似度,但在多模态空间中却难以被检测;另一方面,真实交互(例如 (u₂, i₂))若其模态表示有噪声,也可能产生较大损失值,从而同样难以区分。这种差异导致在 MMRecs 上直接应用传统去噪损失时,许多真实的用户–物品交互会被误判为噪声。因此,我们认为专为 IDRec 设计的方法并不足以应对多模态推荐的去噪需求,亟需针对 MMRecs 独特特性开发一套通用且高效的去噪框架。
简单来说,这段话是在说:
- 传统去噪思路:在普通的 ID 推荐里,人们发现那些“假点击”或者“无意义的交互”——也就是噪声交互——往往不符合用户真实喜好,模型学习时对它们的预测很差(损失大),或是它们在用户和物品的向量空间里离得比较远(相似度低)。因此,大家就按“损失大”或“相似度低”来挑出噪声,把它们去掉或降权。
- 多模态推荐的麻烦:但一旦把文本、图片、视频这些信息都混合进来,物品的表示就变得更加复杂。这个混合后的“多模态空间”跟纯粹的 ID 空间差别很大。结果是:
- 有些确实是噪声的交互,在这个多模态空间里看起来却挺“正常”,反而难以被模型察觉;
- 而有些真实的、用户真正喜欢的交互,因为文字或图片本身有点问题(比如描述不准、图像和标签不符),在多模态空间里反而看起来“奇怪” —— 损失很大、相似度很低,被误判成噪声。
- 结论:所以,拿 ID 推荐那套“看谁损失大就当噪声”的方法,直接用在多模态推荐上,会把很多有价值的真实交互给错杀,也漏掉真正的噪声。我们需要一种专门针对多模态特性来去噪的新思路,而不是简单地搬用旧方法。
为了解决上述挑战,我们提出了一种面向多模态推荐的引导同步蒸馏去噪框架 GUIDER——一个旨在增强 MMRecs 的通用去噪方案。具体而言,GUIDER 首先引入自适应模态相似度校准(AMSC),通过基于文本与视觉模态语义相似度的细粒度再校准策略,对可靠样本与噪声样本进行重新划分,从模态内容中识别出噪声交互。随后,GUIDER 设计了去噪贝叶斯个性化排序(DBPR)损失函数,利用 AMSC 识别出的正例与噪声负例,对用户隐式反馈中的噪声进行去除。鉴于我们在实证研究中发现,直接对 MMRecs 应用去噪损失函数不可行,GUIDER 通过先使用 DBPR 训练一个去噪的 IDRec 教师模型,再将该去噪教师模型作为学生 MMRec 的指导,通过知识蒸馏(KD)【21】的方式,实现在从模态表示空间向推荐语义空间的迁移过程中有效剔除噪声。此外,考虑到标准的 KL 散度往往会引发过度平滑【25】和模型塌陷【2】问题,我们提出了一种基于最优传输(OT)距离【7】的 KD 目标,用于蒸馏推荐 logits,使其成为具备稳定梯度的对称距离度量,更加适合用于知识蒸馏。
我们的工作:
• 我们识别了多模态推荐系统(MMRecs)去噪所面临的独特挑战,并揭示了现有基于 ID 的去噪方法在应对多模态噪声时的局限性。
• 针对这些挑战,我们提出了 GUIDER——一种通用的 MMRecs 去噪框架,结合基于模态语义的细粒度再校准策略与基于最优传输(OT)距离的引导知识蒸馏,实现了对多模态内容的高效去噪,并显著提升了推荐性能。
• 我们在四个基准数据集上进行了大量实验证明 GUIDER 的有效性和通用性,展示了其作为即插即用去噪框架在不同数据集与噪声条件下的广泛适用性。
二、相关工作
2.2 推荐去噪
在推荐系统数据集中,噪声无处不在,因此有必要通过去噪方法净化用户–物品交互。经典的 WBPR [11] 方法将用户尚未交互的热门物品视为真实负反馈。T-CE [42] 通过截断损失值超过动态阈值的交互,对噪声交互在损失函数中的贡献进行削减。R-CE [42] 则对损失值应用重加权函数,以降低噪声交互的影响。SGDL [48] 利用模型的“记忆效应”来指导推荐去噪,并引入去噪调度器以增强鲁棒性。DeCA [43] 则通过不同模型预测的一致性作为隐式反馈的去噪信号。BOD [44] 提出了高效的双层优化框架,用于学习用户–物品交互的去噪权重。
备注:针对多模态推荐系统(MMRecs)中噪声问题的研究仍较有限。我们的 GUIDER 框架填补了这一空白,提出了一个通用的去噪方案,将去噪任务从传统的基于 ID 的推荐系统扩展到多模态推荐情境中。
三、 预备知识
3.1 问题定义
IDRec 与 MMRecs
令 U U U 为用户集合, I I I 为物品集合,用户–物品交互数据为
D = { ( u , i , r u i ) ∣ u ∈ U , i ∈ I } , D = \{(u, i, r_{ui}) \mid u \in U,\; i \in I\}, D={(u,i,rui)∣u∈U,i∈I},
其中标签 r u i ∈ { 0 , 1 } r_{ui} \in \{0,1\} rui∈{ 0,1} 表示用户 u u u 是否与物品 i i i 发生了交互(如点击或评论)。为了从隐式反馈中捕捉用户偏好,推荐系统通常学习用户表示 { h u ∈ R d ∣ u ∈ U } \{h_u \in \mathbb{R}^d \mid u \in U\} { hu∈Rd∣u∈U} 和物品表示 { h i ∈ R d ∣ i ∈ I } \{h_i \in \mathbb{R}^d \mid i \in I\} { hi∈Rd∣i∈I},并以潜在维度 d d d 为大小,优化以下推荐损失(例如逐点二元交叉熵损失):
L R e c ( D ) = ∑ ( u , i , r u i ) ∈ D [ − r u i log ( s u i ) − ( 1 − r u i ) log ( 1 − s u i ) ] (1) \mathcal{L}_{\mathrm{Rec}}(D) = \sum_{(u,i,r_{ui}) \in D} \Bigl[-r_{ui}\log(s_{ui}) - (1 - r_{ui})\log(1 - s_{ui})\Bigr] \tag{1} LRec(D)=(u,i,rui)∈D∑[−ruilog(sui)−(1−rui)log(1−sui)](1)
其中
s u i = h u ⊤ h i s_{ui} = h_u^\top h_i sui=hu⊤hi
是对用户–物品对 ( u , i ) (u,i) (u,i) 的预测相似度得分。在传统的基于 ID 的推荐(IDRec)中, h u h_u hu 和 h i h_i hi 来自于嵌入矩阵;而在多模态推荐(MMRecs)中, h u h_u hu 与 h i h_i hi 则通常通过将文本和视觉特征分别经由模态专用编码器提取后融合得到。
这个式子是对所有用户–物品对 ( u , i ) (u,i) (u,i) 的逐点二元交叉熵损失(pointwise Binary Cross-Entropy)求和,用来衡量模型预测分数 s u i s_{ui} sui 和真实交互标签 r u i r_{ui} rui 之间的差距。拆开来看:
L R e c ( D ) = ∑ ( u , i , r u i ) ∈ D [ − r u i log ( s u i ) − ( 1 − r u i ) log ( 1 − s u i ) ] \mathcal{L}_{\mathrm{Rec}}(D) = \sum_{(u,i,r_{ui})\in D} \bigl[ -\,r_{ui}\,\log\bigl(s_{ui}\bigr) \;-\;(1 - r_{ui})\,\log\bigl(1 - s_{ui}\bigr) \bigr] LRec(D)=(u,i,rui)∈D∑[−ruilog(sui)−(1−rui)log(1−sui)]
正例部分
当 r u i = 1 r_{ui}=1 rui=1(用户 u u u 与物品 i i i 真实交互过,比如点击过),损失项变为− log ( s u i ) . -\log\bigl(s_{ui}\bigr). −log(sui).
如果模型给出了很高的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9600
9600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











