






 本文分析了英伟达的GB200NVL72系统,强调了光电混合在网络架构中的重要性,以及高速光网络和芯片层面的光互联的长期发展方向。报告预测随着AI训练和推理需求的增长,光模块和液冷技术将迎来投资机会。
本文分析了英伟达的GB200NVL72系统,强调了光电混合在网络架构中的重要性,以及高速光网络和芯片层面的光互联的长期发展方向。报告预测随着AI训练和推理需求的增长,光模块和液冷技术将迎来投资机会。
今天分享的是人工智能专题系列深度研究报告:《人工智能专题:GenAI系列之-网络之辩,英伟达Blackwell背后的光电演绎》。
(报告出品方:SWS)
结论
AI底层硬件向“大系统”演进。
市场较多讨论英伟达GB200 NVL系统的通信需求,光与铜“孰轻孰重”;我们认为光电混合是当前重要架构,未来更高速的光网络和芯片层面的光互联是长期方向,
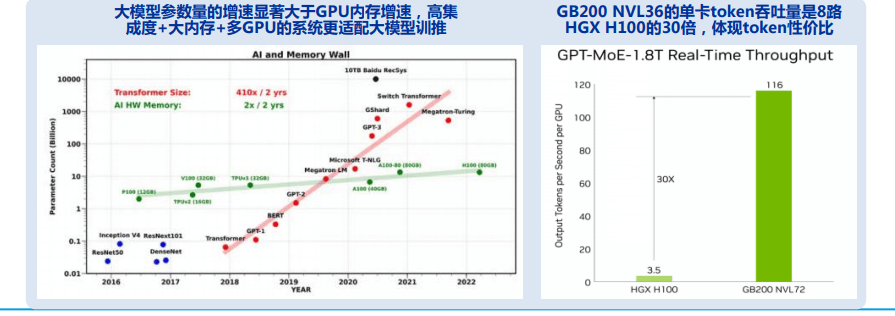
基于云厂商视角,我们预计GB200 NVL系统是AI训练+推理在云端的较佳选择。而在英伟达B系列芯片更新的节点上,我们预计后续AI芯片迭代出货,对应的800G/1.6T光模块/光器件需求增长,硅光、液冷产业链投资机会也随之增加,看好海外大厂的高速网络需求的持续性。
原因及逻辑
1)英伟达的GB200 NVL72方案将72 GPU高密度配置在一个机柜中,用于大模型训推,其中柜内组网以电气信号背板和铜线的NVink网络为主,而机柜外扩容组网尤其千至万卡互联则需要2-3层交换机网络和光通信方案。前者是芯片互联增量,后者架构延续但整体升级。
2)整体看,单一介质网络连接的性能,最大传输距离与最高带宽成反比,且综合考虑成本,同时考虑工程可行性。光电混合是当前出于成本考虑的重要架构,光网络和芯片层面的光互联是长期方向。
3)硅光的演进方向明确。芯片算力性能暴增+训练/推理的参数需求,网络、访存性能亟需同步提升。电口瓶颈已至,芯片·板卡-设备间高速互联,光电子几乎是迭代唯一出路。当前放量临近、格局逐步明晰。4)AI硬件高密度、高功耗的路径下,液冷方案的渗透空间巨大。
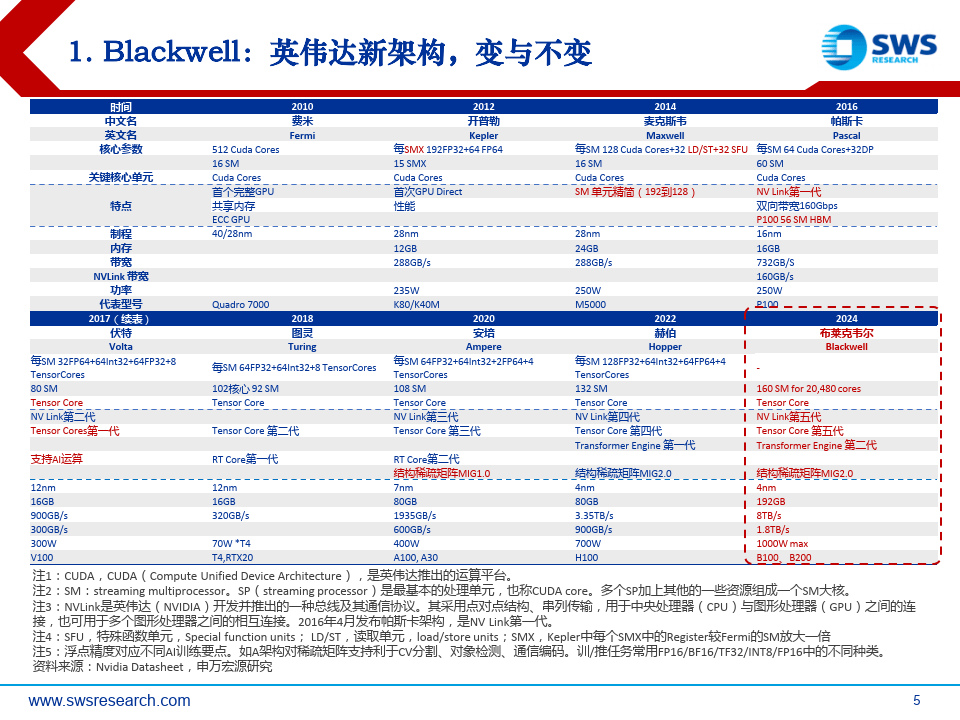
Blackwell:英伟达新架构,变与不变
Key takeaways
(一)性能跃升:内存、带宽、算力“三大件”。
TSMC 4NP工艺,2 dies,20 PFLOPS@FP8 (Hopper 2.5倍。
HBM3e 192 GB内存@8 TBps带宽。
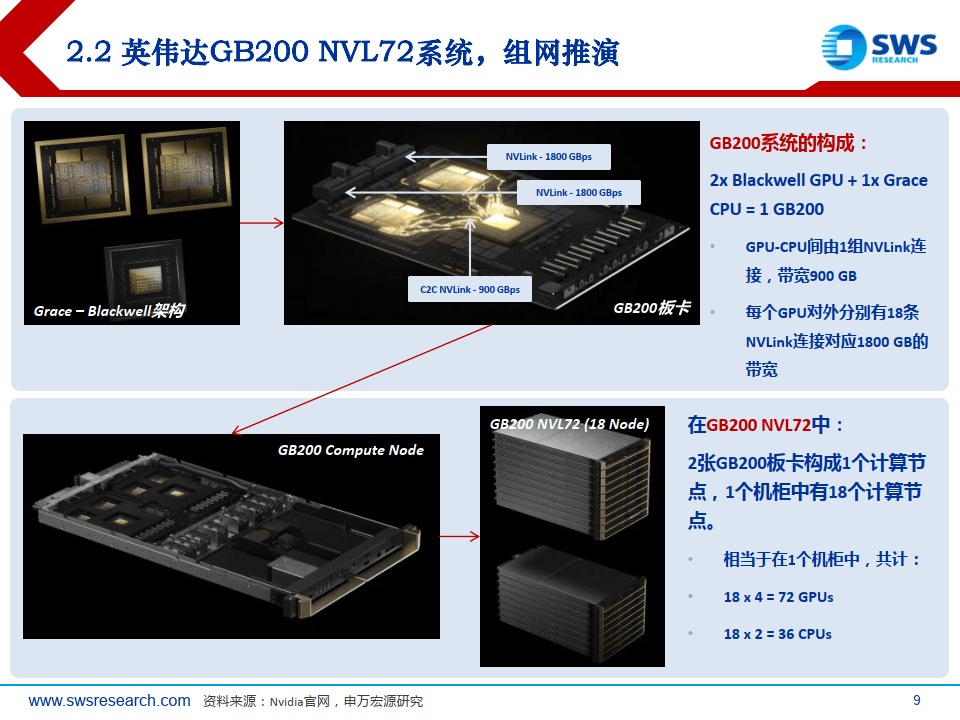
(二)NVLink 5t,拓展72 GPU集群,C2c互联。
单GPU 18x NVLink,带宽1800 GBps(此前H100-代900 GBps )新变化最新NVLink switch交换芯片,可576 GPU互联(目前实际应用72 GPU互联,此前仅8 GPU)Chip to chip,真正意义上实现跨“服务器”互联,达机柜级(尽管此前H100也有尝试)(三)算力呈现方式:板卡-服务器-机柜系统新变化。
GB200 NVL72系统,算力的“最小单元”从GPU扩大为机柜,以应对海量参数训推(四)网络场景:c2c,b2b,m2m,交换机网卡。
光、电混合,成本与性能平衡,200GserDes,集群带宽首次应用1.6 Tbps光网络(五)液冷:高密度,高功率。
GB200功率可达2700W,NVL72单机柜总功率190kw+,全液冷必备新变化。
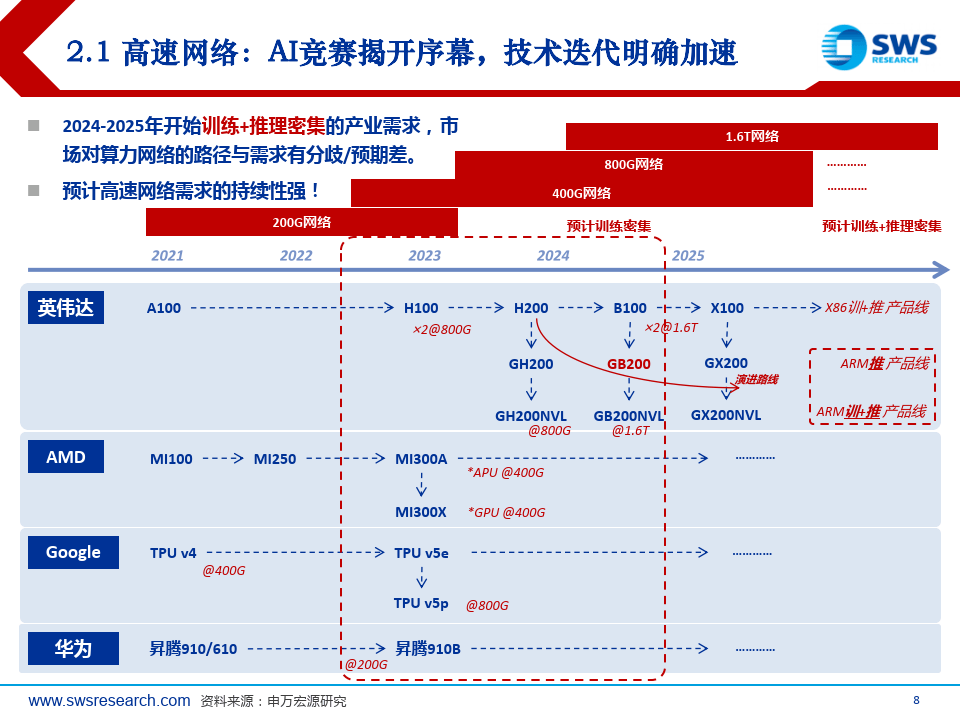
高速网络:AI竞赛揭开序幕,技术迭代明确加速
2024-2025年开始训练+推理密集的产业需求,市场对算力网络的路径与需求有分歧/预期差。
预计高速网络需求的持续性强!
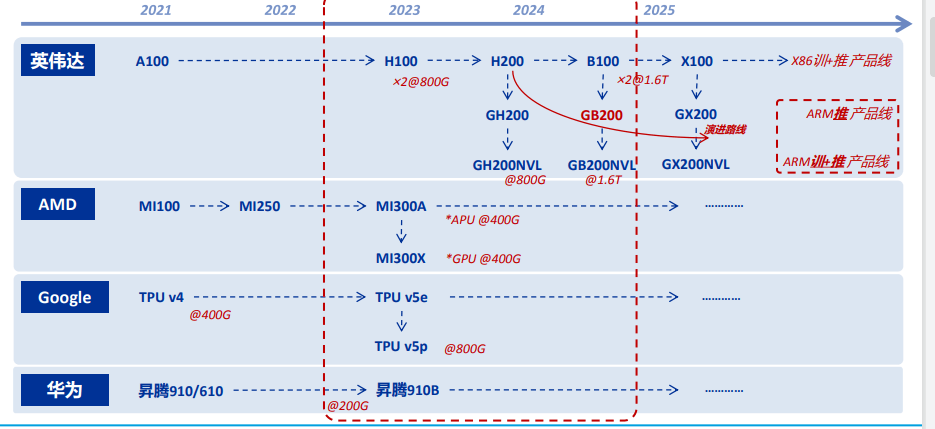
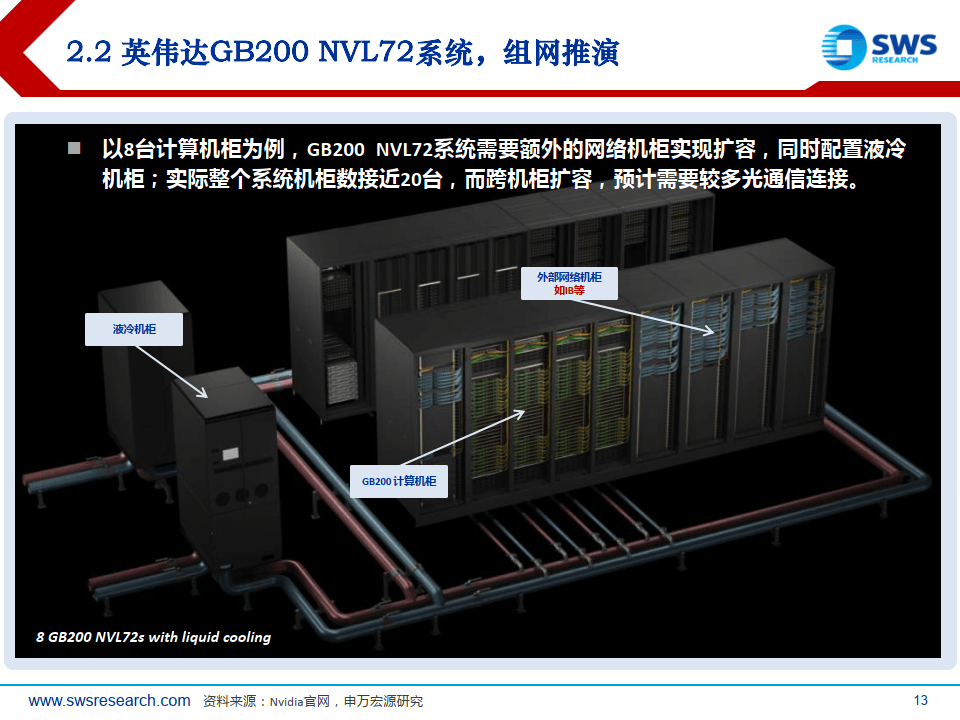
英伟达GB200 NVL72系统,组网推演
此外,英伟达GTC2024发布Quantum-XInfiniBand800交换机,1.6T时代来临!其中NVIDIA Quantum-X800 Q3400-RA 4U交换机:首个200G SerDes交换机,144个800Gb端口,整合72个OSFP口(每个1.6T带宽,后续升级connectx-8800Gbps);2层fat-tree架构下,支持0368个NIC扩容&同时LD版本为液冷系统。

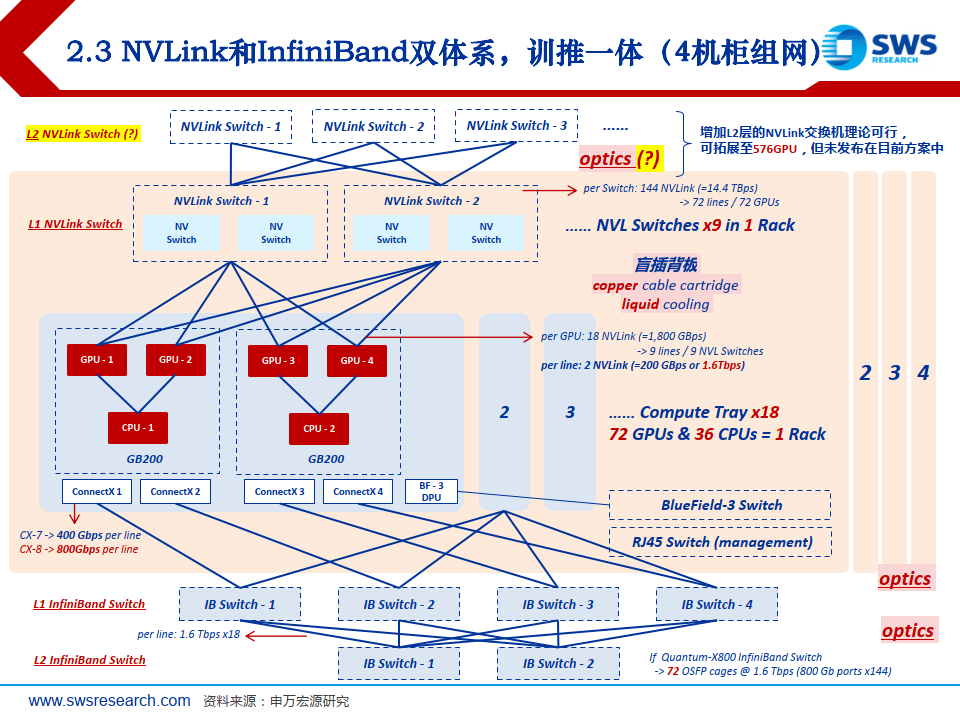
NVLink和InfiniBand双体系,训推一体
GB200 NV72系统对网络的需采测算,4列72 GPUS。
1)NVLink交换机需求量:9x4=36台(各自机柜内的L1交换机)。
2)InfiniBand交换机需求量:L1 4台+L2 2台=6台(X800 1.6T交换机)。
每台交换机144个端口,无收敛网络下,L1交换机上下行端口等分,即上行72+下行72;第1台交换机的72个端口,分别连接4个机柜中18个compute Node(共72个Node)中的第1张CX-8(800Gb),以此类推,由于每个compute Node中均有4个cX-8,这样L1层的4台交换机,下行的72个端口可插满;继续,对于4台L1交换机剩余的上行72个端口,总计4x72=288个连接,L2交换机仅需288 ÷144=2台,即可实现端口的全互联。
3)光模块的需求量(对应4x72=288 GPUs)
GPU侧,4x72=288个800G光模块(GPU比=1:1)
交换机侧,6x72=432个1.6T光模块(GPU比=1:1.5)以上的2层fat-tree网络,最大可支持10368卡扩容。即144 x72;当集群大于10368卡时,L1交换机将大于144台;由于该L2交换机单台端口数最大144,则L1和L2之间无法充分互联,需要增加一层L3交换机。此时会增加1.6T光模块的GPU比,至1:2.5。







报告来源/公众号:【海选智库】
本文仅供参考,不代表我们的任何建议。海选智库整理分享的资料仅推荐阅读,如需使用请参阅报告原文。

















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









