







强化学习已成为机器学习中一个很有前途的领域,可以解决通常处于不确定性状态的顺序决策问题。这方面的例子包括多梯队和多个供应商的库存管理,交货时间在需求不确定的情况下;控制问题,如自主制造操作或生产计划控制;以及财务或运营中的资源分配问题。
强化学习是一种学习范式,用于学习优化顺序决策,这些决策是跨时间步长重复做出的决策,例如,在库存控制中做出的每日库存补货决策。在高层次上,强化学习模仿了我们人类的学习方式。人类有能力学习帮助我们掌握复杂任务的策略,如游泳、体操或参加考试。强化学习广泛地从这些人类能力中寻求灵感,以学习如何行动。但更具体地说,对于强化学习的实际用例,它试图获得在不确定性下的动态系统中跨时间重复做出顺序决策的最佳策略。它通过与感兴趣的随机动态系统(也称为环境)的模拟器进行交互来学习此类制胜策略。在动态系统中跨时间重复做出顺序决策的策略也称为策略。强化学习试图学习制胜策略,即如何在动态系统的不同状态下采取行动的制胜秘诀。
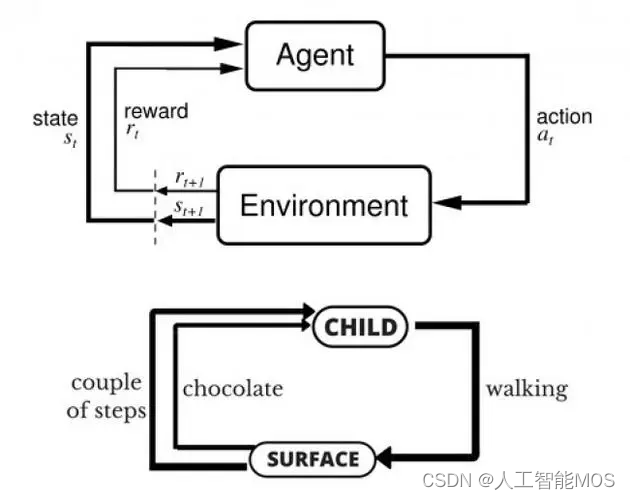
强化学习在数学框架中的工作
- 状态空间(或观察空间):对做出决策有用的所有可用信息和问题特征。这包括完全已知或测量的变量(例如,库存控制中的当前库存水平)以及您可能只有信念或估计的未测量变量(例如,对未来一天或一周的需求预测)。
- 操作空间:在系统的每个状态下可以做出的决策。
- 奖励信号:一种标量信号,提供有关性能的必要反馈,因此有机会了解在任何给定状态下哪些操作是有益的。学习本质上是局部的,学习眼前的收益和长期的收益,因为在任何状态下采取的行动都会导致未来的状态,在该状态中采取另一种行动,依此类推。折扣累积奖励信号是强化学习的优化目标,使其专注于产生最佳累积奖励的长期策略。
大多数动态优化问题以及一些确定性离散(组合)优化问题都可以在状态-动作-奖励框架中自然地表达。当在任何状态下采取行动以收集局部奖励并推动系统及时前进时,动态系统会在状态空间中经历(不确定的)转换。例如,马尔可夫决策过程(MDP)模型将动态系统中不确定的转换和奖励下的顺序决策形式化,并采取状态-行动-奖励模型的形式。
在不确定的转换和不确定的奖励下,在动态系统中通过强化学习结合了两个相辅相成的思想:探索新的状态和新的状态-动作组合,并利用由此产生的经验来改进决策。这是强化学习的两个基本思想,即探索和利用。如果有足够的时间(即足够的经验积累),强化学习可以产生一个成功的策略(或策略),你可以在重复的决策问题中将其用于长期决策。
强化学习与机器学习
它有助于将强化学习与经典监督机器学习进行对比,以更好地了解强化学习。在监督式机器学习中,你专注于预测你不知道的东西。在独立且相同分布的输入数据(i.i.d 输入数据)的统计假设下,它效果最好。简单来说,这意味着假定每个输入数据记录都独立于其他每个记录,并且每个输入数据记录都是从某个单一的、通用的基础输入数据分布模型中实现的。当用作决策模型时,监督预测模型是一次性决策或预测,它只关注给定的输入数据记录,并与所有其他输入数据记录分离。预测模型的学习是通过监督进行的,使用预测精度最大化作为学习目标。您可以访问与用于训练的每个数据输入记录相对应的地面实况预测。下图抓住了这种可以称为“学习预测”的范式。
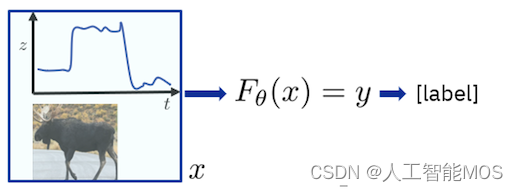
相比之下,强化学习是一个基于学习的决策框架,在这个框架中,你不再有一个带有地面实况标签的i.i.d数据表。取而代之的是,你拥有“
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









