






对于刚接触大模型(如GPT、LLaMA、DeepSeek、Qwen等)的新手来说,"推理(Inference)"可能是最让人困惑的术语之一。它不像"训练"那样直观,也不像"微调"那样有明确的目标,但却是大模型从"学习"到"干活"的关键环节。
一、概念解读
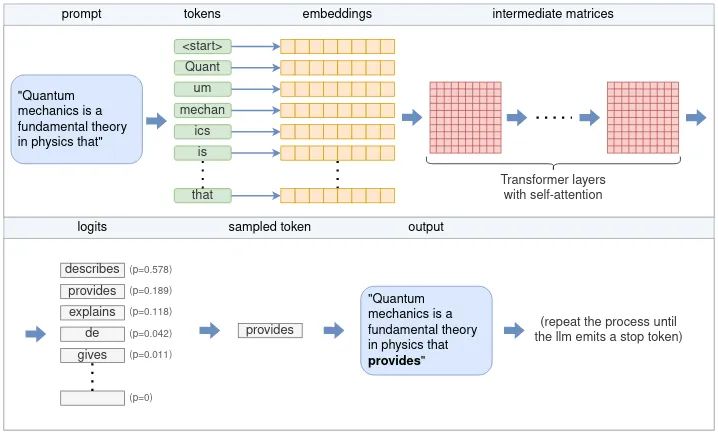
Inference(模型推理)到底是个啥?模型推理是训练好的大模型从“学习知识”到“实际应用”的核心环节。模型推理 = 让训练好的模型"干活"(比如回答你的问题、翻译文本、生成文章等)。
简单来说,就是让模型根据输入数据“动脑思考”,生成答案或决策。例如,输入“请解方程:3x+5=32”,模型会输出解题步骤与答案。
- 训练:就像学生背书、刷题,目标是记住知识(模型参数)。
- 推理:就像学生考试,根据题目(输入)写出答案(输出),但不再翻书(不更新参数)。
模型推理的本质是通过将用户输入转化为数据信号,触发内部预存的参数‘齿轮组’(矩阵运算+注意力机制)高速运转,最终‘吐出’与输入匹配的答案,全程参数冻结、只做计算不做学习。
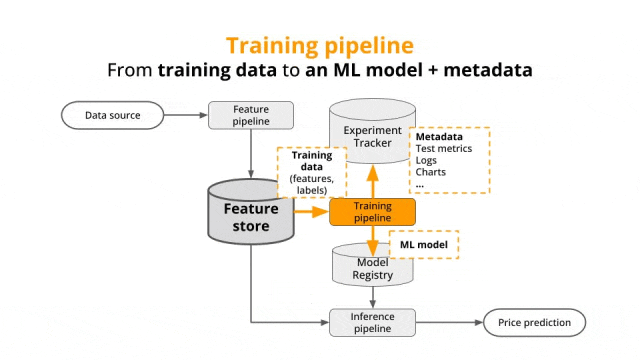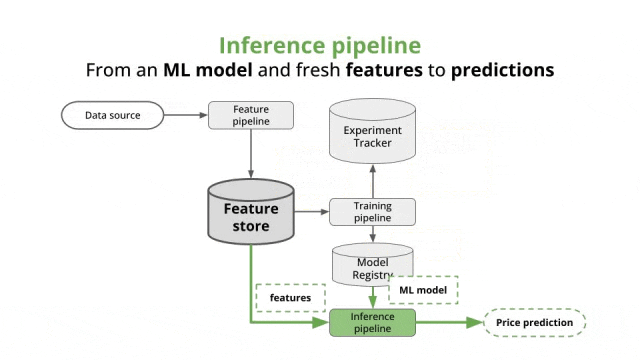
为什么需要Inference(模型推理)?模型推理是AI的“最后一公里”——训练赋予知识,推理激活价值;若仅有训练,模型便如“空有蓝图”的图纸,永远无法落地为“解决问题”的生产力工具。
模型如同一个刚出生的“婴儿大脑”(随机初始化的参数),无法理解任何信息,也无法解决实际问题。训练(Training)是让模型通过海量数据“学习知识”,从“一无所知”进化为“掌握规律”的“知识载体”;而推理(Inference)则是让模型将学到的知识“学以致用”,真正成为解决实际问题的“工具”。
二、技术实现
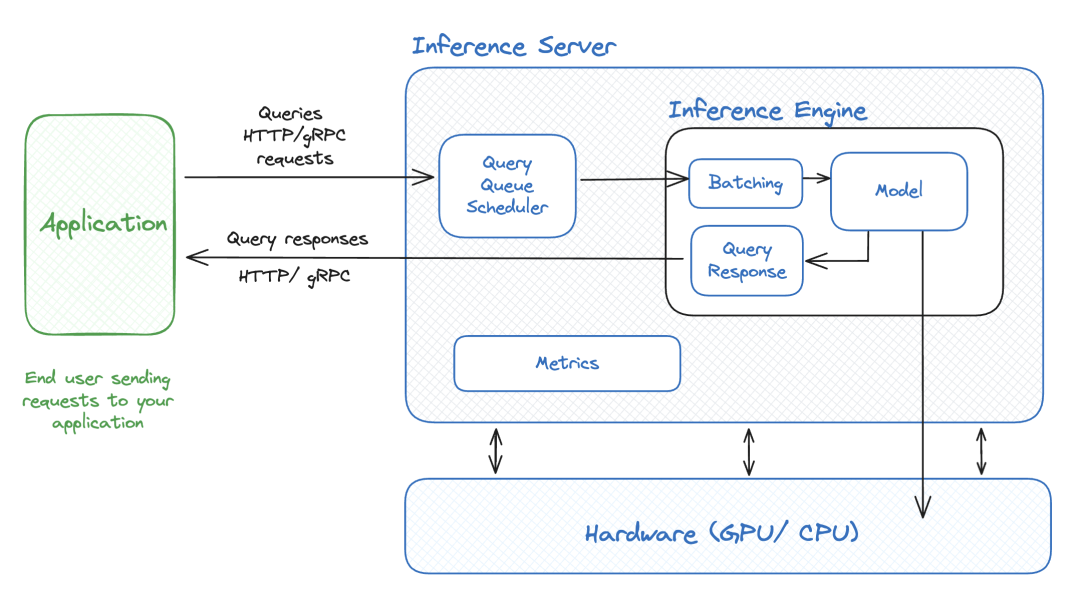
Inference(模型推理)如何进行技术实现?模型推理可通过“PyTorch原生推理、Transformers库推理、FastAPI服务化”三种方式实现,三者构成从“代码”到“服务”的完整技术链,分别对应“开发验证、快速部署、工业级服务”三大核心场景。
1. PyTorch 原生推理:开发调试的“零封装”方案
直接加载训练好的.pt/.pth模型,通过model.eval() + torch.no_grad()切换推理模式,复用训练代码逻辑(代码复用率超85%)。
import torchfrom ultralytics import YOLO # YOLOv8专用库from PIL import Image# 1. 加载预训练的YOLOv8模型(支持多种尺寸:nano/small/medium/large/x-large)model = YOLO('yolov8n.pt')# 2. 切换至推理模式(YOLOv8自动处理,无需手动调用eval())# 3. 设置计算设备(GPU加速)device = 'cuda' if torch.cuda.is_available() else 'cpu'model.to(device) # 将模型移至GPU/CPU# 4. 加载输入图像image_path = "test_image.jpg"image = Image.open(image_path).convert("RGB")# 5. 执行推理(自动预处理、推理、后处理)results = model(image) # 输入支持PIL/OpenCV/numpy格式# 6. 解析检测结果(直接输出结构化数据)predictions = results[0].boxes.data # 获取检测框数据(Tensor格式)print("检测结果(原始Tensor):\n", predictions)# 7. 转换为DataFrame格式df = results[0].pandas().xyxy[0] # 转换为Pandas DataFrameprint("结构化检测结果:\n")print(df[['xmin', 'ymin', 'xmax', 'ymax', 'confidence', 'class', 'name']])# 8. 可视化与保存结果results[0].show() # 显示带标注的图像results[0].save("output/") # 保存结果到output目录
2. Transformers 库推理:预训练模型的“一键式”部署
通过Hugging Face的transformers库加载预训练模型(基于Transformer架构的
Qwen、DeepSeek等大语言模型),实现“模型加载→推理→后处理”全流程封装。
from transformers import AutoTokenizer, AutoModelForCausalLM# 1. 加载模型和分词器model = AutoModelForCausalLM.from_pretrained("llama-7b")tokenizer = AutoTokenizer.from_pretrained("llama-7b")# 2. 输入预处理input_text = "解方程:3x + 5 = 32"input_ids = tokenizer(input_text, return_tensors="pt").input_ids# 3. 推理生成output = model.generate(input_ids, max_length=100)# 4. 后处理answer = tokenizer.decode(output[0], skip_special_tokens=True)print(answer) # 输出:"步骤1:两边减5 → 3x=27;步骤2:两边除以3 → x=9"
3. FastAPI 服务化:推理逻辑的“工业级”封装
将PyTorch/Transformers的推理代码封装为RESTful API,通过FastAPI框架支持高并发请求,结合Nginx负载均衡实现生产环境部署。
from fastapi import FastAPI, File, UploadFilefrom PIL import Imageimport torchfrom io import BytesIOimport base64# 初始化FastAPI应用app = FastAPI()# 加载预训练的YOLOv8模型(目标检测)model = torch.hub.load('ultralytics/yolov5', 'yolov8s') # 'yolov8s'为YOLOv8的小模型版本# 可选其他版本:'yolov8n'(nano)、'yolov8m'(medium)、'yolov8l'(large)、'yolov8x'(extra-large)@app.post("/predict")async def predict(image: UploadFile = File(...)):# 1. 读取上传的图像contents = await image.read()image_pil = Image.open(BytesIO(contents)).convert("RGB")# 2. 执行推理(YOLO自动处理预处理和后处理)results = model(image_pil)# 3. 解析结果detections = results.pandas().xyxy[0] # 转换为DataFrame格式output = []for _, row in detections.iterrows():output.append({"class": row["name"],"confidence": row["confidence"],"bbox": [row["xmin"], row["ymin"], row["xmax"], row["ymax"]]})# 4. 返回结果(可选:返回带标注的图像Base64编码)results.render() # 在图像上绘制检测框buffered = BytesIO()results.save(save_dir=buffered, format="JPEG") # 保存到内存image_base64 = base64.b64encode(buffered.getvalue()).decode("utf-8")return {"detections": output,"image_with_boxes": image_base64 # 可选字段}# 启动命令:uvicorn main:app --host 0.0.0.0 --port 8000
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









