






强化学习+Transformer不愧是发文香饽饽!近来在各顶会、顶刊上,都看到不少成果。像是Nature上用于算法发现的AlphaDev模型;Neurips上训练效率狂提55.18倍的SOTRM模型……
主要在于,强化学习一直都是AI领域的重要方向,但由于信用分配、样本效率低下、模型可解释性不足等问题,限制了其应用!而Transformer在处理长序列数据、捕捉复杂依赖关系、多模态信息融合方面的优势,则有助于解决这些挑战!同时,还能增强模型的泛化能力和扩展性,实现更高效、更可靠的决策。
目前热门的方向有:架构增强、轨迹优化、多智能体强化学习、离线强化学习等。
为方便大家研究的进行,早点发出自己的文章,我给大家梳理了16种前沿创新思路和源码,全部来自顶会。
论文原文+开源代码需要的同学看文末
【NeurIPS24 Spotlight】Reinforcement Learning Gradients as Vitamin for Online Finetuning Decision Transformers
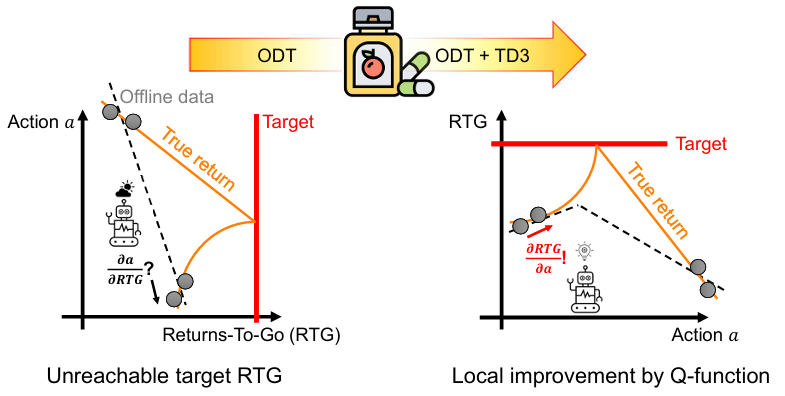
内容:文章指出尽管决策Transformers在离线强化学习中表现出色,但其在线微调却鲜有研究。特别是,当使用低回报的离线数据进行预训练时,现有的ODT在性能上存在挑战。文章通过理论分析发现,常用的RTG方法由于远离预期回报,会阻碍在线微调过程。然而,这个问题可以通过标准RL算法中的值函数和优势函数得到很好的解决。
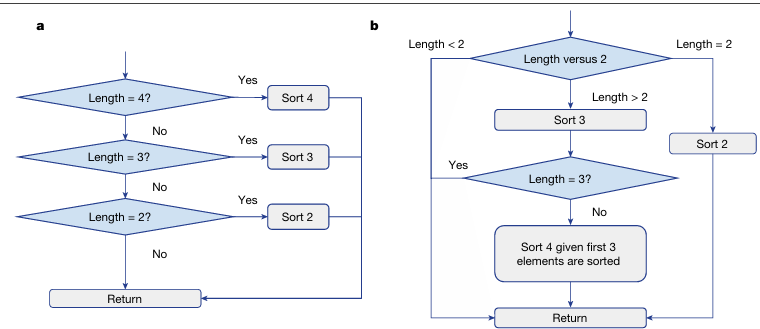
【Nature】Faster sorting algorithms discovered using deep reinforcement learning
内容:文章提出如何利用深度强化学习来发现更快的排序算法。研究团队设计了一个DRL框架,让智能体通过与环境的交互来学习如何排序。这个智能体能够探索各种可能的排序决策,并根据结果获得奖励或惩罚,从而逐步优化其策略。经过训练,智能体不仅学会了已知的高效排序算法,如快速排序和归并排序,而且还独立发现了一些新的高效排序算法。
STORM:Efficient Stochastic Transformer based World Models for Reinforcement Learning
内容:文章提出强化学习中构建世界模型。这种模型通过结合Transformers架构和随机性来提高学习效率和性能,使得智能体能够更好地预测环境动态并做出决策。简而言之,STORM旨在通过利用变换器的强大能力和处理不确定性的能力,来提升强化学习算法的效果。

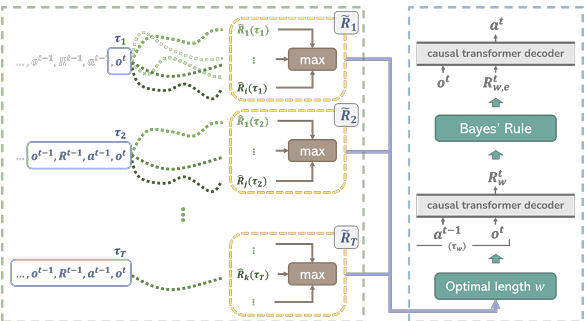
Elastic Decision Transformer
内容:文章提出一种用于强化学习的新型算法框架,它通过引入弹性机制来优化决策过程中的探索和利用平衡。这种框架利用Transformer架构来处理序列决策问题,允许模型动态调整其决策策略,以适应不断变化的环境和任务要求。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【RLTR】获取完整论文
👇

















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









