






llama.cpp是一个高性能的CPU/GPU大语言模型推理框架,适用于消费级设备或边缘设备。开发者可以通过工具将各类开源大语言模型转换并量化成gguf格式的文件,然后通过llama.cpp实现本地推理。经过我的调研,相比较其它大模型落地方案,中小型研发企业使用llama.cpp可能是唯一的产品落地方案。关键词:“中小型研发企业”,“产品落地方案”。
中小型研发企业:相较动辄千万+的硬件投入,中小型研发企业只能支撑少量硬件投入,并且也缺少专业的研发人员。
产品落地方案:项目需要具备在垂直领域落地的能力,大多数情况下还需要私有化部署。
网上有不少介绍的文章,B站上甚至有一些收费课程。但是版本落后较多,基本已经没有参考价值。本文采用b3669版本,发布日期是2024年9月,参考代码:examples/main.cpp。由于作者(Georgi Gerganov)没有提供详细的接口文档,examples的代码质量也确实不高,因此学习曲线比较陡峭。本文旨在介绍如何使用llama.cpp进行推理和介绍重点函数,帮助开发人员入门,深入功能还有待研究。
一、推理流程
1. 过程描述
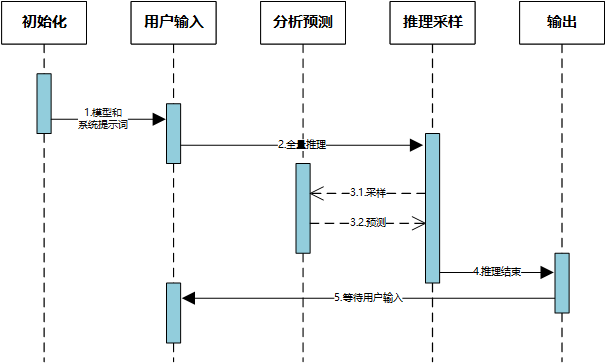
以常见的交互推理为例,程序大概可以分成5个子功能模块。
初始化:模型和系统提示词初始化。其实从程序处理过程上分析,并没有特别区分系统提示词与用户输入,实际项目开发中完全可以放在一起处理。后面会再解释它们在概念上的区别。
用户输入:等待用户输入文本信息。大语言模型其实就是对人类的文本信息进行分析和理解的过程,而产品落地的本质就是借助大模型的理解进一步完成一些指定任务。在这个过程中,互联网上又造了许多概念,什么agent,function等。其实本质上都是在研究如何将大模型与程序进一步结合并完成交互。至少目前,我的观点是:大模型仅具备语义分析,语义推理的能力。
分析预测:这个是大语言模型的核心能力之一,它需要分析上下文(系统提示词、用户输入、已推理的内容)再进一步完成下一个词语(token)的预测。
推理采样:这个是大语言模型的另一个核心能力,它需要从分析预测的结果中随机选择一个token,并将它作为输入反向发送给分析预测模块继续进行,直到输出结束(EOS)。
输出:这个模块严格说不属于大模型,但是它又是完成用户交互必须模块。从产品设计上,可以选择逐字输出(token-by-token)或者一次性输出(token-by-once)。
2. 概念介绍
角色(roles):大语言模型通常会内置三种角色:系统(system),用户(user),助手(assistant)。这三种角色并非所有模型统一指定,但是基本目前所有开源的大模型都兼容这三种角色的交互,它有助于大模型更好的理解人类语境并完成任务。system表示系统提示词,就是我们常说的prompt。网上有不少课程将写系统提示词描述为提示词工程,还煞有介事的进行分类,其实大可不必。从我的使用经验看,一个好的系统提示词(prompt)应具备三个要点即可:语义明确,格式清晰,任务简单。语义明确即在系统提示词中尽量不要使用模棱两可的词语,用人话说就是“把问题说清楚”。格式清晰即可以使用markdown或者json指定一些重要概念。如果你需要让大模型按照某个固定流程进行分析,可以使用markdown的编号语法,如果你需要将大模型对推理结果进行结构化处理,可以使用json语法。任务简单即不要让大模型处理逻辑太复杂或者流程太多的任务。大模型的推理能力完全基于语义理解,它并不具备严格意义上的程序执行逻辑和数学运算逻辑。这就是为什么,当你问大模型:1.11和1.8谁大的时候,它会一本正经的告诉你,当整数部分一样大的时候,仅需要比较小数部分,因为11大于8,因此1.11大于1.8。那么如果我们现实中确实有一些计算任务或复杂的流程需要处理怎么办?我的解决方案是,与程序交互和动态切换上下文。除了系统角色以外,用户一般代表输入和助手一般代表输出。
token:这里不要理解为令牌,它的正确解释应该是一组向量的id。就是常见的描述大模型上下文长度的单位。一个token代表什么?互联网上有很多错误的解释,比较常见说法是:一个英文单词为1个token,一个中文通常是2-3个token。上面的流程介绍一节,我已经解释了“分析预测”与“采样推理”如何交互。“推理采样”生成1个token,反向输送给“分析预测”进行下一个token的预测,而输出模块可以选择token-by-token的方式向用户输出。实际上,对于中文而言,一个token通常表示一个分词。例如:“我爱中国”可能的分词结果是“我”,“爱”,“中国”也可能是“我”,“爱”,“中”,“国”。前者代表3个token,后者代表4个token。具体如何划分,取决于大模型的中文指令训练。除了常见的代表词语的token以外,还有一类特殊token(special token),例如上文提到的,大模型一个字一个字的进行推理生成,程序怎么知道何时结束?其实是有个eos-token,当读到这个token的时候,即表示本轮推理结束了。
3. 程序结构
llama.cpp的程序结构比较清晰,核心模块是llama和ggmll。ggml通过llama进行调用,开发通常不会直接使用。在llama中定义了常用的结构体和函数。common是对llama中函数功能的再次封装,有时候起到方便调用的目的。但是版本迭代上,common中的函数变化较快,最好的方法是看懂流程后直接调用llama.h中的函数。
4. 源码分析
下面我以examples/main/main.cpp作为基础做重点分析。
(1) 初始化
全局参数,这个结构体主要用来接收用户输入和后续用来初始化模型与推理上下文。
gpt\_params params;
系统初始化函数:
llama\_backend\_init();
llama\_numa\_init(params.numa);
系统资源释放函数:
llama\_backend\_free();
创建模型和推理上下文:
llama\_init\_result llama\_init = llama\_init\_from\_gpt\_params(params);
llama\_model \*model = llama\_init.model;
llama\_context \*ctx = llama\_init.context;
它声明在common.h中。如果你需要将模型和上下文分开创建可以使用llama.h中的另外两对函数:
llama\_model\_params model\_params = llama\_model\_params\_from\_gpt\_params(gpt\_params\_);
llama\_model\_ \= llama\_load\_model\_from\_file(param.model.c\_str(), model\_params);
llama\_context\_params ctx\_eval\_params \= llama\_context\_params\_from\_gpt\_params(gpt\_params\_);
llama\_context \*ctx\_eval = llama\_new\_context\_with\_model(llama\_model\_, ctx\_eval\_params);
创建ggml的线程池,这个过程可能和模型加速有关,代码中没有对它的详细解释:
struct ggml\_threadpool \* threadpool = ggml\_threadpool\_new(&tpp);
llama\_attach\_threadpool(ctx, threadpool, threadpool\_batch);
除了完成一般的推理任务,llama.cpp还实现了上下文存储与读取。上下文切换的前提是不能换模型,且仅首次推理接收用户输入的prompt。利用这个特性,可以实现上下文的动态切换。
std::string path\_session = params.path\_prompt\_cache;
std::vector<llama\_token> session\_tokens;
至此,有关系统初始化模块的过程已经完成。
(2) 用户输入
为了接收用户输入和推理输出,源码集中定义了几个变量:
std::vector<llama\_token> embd\_inp;
std::vector<llama\_token> embd;
检查编码器,现代模型大多都没有明确定义的encodec
if (llama\_model\_has\_encoder(model)) {
int enc\_input\_size = embd\_inp.size();
llama\_token \* enc\_input\_buf = embd\_inp.data();
if (llama\_encode(ctx, llama\_batch\_get\_one(enc\_input\_buf, enc\_input\_size, 0, 0))) {
LOG\_TEE("%s : failed to eval\\n", \_\_func\_\_);
return 1;
}
llama\_token decoder\_start\_token\_id \= llama\_model\_decoder\_start\_token(model);
if (decoder\_start\_token\_id == -1) {
decoder\_start\_token\_id \= llama\_token\_bos(model);
}
embd\_inp.clear();
embd\_inp.push\_back(decoder\_start\_token\_id);
}
(3) 分析预测
分析预测部分的核心代码如下,我将处理关注力和session的逻辑删除,仅保留推理部分的逻辑。
// predict
if (!embd.empty()) {
// Note: (n\_ctx - 4) here is to match the logic for commandline prompt handling via
// --prompt or --file which uses the same value.
int max\_embd\_size = n\_ctx - 4;
// Ensure the input doesn't exceed the context size by truncating embd if necessary.
if ((int) embd.size() > max\_embd\_size) {
const int skipped\_tokens = (int) embd.size() - max\_embd\_size;
embd.resize(max\_embd\_size);
console::set\_display(console::error);
printf("<<input too long: skipped %d token%s>>", skipped\_tokens, skipped\_tokens != 1 ? "s" : "");
console::set\_display(console::reset);
fflush(stdout);
}
for (int i = 0; i < (int) embd.size(); i += params.n\_batch) {
int n\_eval = (int) embd.size() - i;
if (n\_eval > params.n\_batch) {
n\_eval \= params.n\_batch;
}
LOG("eval: %s\\n", LOG\_TOKENS\_TOSTR\_PRETTY(ctx, embd).c\_str());
if (llama\_decode(ctx, llama\_batch\_get\_one(&embd\[i\], n\_eval, n\_past, 0))) {
LOG\_TEE("%s : failed to eval\\n", \_\_func\_\_);
return 1;
}
n\_past += n\_eval;
LOG("n\_past = %d\\n", n\_past);
// Display total tokens alongside total time
if (params.n\_print > 0 && n\_past % params.n\_print == 0) {
LOG\_TEE("\\n\\033\[31mTokens consumed so far = %d / %d \\033\[0m\\n", n\_past, n\_ctx);
}
}
}
embd.clear();
逻辑的重点是:首先,如果推理的上下文长度超限,会丢弃超出部分。实际开发中可以考虑重构这个部分的逻辑。其次,每次推理都有一个处理数量限制(n_batch),这主要是为了当一次性输入的内容太多,系统不至于长时间无响应。最后,每次推理完成,embd都会被清理,推理完成后的信息会保存在ctx中。
(4) 推理采样
采样推理部分的源码分两个部分:
if ((int) embd\_inp.size() <= n\_consumed && !is\_interacting) {
// optionally save the session on first sample (for faster prompt loading next time)
if (!path\_session.empty() && need\_to\_save\_session && !params.prompt\_cache\_ro) {
need\_to\_save\_session \= false;
llama\_state\_save\_file(ctx, path\_session.c\_str(), session\_tokens.data(), session\_tokens.size());
LOG("saved session to %s\\n", path\_session.c\_str());
}
const llama\_token id = llama\_sampling\_sample(ctx\_sampling, ctx, ctx\_guidance);
llama\_sampling\_accept(ctx\_sampling, ctx, id, /\* apply\_grammar= \*/ true);
LOG("last: %s\\n", LOG\_TOKENS\_TOSTR\_PRETTY(ctx, ctx\_sampling->prev).c\_str());
embd.push\_back(id);
// echo this to console
input\_echo = true;
// decrement remaining sampling budget
--n\_remain;
LOG("n\_remain: %d\\n", n\_remain);
} else {
// some user input remains from prompt or interaction, forward it to processing
LOG("embd\_inp.size(): %d, n\_consumed: %d\\n", (int) embd\_inp.size(), n\_consumed);
while ((int) embd\_inp.size() > n\_consumed) {
embd.push\_back(embd\_inp\[n\_consumed\]);
// push the prompt in the sampling context in order to apply repetition penalties later
// for the prompt, we don't apply grammar rules
llama\_sampling\_accept(ctx\_sampling, ctx, embd\_inp\[n\_consumed\], /\* apply\_grammar= \*/ false);
++n\_consumed;
if ((int) embd.size() >= params.n\_batch) {
break;
}
}
}
首先要关注第2部分,这一段的逻辑是将用户的输入载入上下文中,由于用户的输入不需要推理,因此只需要调用llama_sampling_accept函数。第1部分只有当用户输入都完成以后才会进入,每次采样一个token,写进embd。这个过程和分析预测交替进行,直到遇到eos。
if (llama\_token\_is\_eog(model, llama\_sampling\_last(ctx\_sampling))) {
LOG("found an EOG token\\n");
if (params.interactive) {
if (params.enable\_chat\_template) {
chat\_add\_and\_format(model, chat\_msgs, "assistant", assistant\_ss.str());
}
is\_interacting \= true;
printf("\\n");
}
}
chat_add_and_format函数只负责将所有交互过程记录在char_msgs中,对整个推理过程没有影响。如果要实现用户输出,可以在这里处理。
二、关键函数
通过gpt_params初始化llama_model_params
struct llama\_model\_params llama\_model\_params\_from\_gpt\_params (const gpt\_params & params);
创建大模型指针
LLAMA\_API struct llama\_model \* llama\_load\_model\_from\_file(
const char \* path\_model,
struct llama\_model\_params params);
创建ggml线程池和设置线程池
GGML\_API struct ggml\_threadpool\* ggml\_threadpool\_new (struct ggml\_threadpool\_params \* params);
LLAMA\_API void llama\_attach\_threadpool(
struct llama\_context \* ctx,
ggml\_threadpool\_t threadpool,
ggml\_threadpool\_t threadpool\_batch);
通过gpt_params初始化llama_context_params
struct llama\_context\_params llama\_context\_params\_from\_gpt\_params (const gpt\_params & params);
LLAMA\_API struct llama\_context \* llama\_new\_context\_with\_model(
struct llama\_model \* model,
struct llama\_context\_params params);
对输入进行分词并转换成token
std::vector<llama\_token> llama\_tokenize(
const struct llama\_context \* ctx,
const std::string & text,
bool add\_special,
bool parse\_special = false);
获取特殊token
LLAMA\_API llama\_token llama\_token\_bos(const struct llama\_model \* model); // beginning-of-sentence
LLAMA\_API llama\_token llama\_token\_eos(const struct llama\_model \* model); // end-of-sentence
LLAMA\_API llama\_token llama\_token\_cls(const struct llama\_model \* model); // classification
LLAMA\_API llama\_token llama\_token\_sep(const struct llama\_model \* model); // sentence separator
LLAMA\_API llama\_token llama\_token\_nl (const struct llama\_model \* model); // next-line
LLAMA\_API llama\_token llama\_token\_pad(const struct llama\_model \* model); // padding
批量处理token并进行预测
LLAMA\_API struct llama\_batch llama\_batch\_get\_one(
llama\_token \* tokens,
int32\_t n\_tokens,
llama\_pos pos\_0,
llama\_seq\_id seq\_id);
LLAMA\_API int32\_t llama\_decode(
struct llama\_context \* ctx,
struct llama\_batch batch);
执行采样和接收采样
llama\_token llama\_sampling\_sample(
struct llama\_sampling\_context \* ctx\_sampling,
struct llama\_context \* ctx\_main,
struct llama\_context \* ctx\_cfg,
int idx = -1);
void llama\_sampling\_accept(
struct llama\_sampling\_context \* ctx\_sampling,
struct llama\_context \* ctx\_main,
llama\_token id,
bool apply\_grammar);
将token转成自然语言
std::string llama\_token\_to\_piece(
const struct llama\_context \* ctx,
llama\_token token,
bool special = true);
判断推理是否结束,注意,这个token可能和llama_token_eos获取的不一致。因此一定要通过这个函数判断
// Check if the token is supposed to end generation (end-of-generation, eg. EOS, EOT, etc.)
LLAMA\_API bool llama\_token\_is\_eog(const struct llama\_model \* model, llama\_token token);
三、总结
本文旨在介绍llama.cpp的基础用法,由于Georgi Gerganov更新较快,且缺少文档。因此可能有些解释不够准确。如果大家对框架和本文敢兴趣可以给我留言深入讨论。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1894
1894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









