






欢迎来到雲闪世界。一旦我们训练了一个监督机器学习模型来解决分类问题,如果这就是我们工作的结束,我们会很高兴,我们可以直接向他们输入新数据。我们希望它能正确地对所有内容进行分类。然而,实际上,模型做出的预测并非都是正确的。数据科学中有一句著名的名言,由一位英国统计学家创造:
“所有模型都是错误的,但有些模型是有用的。” CLEAR,James,1976 年。
那么,我们如何知道我们拥有的模型有多好呢?简而言之,我们通过评估模型预测的正确性来做到这一点。为此,我们可以使用几个指标。
2.模型如何做出预测?即模型如何对数据进行分类?

图 1:模型进行预测
假设我们已经训练了一个机器学习模型来对信用卡交易进行分类,并确定该交易是否为欺诈。该模型将使用交易数据并返回一个分数,该分数可以是 0 到 1 范围内的任意数字,例如 0.05、0.24、0.56、0.9875。在本文中,我们将定义一个默认阈值 0.5,这意味着如果模型给出的分数低于 0.5,则该模型将该交易归类为非欺诈(这是一个模型预测!)。如果模型给出的分数大于或等于 0.5,则该模型将该交易归类为欺诈(这也是一个模型预测!)。
实际上,我们不会使用默认值 0.5。我们会研究不同的阈值,以了解哪个阈值更适合优化模型的性能,但这个讨论留到以后再说。
3.混淆矩阵
混淆矩阵是可视化分类模型性能的基本工具。它有助于理解预测的各种结果,其中包括:
- 真正例 (TP)
- 假阳性(FP)
- 假阴性(FN)
- 真阴性 (TN)
让我们分解一下!
为了评估模型的有效性,我们需要将其预测与实际结果进行比较。实际结果也称为“现实”。因此,模型可能会将交易归类为欺诈,而事实上,客户会在同一笔交易中要求退款,声称他的信用卡被盗了。
在这种场景中,模型正确地将该交易预测为欺诈,即真正例(TP)。
在欺诈检测环境中,“正面”类别被标记为欺诈,“负面”类别被标记为非欺诈。
另一方面,当模型也将交易归类为欺诈时,就会出现假阳性(FP),但在这种情况下,客户没有报告其信用卡使用方面存在任何欺诈行为。因此,在这笔交易中,机器学习模型犯了一个错误。
真阴性(TN)是指模型将交易归类为非欺诈,而事实上,它不是欺诈。因此,模型做出了正确的分类。
假阴性(FN)是指模型将交易归类为非欺诈。但实际上,这是欺诈行为(客户报告了与该交易相关的信用卡欺诈活动)。在这种情况下,机器学习模型也犯了一个错误,但这是一种不同于假阳性的错误类型。
我们来看看图 2
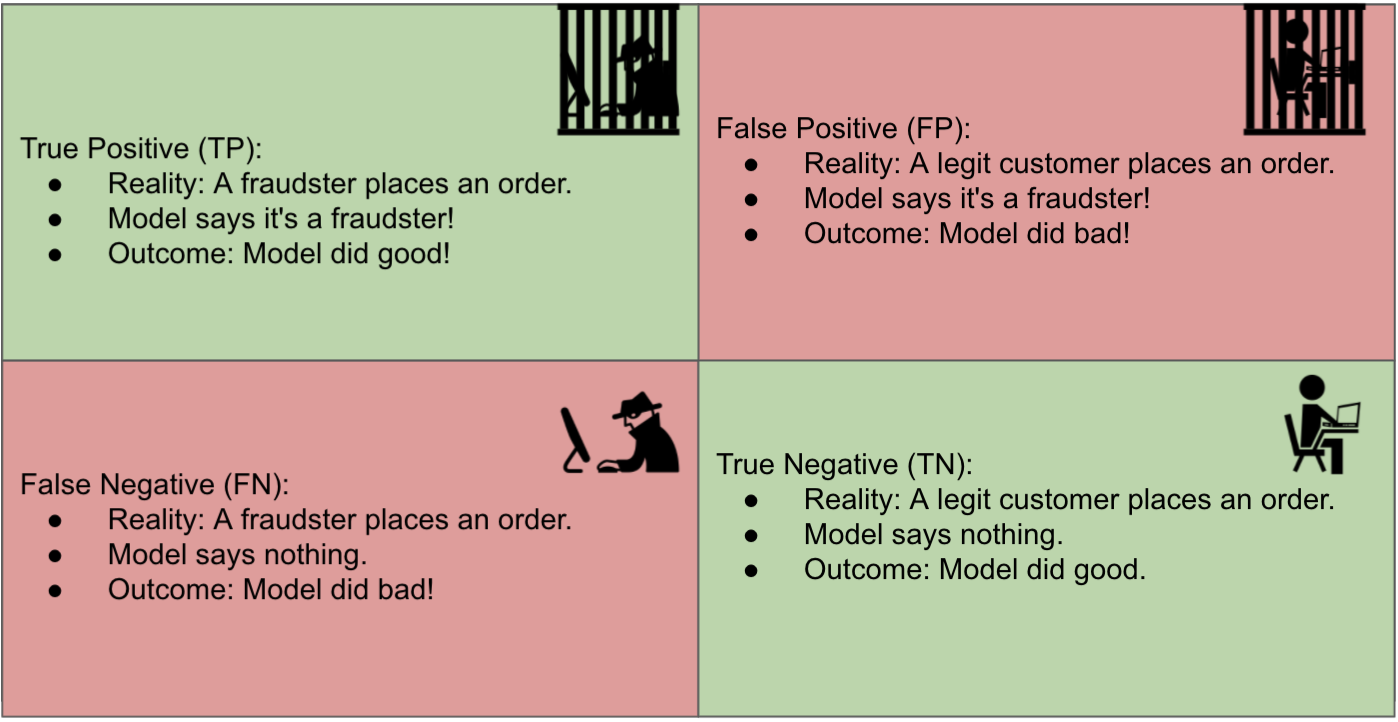
图 2:混淆矩阵对欺诈机器学习模型进行分类
让我们看一个不同的案例,也许更容易理解。一项测试旨在判断患者是否感染了 COVID。见图 3。
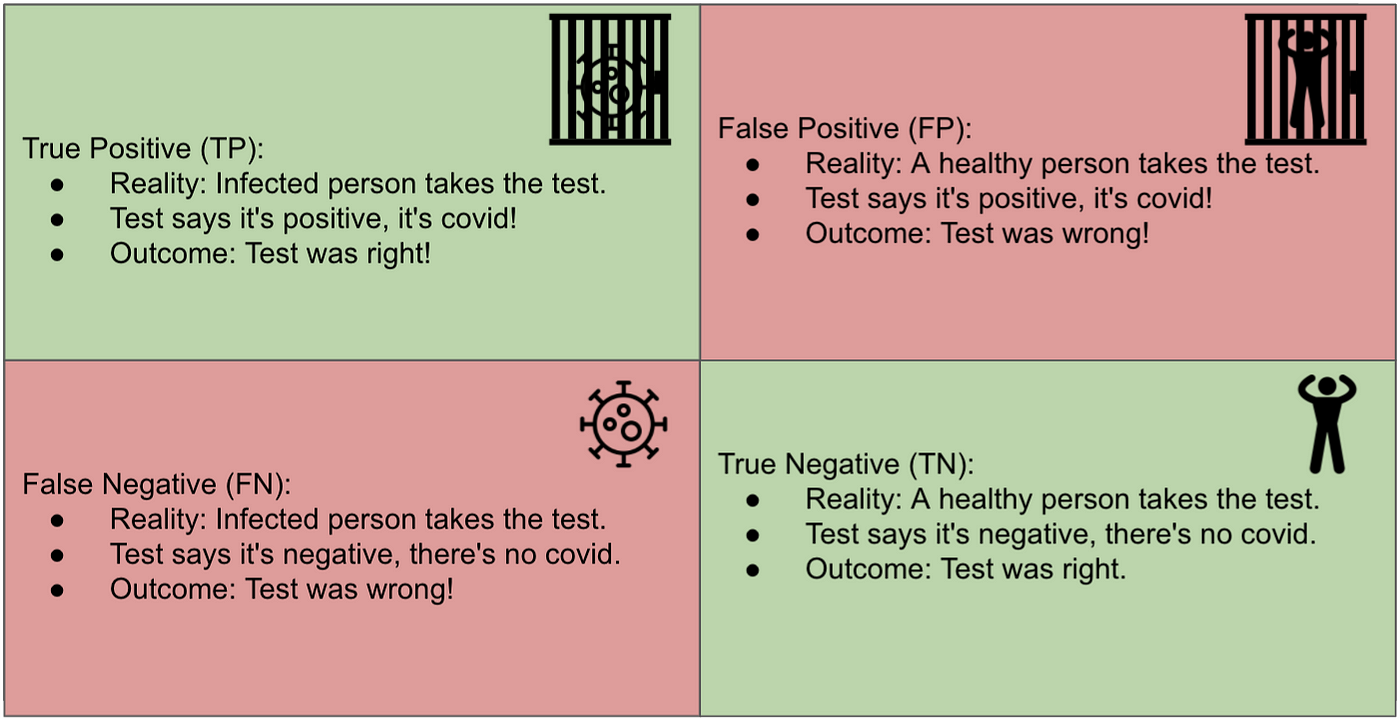
图 3:COVID 测试的混淆矩阵
因此,对于每笔交易,您都可以检查它是 TP、FP、TN 还是 FN。您可以对数以亿计的交易执行此操作,并将结果写在 2x2 表格中,其中包含 TP、FP、TN 和 FN 的所有计数。此表也称为混淆矩阵。
假设您将 100,000 笔交易的模型预测与实际结果进行了比较,并得出了以下混淆矩阵(见图 4)。
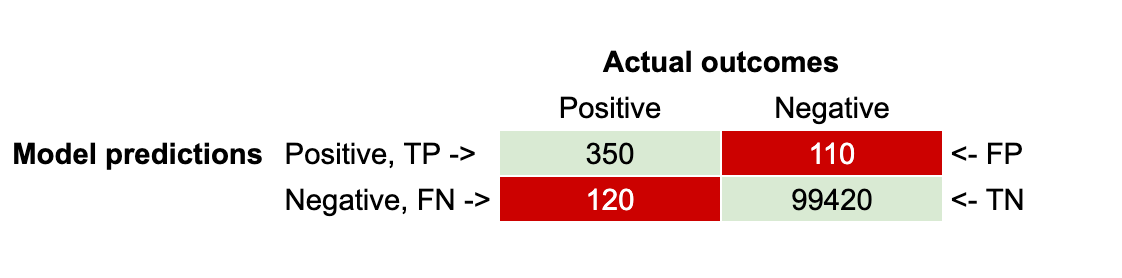
图 4:混淆矩阵
4.评估模型性能的指标
了解了什么是混淆矩阵之后,我们准备探索用于评估分类模型性能的指标。
准确率 = TP / (TP + FP)
它回答了这样一个问题:所有预测中正确预测的比例是多少?它反映了预测的欺诈案例中真正是欺诈的比例。
用简单的语言来说:当模型称其为欺诈时,它确实是欺诈的比例是多少?
查看图 4 中的混淆矩阵,我们计算出准确率 = 76.09%,因为准确率 = 350 / (350 + 110)。
召回率 = TP / (TP + FN)
召回率又称为真实阳性率(TPR)。它回答了以下问题:在所有实际阳性结果中,正确预测的比例是多少?
简单来说,在所有实际的欺诈案例中,该模型正确抓住欺诈者的次数占比是多少?
使用图 4 中的混淆矩阵,召回率 = 74.47%,因为召回率 = 350 / (350 + 120)。
警报率 = (TP + FP) / (TP + FP + TN + FN)
这个指标也称为阻止率,有助于回答以下问题:所有预测中正面预测的比例是多少?
用简单的语言来说:模型预测某事是欺诈的次数占比是多少?
使用图 4 中的混淆矩阵,警报率 = 0.46%,因为警报率 = (350 + 110) / (350 + 110 + 120 + 99420)。
F1 分数 = 2x (精确度 x 召回率) / (精确度 + 召回率)
F1 分数是准确率和召回率的调和平均值。它是准确率和召回率之间的平衡指标,可提供单一分数来评估模型。
使用图 4 中的混淆矩阵,F1 分数 = 75.27%,因为 F1 分数 = 2*(76.09% * 74.47%)/(76.09% + 74.47%)。
准确度 = TP + TN / (TP + TN + FP + FN)
准确性有助于回答这个问题:所有交易中正确分类的交易占比是多少?
使用图 4 中的混淆矩阵,准确度 = 99.77%,因为准确度 = (350 + 120) / (350 + 110 + 120 + 99420)。
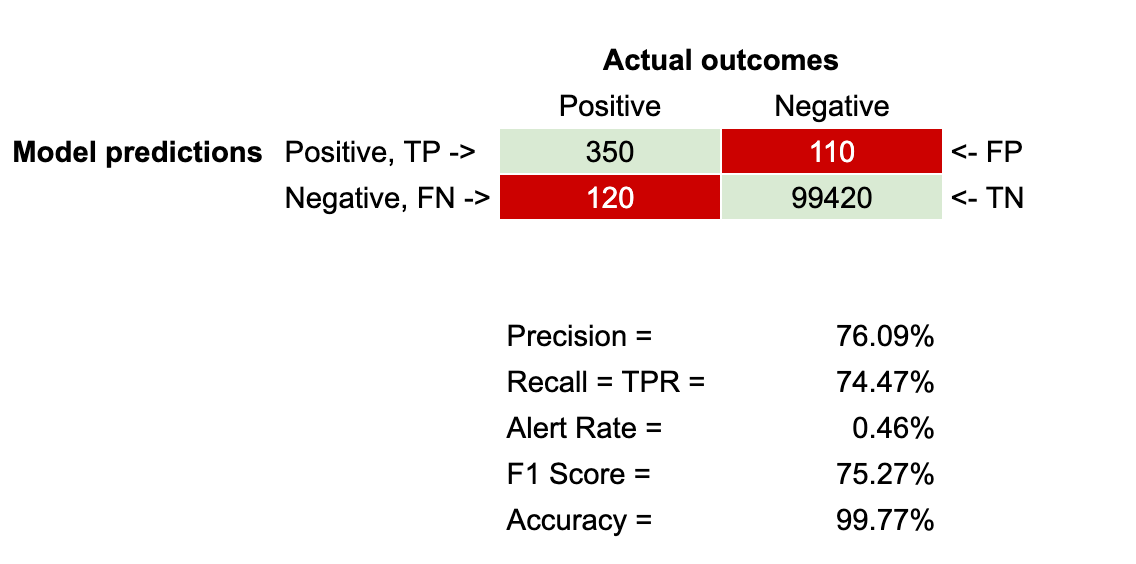
图 5:带有评估指标的混淆矩阵
5. 何时使用何种指标
准确度是评估许多分类机器学习模型的首选指标。然而,当目标变量不平衡时,准确度效果不佳。在欺诈检测中,通常只有极小比例的数据是欺诈性的;例如,在信用卡欺诈中,欺诈交易的比例通常不到 1%。因此,即使模型说所有交易都是欺诈性的(这是非常错误的),或者说所有交易都不是欺诈性的(这也是非常错误的),模型的准确度仍然会高于 99%。
那么在这些情况下该怎么办?准确率、召回率和警报率。这些通常是衡量模型性能的指标,即使数据不平衡。具体使用哪一个可能取决于您的利益相关者。我与利益相关者合作,他们说,无论你做什么,请保持至少 80% 的准确率。所以在这种情况下,利益相关者非常关心用户体验,因为如果准确率非常低,这意味着会有很多误报,这意味着模型会错误地阻止好客户,认为他们正在进行欺诈性信用卡交易。
另一方面,准确率和召回率之间存在权衡:准确率越高,召回率越低。因此,如果模型的准确率非常高,它就无法很好地发现所有欺诈案例。从某种意义上说,这还取决于欺诈案例给企业造成的损失(财务损失、合规问题、罚款等)与误报案例给企业造成的损失(客户生命周期,影响企业盈利能力)。
因此,在准确率和召回率之间的财务决策不明确的情况下,一个很好的指标是 F1 分数,它有助于在准确率和召回率之间取得平衡并对它们进行优化。
最后但并非最不重要的一点是,警报率也是一个需要考虑的关键指标,因为它可以直观地了解机器学习模型计划阻止的交易数量。如果警报率非常高,比如 15%,这意味着在客户下的所有订单中,15% 将被阻止,只有 85% 会被接受。因此,如果您的企业每天有 1,000,000 个订单,机器学习模型会阻止其中的 150,000 个订单,认为它们是欺诈交易。这是一个巨大的订单量,因此对欺诈案件的百分比有直觉很重要。如果欺诈案件约为 1% 或更少,那么阻止 15% 的模型不仅会犯很多错误,还会阻止很大一部分业务收入。
六,结论
了解这些指标可让数据科学家和分析师更好地解释分类模型的结果并提高其性能。准确率和召回率不仅比单纯的准确率更能洞悉模型的有效性,而且在欺诈检测等类别分布严重偏斜的领域尤其如此。
感谢关注雲闪世界。(亚马逊aws和谷歌GCP服务协助解决云计算及产业相关解决方案)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)















 1700
1700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









