






DeepSeek-R1微调指南
在这篇博文中,我们将逐步指导你在消费级 GPU 上使用 LoRA(低秩自适应)和 Unsloth 对 DeepSeek-R1 进行微调。
关于LangChat
LangChat 是Java生态下企业级AIGC项目解决方案,集成RBAC和AIGC大模型能力,帮助企业快速定制AI知识库、企业AI机器人。
支持的AI大模型: Gitee AI / 阿里通义 / 百度千帆 / DeepSeek / 抖音豆包 / 智谱清言 / 零一万物 / 讯飞星火 / OpenAI / Gemini / Ollama / Azure / Claude 等大模型。
- 官网地址:http://langchat.cn/
开源地址:
- Gitee:https://gitee.com/langchat/langchat
- Github:https://github.com/tycoding/langchat
微调DeepSeek-R1
微调像 DeepSeek-R1 这样的大型 AI 模型可能需要大量资源,但使用正确的工具,可以在消费级硬件上进行有效训练。让我们探索如何使用 LoRA(低秩自适应)和 Unsloth 优化 DeepSeek-R1 微调,从而实现更快、更具成本效益的训练。
DeepSeek 的最新 R1 模型正在设定推理性能的新基准,可与专有模型相媲美,同时保持开源。 DeepSeek-R1 的精简版本在 Llama 3 和 Qwen 2.5 上进行了训练,现在已针对使用 Unsloth(一种专为高效模型自适应而设计的框架)进行微调进行了高度优化。⚙
在这篇博文中,我们将逐步指导你在消费级 GPU 上使用 LoRA(低秩自适应)和 Unsloth 对 DeepSeek-R1 进行微调。
1、了解 DeepSeek-R1
DeepSeek-R1 是由 DeepSeek 开发的开源推理模型。它在需要逻辑推理、数学问题解决和实时决策的任务中表现出色。与传统 LLM 不同,DeepSeek-R1 的推理过程透明,适合……
1.1 为什么需要微调?
微调是将 DeepSeek-R1 等通用语言模型适应特定任务、行业或数据集的关键步骤。
微调之所以重要,原因如下:
- 领域特定知识:预训练模型是在大量通用知识库上进行训练的。微调允许针对医疗保健、金融或法律分析等特定领域进行专业化。
- 提高准确性:自定义数据集可帮助模型理解小众术语、结构和措辞,从而获得更准确的响应。
- 任务适应:微调使模型能够更高效地执行聊天机器人交互、文档摘要或问答等任务。
- 减少偏差:根据特定数据集调整模型权重有助于减轻原始训练数据中可能存在的偏差。
通过微调 DeepSeek-R1,开发人员可以根据其特定用例对其进行定制,从而提高其有效性和可靠性。
1.2 微调中的常见挑战及其克服方法
微调大规模 AI 模型面临多项挑战。以下是一些最常见的挑战及其解决方案:
a) 计算限制
- 挑战:微调 LLM 需要具有大量 VRAM 和内存资源的高端 GPU。
- 解决方案:使用 LoRA 和 4 位量化来减少计算负荷。将某些进程卸载到 CPU 或基于云的服务(如 Google Colab 或 AWS)也会有所帮助。
b) 在小型数据集上过度拟合
- 挑战:在小型数据集上进行训练可能会导致模型记住响应,而不是很好地进行泛化。
- 解决方案:使用数据增强技术和正则化方法(如 dropout 或 early stopping)来防止过度拟合。
c) 训练时间长
- 挑战:微调可能需要几天或几周的时间,具体取决于硬件和数据集大小。
- 解决方案:利用梯度检查点和低秩自适应 (LoRA) 来加快训练速度,同时保持效率。
d) 灾难性遗忘
- 挑战:微调后的模型可能会忘记预训练阶段的一般知识。
- 解决方案:使用包含特定领域数据和一般知识数据的混合数据集来保持整体模型准确性。
e) 微调模型中的偏差
- 挑战:微调模型可以继承数据集中存在的偏差。
- 解决方案:整理多样化且无偏差的数据集,应用去偏差技术并使用公平性指标评估模型。
有效应对这些挑战可确保稳健高效的微调过程。
2、设置环境
微调大型语言模型 (LLM) 需要大量计算资源。以下是推荐的配置:
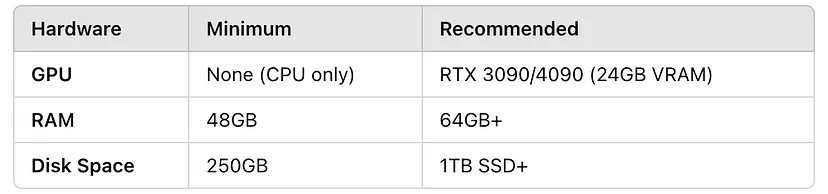 img
img
确保你拥有 Python 3.8+ 并安装必要的依赖项:
pip install unsloth torch transformers datasets accelerate bitsandbytes
3、加载预训练模型和 Tokenizer
使用 Unsloth,我们可以高效地以 4 位量化加载模型以减少内存使用量:
from unsloth import FastLanguageModel
model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B-unsloth-bnb-4bit"
max_seq_length = 2048
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=model_name,
max_seq_length=max_seq_length,
load_in_4bit=True,
)
4、准备数据集
微调需要结构化的输入输出对。让我们假设一个用于遵循指令任务的数据集:
{"instruction": "What is the capital of France?", "output": "The capital of France is Paris."}
{"instruction": "Solve: 2 + 2", "output": "The answer is 4."}
使用 Hugging Face 的数据集库加载数据集:
from datasets import load_dataset
dataset = load_dataset("json", data_files={"train": "train_data.jsonl", "test": "test_data.jsonl"})
使用聊天式提示模板格式化数据集:
prompt_template = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
"""
def preprocess_function(examples):
inputs = [prompt_template.format(instruction=inst) for inst in examples["instruction"]]
model_inputs = tokenizer(inputs, max_length=max_seq_length, truncation=True)
return model_inputs
tokenized_dataset = dataset.map(preprocess_function, batched=True)
5、应用 LoRA 进行高效微调
LoRA 允许通过仅训练模型的特定部分进行微调,从而显著减少内存使用量:
model = FastLanguageModel.get_peft_model(
model,
r=16, # LoRA rank
target_modules=["q_proj", "v_proj"], # Fine-tune key attention layers
lora_alpha=32,
lora_dropout=0.05,
bias="none",
use_gradient_checkpointing=True,
)
训练模型。配置训练参数。初始化并开始训练:
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
tokenizer=tokenizer,
)
trainer.train()
6、评估和保存模型
训练后,评估并保存微调后的模型:
# Evaluate the model
eval_results = trainer.evaluate()
print(f"Perplexity: {eval_results['perplexity']}")
# Save the model and tokenizer
model.save_pretrained("./finetuned_deepseek_r1")
tokenizer.save_pretrained("./finetuned_deepseek_r1")
7、部署模型进行推理
微调后,使用模型进行推理。本地部署llama.cpp,运行:
./llama.cpp/llama-cli \
--model unsloth/DeepSeek-R1-Distill-Llama-8B-GGUF/DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguf \
--cache-type-k q8_0 \
--threads 16 \
--prompt '<|User|>What is 1+1?<|Assistant|>' \
--n-gpu-layers 20 \
-no-cnv
8、结束语
通过利用 LoRA 和 Unsloth,我们成功地在消费级 GPU 上微调了 DeepSeek-R1,显著降低了内存和计算要求。这使得更快、更易于访问的 AI 模型训练成为可能,而无需昂贵的硬件。
DeepSeek无疑是2025开年AI圈的一匹黑马,在一众AI大模型中,DeepSeek以低价高性能的优势脱颖而出。DeepSeek的上线实现了AI界的又一大突破,各大科技巨头都火速出手,争先抢占DeepSeek大模型的流量风口。
DeepSeek的爆火,远不止于此。它是一场属于每个人的科技革命,一次打破界限的机会,一次让普通人也能逆袭契机。
DeepSeek的优点

掌握DeepSeek对于转行大模型领域的人来说是一个很大的优势,目前懂得大模型技术方面的人才很稀缺,而DeepSeek就是一个突破口。现在越来越多的人才都想往大模型方向转行,对于想要转行创业,提升自我的人来说是一个不可多得的机会。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 111
111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









