






 如果你对上面图中的词语经常听到,或有一定的了解,但仍感觉有些模糊,可以继续往下看。我将尽可能用简单的方式描述这些词语是什么、它们的历史背景、相互之间的关系,并通过实际的代码示例展示它们的工作过程。
如果你对上面图中的词语经常听到,或有一定的了解,但仍感觉有些模糊,可以继续往下看。我将尽可能用简单的方式描述这些词语是什么、它们的历史背景、相互之间的关系,并通过实际的代码示例展示它们的工作过程。
ChatGPT4.0发布后,突然铺天盖地都是人工智能的信息,以致于想不起ChatGPT出现之前是什么样子,前期的ChatGPT确实是有很多的一本正经地胡说八道,但是随着ChatGPT-4o发布后,整个回答质量比之前好很多,并且很多行业都开始拥抱大模型,大模型的发布更是层出不穷,涌现了非常多的概念,随之而来的还有焦虑,我们会不会被替代,焦虑又来源于未知,所以把它们的关系梳理清楚非常有必要。
一、大语言模型
1)为什么叫大语言模型?
首先,为什么叫大语言模型?我们可以拆分词语,从大、语言、模型三个维度来理解。
1、大

主要体现在参数规模大、数据规模大、计算资源消耗大、应用场景广泛,它们分别是:
-
参数规模大:大语言模型通常拥有数亿到数千亿甚至更多的参数。这些参数是模型学习和存储知识的基础,数量越多,模型的表达能力和拟合复杂模式的能力就越强;
-
数据规模大:训练这些模型的数据集非常庞大,通常包括数百万到数百亿个文档,涵盖了广泛的领域和话题,这使得模型能够学习到非常丰富的语言模式和知识;
-
计算资源消耗大:训练大语言模型需要使用大量的计算资源,包括高性能的GPU/TPU集群,这些资源的投入使得模型能够在合理的时间内完成训练;
-
应用场景广泛:由于其强大的学习能力,大语言模型可以应用于多种复杂的任务,如自然语言理解、生成、翻译、问答、对话系统等,比传统机器学习训练出来的模型,应用场景更广泛;
其中最难理解的应该是参数规模大,它可不是平时写代码的一个方法的输入参数。大模型参数可以被看作是神经网络的“记忆”,它们记录了模型对训练数据中语言模式的学习。具体来说,这些参数包括神经网络层之间的连接权重和偏置,控制了模型如何将输入数据(比如一句话的文本)转化为输出(比如下一句话的预测)。可以理解为这个模型的内部知识点,用一个比较形象的类比参数小和参数大的区别,如下图所示:
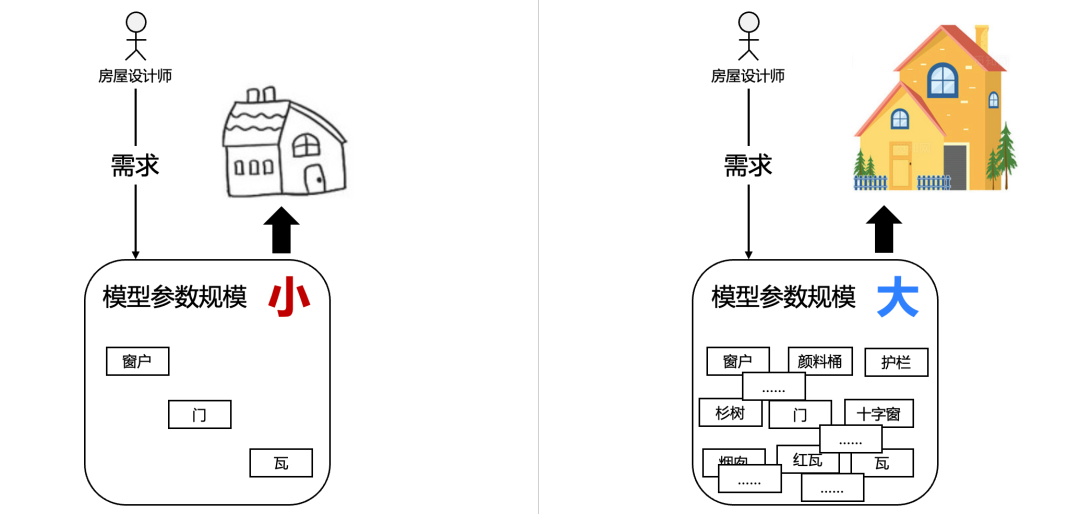
你可以把大语言模型想象成一个非常复杂的房屋设计师,每一个参数就像是设计中的一个小元件(如墙壁的位置、窗户的大小、屋顶的倾斜角度等)。如果设计师只有少数几个元件(少量参数),他只能设计非常简单的房屋,比如只有四面墙和一个屋顶的小屋子。然而,如果设计师有成千上万种元件可以调整(数以亿计的参数),那么他就能设计出非常复杂、多样化且符合各种需求的大厦。
2、语言
在大语言模型中,“语言”不仅仅是字面意义上的自然语言(如中文、英文等),更广泛地指代所有能够以文本形式表达的内容。这些模型通过学习自然语言中的模式、语法、语义、上下文关系等来理解和生成文本。
-
在训练阶段。 想象一个人正在学习写作,他每天阅读大量的书籍和文章,记住其中的句子结构、表达方式和常见的词汇搭配。随着阅读的增加,他越来越熟悉语言的使用规则,能够写出越来越复杂和连贯的句子。大语言模型在训练阶段就类似于这个过程:通过大量“阅读”(训练数据),不断调整自己的写作能力(参数)。
-
在推理阶段。 假设你问这个人,让他“写一段关于春天的描述”。基于他读过的书和文章,他能够迅速联想到春天相关的词汇(花朵、鸟鸣、温暖等),并用这些词汇写出一段合理的描述。大语言模型的推理阶段类似于这个过程:模型根据输入的提示或问题,从它的“记忆”中提取相关的语言模式来生成符合上下文的输出。
简单的例子
- 例1:句子补全
输入:”在晴朗的早晨,小明走到公园,看到了一只______。”
训练模型会利用其学习到的语言模式,推理可能的结尾词,如“鸟”、“松鼠”等。
- 例2:问题回答
输入:”地球上最大的哺乳动物是什么?”
通过训练中的语言知识(如百科知识的学习),模型推理出答案:“蓝鲸”。
- 例3:翻译
输入:”Hello, how are you?”
模型通过学习语言之间的对应关系,将句子翻译为中文:“你好,你怎么样?”
总之,语言在大语言模型中是核心,它不仅是模型的学习对象,也是推理过程中用于生成和理解的基础。通过训练,模型掌握了语言的使用规则和模式;在推理中,模型应用这些规则和模式来完成特定的任务。通过这种方式,语言成为了大语言模型理解和生成内容的关键。以上是简单的一个过程,在后面专门的训练章节,在深入探讨。
3、模型
模型这个词语非常抽象,在不同的语境下,有很多不一样的理解,一个简单的公式,一个判断逻辑都可以叫模型。如下图所示:

通过上图可知,模型的本质是一套数学计算逻辑,输入经过模型后得到结果。但是不同的是有些模型是人类编写的固定逻辑,有些模型是通过训练数据自动生成的逻辑,并不是人工编写出来的,其中机器学习模型、大语言模型等,通过训练出来的就是这样。
大语言模型内部非常复杂,很难说明内部长什么样子,简单理解就是把语言中的复杂关系用数学方式表示,其中就有向量和矩阵,模型内部的参数(如权重矩阵和偏置向量)以矩阵或向量的形式存在,这些参数决定了输入如何被转化为输出。一个模型训练完成后,输出的形式如下:
model_directory/``├── config.json # 模型的配置文件,包含模型架构、层数、隐藏单元数、激活函数类型等信息``├── tokenizer.json # 分词器配置文件,定义如何将文本拆分为模型能够理解的输入单元``├── vocab.txt # 词汇表文件,列出模型使用的所有词汇和对应的ID``├── model.bin # 模型的主要参数文件,包含训练后的权重和偏置等大量参数``├── model.onnx # ONNX格式的模型文件,用于跨平台推理部署``├── pytorch_model.bin # PyTorch格式的权重文件,用于在PyTorch框架中加载模型``├── tensorflow_model.h5 # TensorFlow格式的权重文件,用于在TensorFlow框架中加载模型``├── special_tokens_map.json # 特殊标记映射文件,定义特殊符号(如[CLS]、[SEP]等)的用法``├── training_args.json # 训练参数文件,记录训练过程中使用的参数设置``└── README.md # 说明文件,描述如何加载和使用模型
复杂的模型里面有很多的元素,人类已经不能简单理解,大语言模型现在也没人能完全讲明白它的内部工作原理,也许如下图所示:

👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈
2)模型之间的区别与联系
规则模型、机器学习模型和大语言模型都是用于决策、预测或执行任务的工具,但它们在原理、应用场景和实现方式上有显著区别,如下图所示:
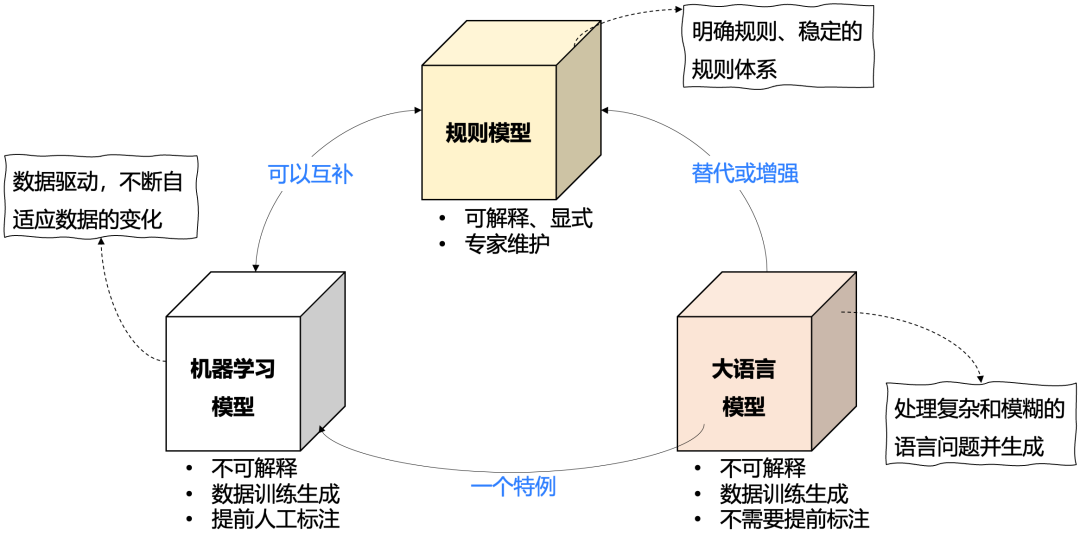
1、规则模型
规则模型是基于一组预定义的规则(if-then 逻辑)来做出决策,规则是由专家手动定义和维护的,系统按规则执行操作。可以用于业务规则管理、流程自动化、复杂事件处理等,如信贷审批、保险理赔等。其特点是显式的、可解释的,易于理解和修改,但不易扩展到复杂、不规则的数据模式。
这种显示规则是可以被人所理解的,能够做出符合预期的结果,具有100%的置信度,而接下来的机器学习模型和大语言模型却不是这样。
2、机器学习模型
许多早期的机器学习算法需要人工标记训练示例。例如,训练数据可能是带有人工标签(”狗”或”猫”)的狗或猫的照片。人们需要标记数据的需求使得创建足够大的数据集来训练强大的模型变得困难且昂贵。
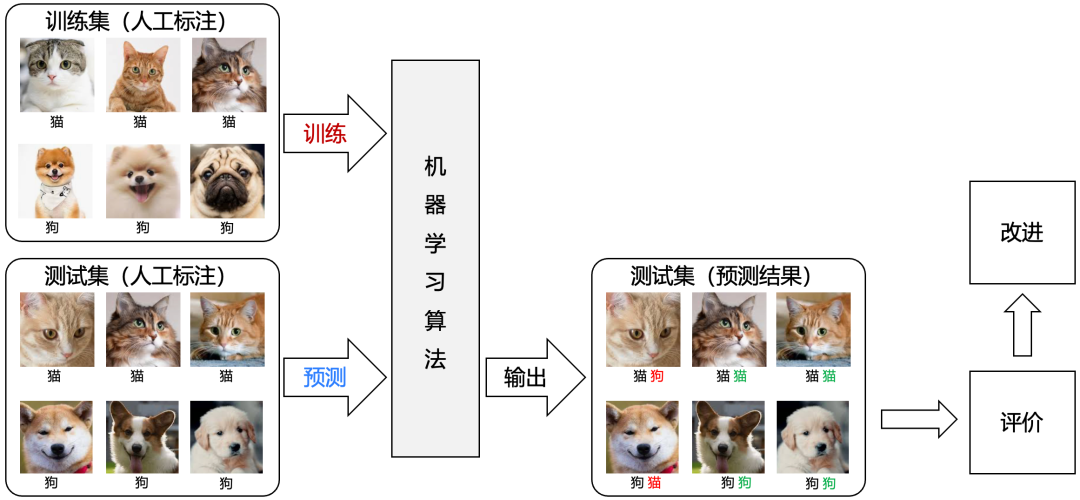
通过从数据中自动学习规律来进行预测或分类,模型通过训练数据集自动调整参数,从而最小化误差或最大化准确率。常见的机器学习模型包括线性回归、决策树、支持向量机、神经网络等,这些模型需要大量的训练数据,并依赖于数据的质量和数量,广泛用于图像识别、语音识别、推荐系统、预测分析等领域。其特点是依赖于数据,没有预定义规则,能够自动适应数据中的模式变化。或者说这些规则是人工所写不出来的,全靠数据的规律总结生成,所以其输出的结果并不是100%置信的,属于半解释型。
3、大语言模型
大语言模型本质上属于机器学习模型,是机器学习模型的一个特例,专注于自然语言处理任务,能够处理和生成自然语言,具有强大的理解和生成能力,但模型本身是“黑箱”的,不易解释。
4、临时表识别案例
在数据湖建设过程中,从业务系统的数据库中抽取数据时,有一个关键环节是识别临时表,若是临时表则不将其采集到数据湖中。尤其在建设初期,需要快速采集大量数据表,因此如何识别和过滤临时表,避免数据沼泽显得尤为重要。这一过程既可以人工进行,也可以借助模型来识别。为验证方法的有效性,可以进行相关试验测试,如下图所示:
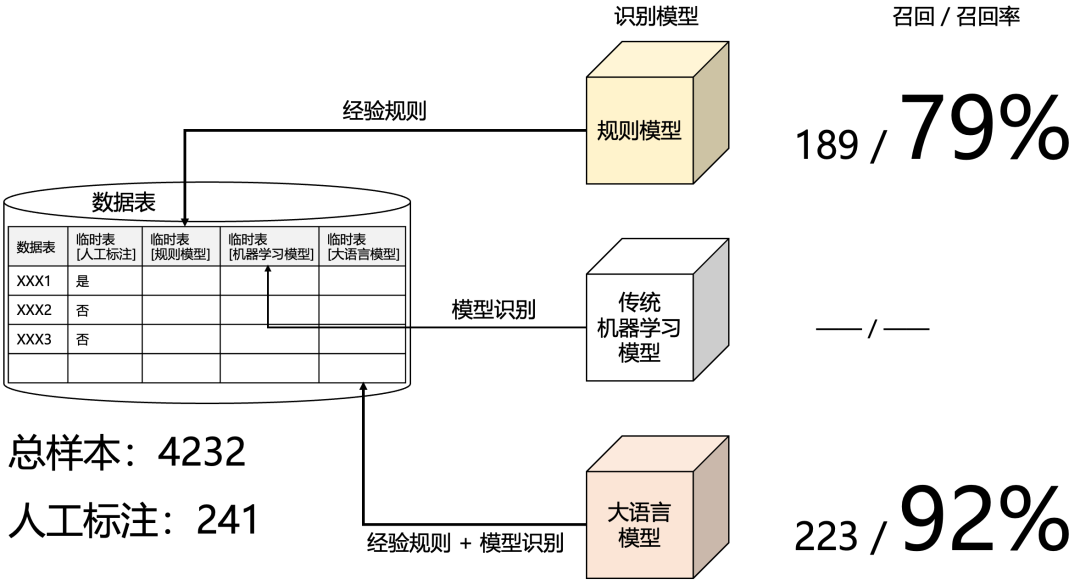
在4232条总样本数据中,通过人工标注发现241条为临时表。使用经验规则的模型进行识别,召回率达到79%;而结合经验规则与大语言模型的识别方案,召回率提高至92%。从结果来看,基于大语言模型的方案优于单纯的规则模型,同时具备更高的扩展性和灵活性。
召回: 是指模型能够找到多少个真正相关的项,并不关注不相关的项。同样也适用于通过模型能正确识别的数量;
召回率: 正确识别的个数 除以 真正正确的个数,是一个0到1的小数,数值越大说明模型识别率越高;
3)大语言模型的训练
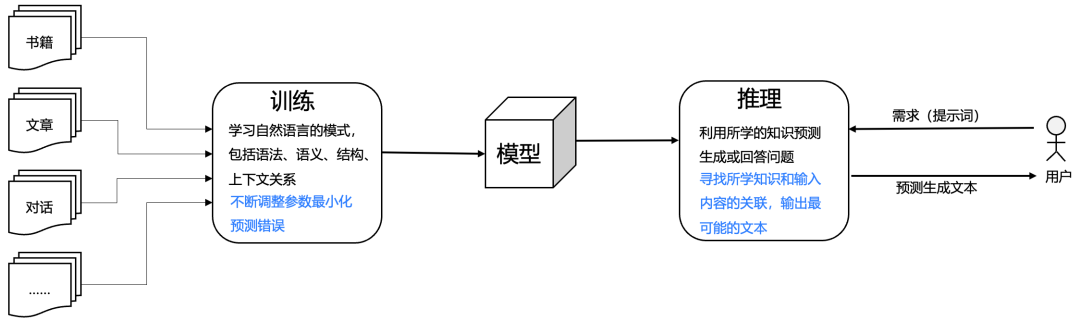
首先,它并不像传统的机器学习模型训练,需要人工做提前的标注。另一个很难理解的地方是它与传统的软件开发方式不同,一般的软件都是由程序员编写明确的、步骤式的指令,而大语言模型是建立在数十亿的语言词汇进行训练的神经网络之上。
语言模型的一个关键创新是它们不需要明确标记的数据。相反,它们通过尝试预测普通文本中的下一个单词来进行学习。几乎任何书面材料,从维基百科页面到新闻文章再到计算机代码,都适用于训练这些模型。
这里用到的第一个技术是:
1、词向量
向量可以简单理解为一个数组,一个浮点数数组,如[0.12,0.244,0.245,-0.43],数组的长度在向量里称作维,如这是一个4维向量。
一个文本单词,如”中国人“通过向量模型Word2Vec的转换后,得到一个固定维的向量,假设我们使用了一个300维的词向量模型,“中国人”的词向量可能是一个类似这样的向量(为了便于理解,这里只是一个简化的表示,实际向量会更复杂):
中国人 = [0.12, -0.34, 0.56, ....., 0.78]
为什么用这么复杂的向量来表示一个词语呢?我们可以看一个非常熟悉的列子,就是用经纬度坐标来表示一个位置,可以说是一个2维的向量,如下图所示:

上图所示,北京和天津距离最短,成都和重庆的距离最短,表现到经纬度上,经度 116.40与117.21,维度39.91与39.08是最相近的。其实每一个维都有具体的意义,而不是纯粹的数字,用来推理空间关系非常有用。通过词向量也可以解决同音异义词和多义词的问题,学习人类基于上下文识别的做法,但人类似乎没有总结出通用的经验和规则。
上面的词向量提取模型Word2Vec是Google开源的,经过大量文本提取向量训练后的模型,适合文本提取向量。
可以再做一个试验,例如人脸相似度识别,从一堆的人脸库中找到最相似的人脸,则首先要选择一个合适的人像向量提取模型,把人像图片位置和对应的向量存在向量数据库中,形成人脸库,最后进行相似度计算返回得分最高的。如下图所示:
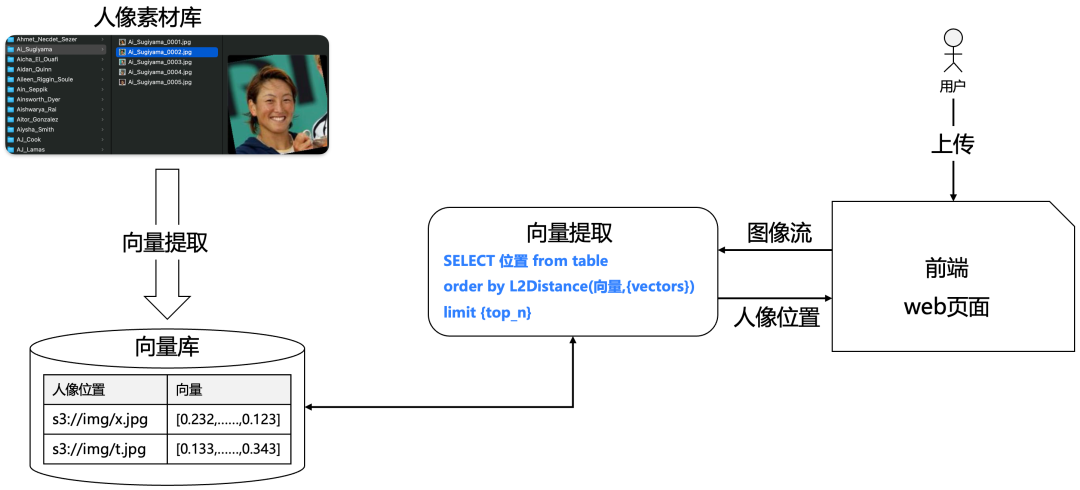
使用相同的素材库,同样的相似度计算算法,同样的流程,如果使用的提取向量模型不一样,结果差异非常大的,如下图所示:

常用的向量相似度计算算法主要包括以下几种:
-
欧氏距离(Euclidean Distance):测量两个向量之间的直线距离,是最常见的距离度量方式。适用于实值向量间的相似度计算,但对维度较高的向量可能不够准确。
-
余弦相似度(Cosine Similarity):通过计算两个向量的夹角余弦值来衡量相似度,适用于文本向量化后计算相似度的场景。余弦相似度值在 -1 到 1 之间,1 表示完全相同,0 表示完全无关。
-
曼哈顿距离(Manhattan Distance):也称为 L1 距离,通过计算两个向量对应坐标之差的绝对值之和来衡量距离,适用于稀疏向量的相似度计算。
-
杰卡德相似度(Jaccard Similarity):用于计算两个集合的交集与并集的比值,适合离散数据或集合的相似度比较。
-
Hamming 距离(Hamming Distance):用于衡量两个相同长度的二进制向量之间不同位的数量,适合处理离散的、定长的数据。
-
密切度(Dot Product/Inner Product):通过计算两个向量的内积来衡量相似性,常用于推荐系统中计算用户与物品之间的匹配程度。
-
马氏距离(Mahalanobis Distance):考虑数据分布情况的距离度量,可以消除特征之间的相关性影响,适用于多元数据分析。
通过上述的人像匹配示例可以知道,向量相似度计算算法虽然有很多种,但最关键的还是向量模型。因此,不同的场景和不同模态的数据,应该选择对应的合适向量提取模型。
自然语言模型正是使用词向量来表示词语,大语言模型也是使用了词向量技术,将自然语言理解问题转化为数学问题,就可以用数学做计算,后面结合训练过程再讲一下。
第二个技术是:
2、神经网络
Transformer 是目前大语言模型(LLM)训练中最常用的神经网络架构,它在自然语言处理领域的成功源于其创新的 自注意力机制(Self-Attention Mechanism),极大地改善了传统序列模型(如RNN和LSTM)在处理长序列时的效率和性能。其在大语言模型训练中的主要作用如下:
1.自注意力机制(Self-Attention)
自注意力机制是Transformer的核心组件,它能够在处理长文本时捕捉全局信息,而不依赖于固定的上下文窗口。通过这种机制,模型能够对序列中的每个词与其他词之间的关系进行建模,捕捉长距离依赖关系。例如,模型可以从句子的开头快速找到与句子结尾相关联的词汇,而不用逐层传递。
2.并行化处理
与传统的RNN不同,Transformer的注意力机制允许并行计算,因为每个词的表示可以同时更新,而不是像RNN那样依赖于前后顺序。这使得它在训练大语言模型时,特别是在处理大规模数据时,具有显著的计算优势。
3.更好的表达能力
Transformer的多层结构使得每一层都能够在前一层的基础上提取更高层次的特征,这种层次化的表示学习能力使得Transformer模型可以处理从基础的词汇语义到复杂的句法结构,具有强大的泛化能力。
4.扩展性
Transformer结构适用于大规模预训练,如BERT、GPT等著名大语言模型都基于这种架构。通过增加层数、注意力头数、参数量等,可以进一步扩展模型的表示能力。
4)大语言模型的推理
1、提示词
使用大语言模型的场景,就是我问你答的过程。
提示词就是你输入给大模型的内容,包括:”你好“,”你是谁?“,”帮我写一篇作业“,等等都可以叫提示词,只是要让大模型回答地更符合你的要求,就需要一些提示词的技巧。OpenAI的网站有提供提示词写法的文章,总结了6点:
1)清晰具体的指令。 其实就是跟平时说话、提需求一样,不要让模型猜你要什么。比如”帮我写一篇作业“这个提示词不好,应该可以更具体一点,”我是一个五年级的小学生,帮我写一篇《西游记》读后感作文,突出孙悟空的形象,字数500字“。

使用角色扮演,告诉大模型你现在是一个五年级的小学生,或者提供少样本 (Few-shot)。另外,可以要求大模型按固定格式输出,如JSON、Markdown等,方便输出内容通过程序进行解析。
2)提供参考内容,根据内容回答。 这是可以让大模型回答一些私有问题,避免出现胡说八道的一种方式,这也是RAG的一种方式。
# 系统` `你将会收到一个用三个引号标记的文档和一个问题。你的任务是仅使用所提供的文档来回答这个问题,并引用文档中用来回答问题的部分。如果文档中没有包含足够的信息来回答这个问题,就简单地写“信息不足”。如果提供了问题的答案,那么必须用引用标记。引用相关段落时,请使用以下格式({"citation": …})。``# 用户` `"""<插入文档>"""` `问题:<插入问题>
使用分割符区分不同的内容,如三个引号、XML标签、尖括号等。 |
3)任务分解,分类解决。 相较于简单的任务,复杂任务的错误率往往会更高。明确说明完成任务所需要的步骤,第一步:xxx;第二步:xxx;
你将获得由xx包含的文本,如果xxx,则。如果xxx,则直接写xxx。
因为提示词的长度在不同的语言模型,限制是不一样的,所以将一个大的任务拆解成小任务,再将小任务合并为最后输出,也是可以的。比如总结一本书的内容,可以每章总结,再最后总结。
4)给模型时间去”思考“。 指导模型先解答,再对比,才下结论。
|
**5)结合外部工具使用。**大语言模型本身没有执行代码和计算能力,可以结合外部API或执行环境,执行由大语言模型生成的代码。但是大语言模型生成的代码存在一定的风险,最好是一个隔离的环境。另外就是RAG,通过将文本分块向量化,利用向量相似度快速计算相关的块,作为提示词提供给大模型,让其从中回答问题,本质是RAG+大语言模型形成本地知识库。
提示词的编写,可以归纳为五步,如下图所示:

其中除了任务要求,其他都是可选的,加上会让大语言模型更容易生成你希望的结果。
完整提示词示例:
# 角色扮演``数据治理工程师`` ``# 提供内容``以下使用三个引号标记的内容是数据表的字段名,使用英文或中文拼音首字母缩写``"""user_name、XM、NL、BX、SG、XL、HYZK"""`` ``# 任务要求``将使用三个引号标记的内容,翻译成中文描述`` ``# 约束条件``如果不能正确翻译的,使用字段名输出即可`` ``# 输出格式``输出一个Markdown格式的表格,第一列是字段名,第二列是中文描述
输出结果:

其中BX是故意编写错误的缩写。
不同的大语言模型,即使使用相同的提示词,得出的结果质量也会有比较大的差别。
2、幻觉
大语言模型的“幻觉”(Hallucination)是指模型生成不准确或虚假的信息,即模型输出看似合理、流畅但实际上错误或不存在的内容。这种现象是由于模型仅基于其训练数据生成语言,而不是理解或验证生成内容的真实有效性。
例如,用户问一个大语言模型:“谁是2024年诺贝尔物理学奖得主?” 但当时还没有公布结果。模型可能会基于过去的模式和语境生成一个合理看似的回答,比如:“2024年诺贝尔物理学奖得主是John Doe,因为他在量子力学领域的杰出贡献。”然而,这个信息并不真实,因为“John Doe”并不是实际的得主,甚至可能是虚构的。这种错误就是大语言模型的幻觉,它表现为模型生成的内容虽然语言上符合逻辑,但缺乏事实依据。幻觉现象在任务关键性较高的应用(如医疗或法律咨询)中尤为需要注意,可能导致严重的误导。
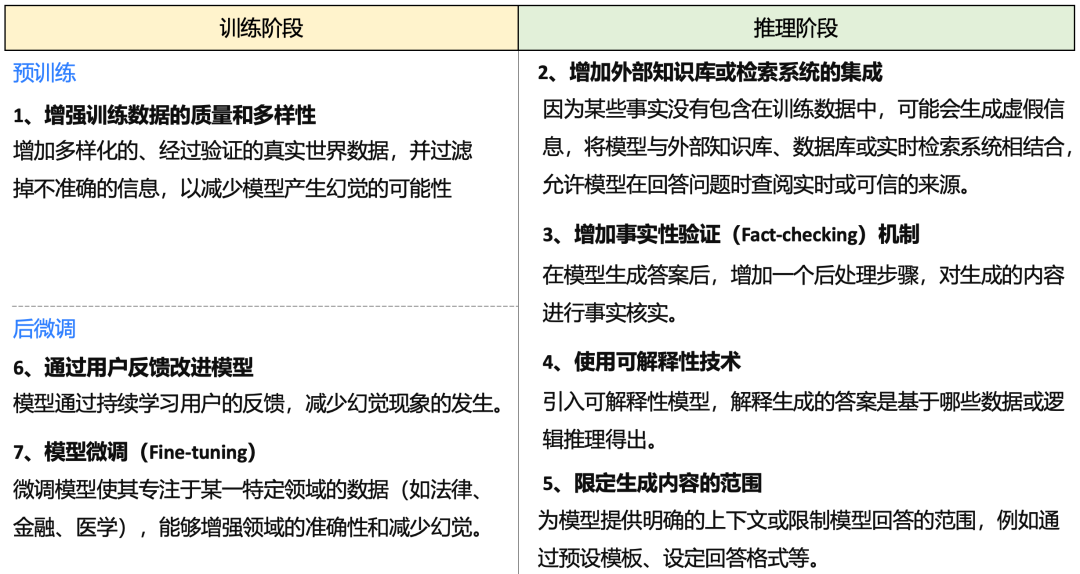
如何解决幻觉现象?
解决大语言模型的幻觉现象需要结合多个策略,包括优化训练数据、增加事实核查、引入外部知识库、限制输出范围等。虽然无法完全消除幻觉,但通过这些手段,可以显著减少幻觉带来的影响,提升模型的可靠性和实用性。如下图所示:
3、RAG
RAG(Retrieval-Augmented Generation)是一种结合信息检索和生成模型的框架,旨在提高生成式模型回答问题的准确性和事实性,特别是用于减少幻觉问题。它将传统的检索系统和生成模型结合起来,通过在生成答案前引入外部知识,从而增强模型的能力。过程如下图所示:
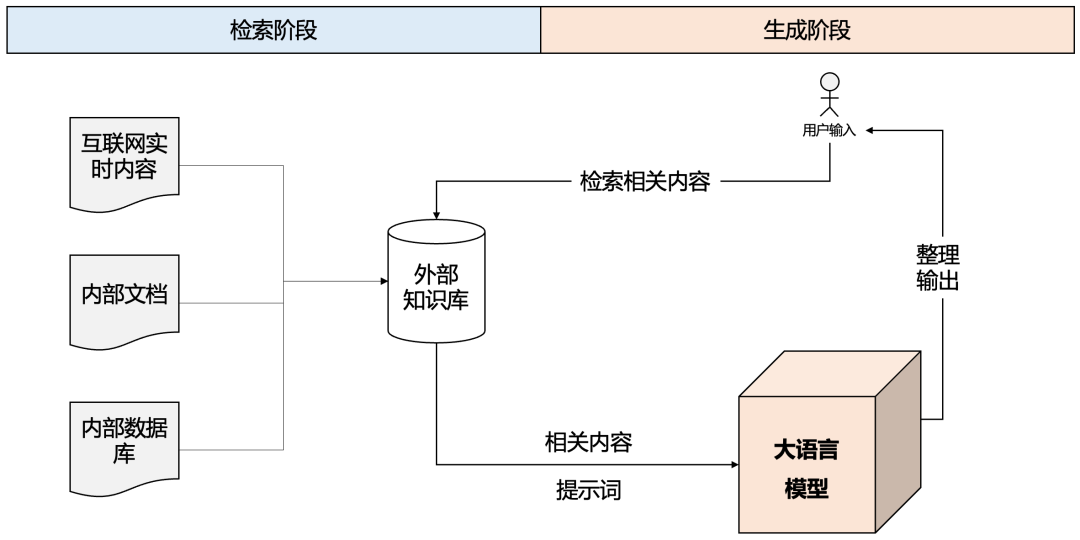
国内的Kimi和国外的Perplexity在使用时很明显能看到搜索了哪些网页,并引用它们进行结果生成。
4、GraphRAG
GraphRAG 是 Retrieval-Augmented Generation (RAG) 的一种扩展,它结合了图数据库和检索增强生成的概念,用于改进基于知识图谱的检索和回答生成任务。GraphRAG 将图数据库中的知识结构与生成模型的强大语言能力相结合,使得模型在生成回答时不仅依赖于文本检索,还可以利用图数据库中的结构化关系数据,从而提高回答的准确性和知识推理能力。过程如下图所示:
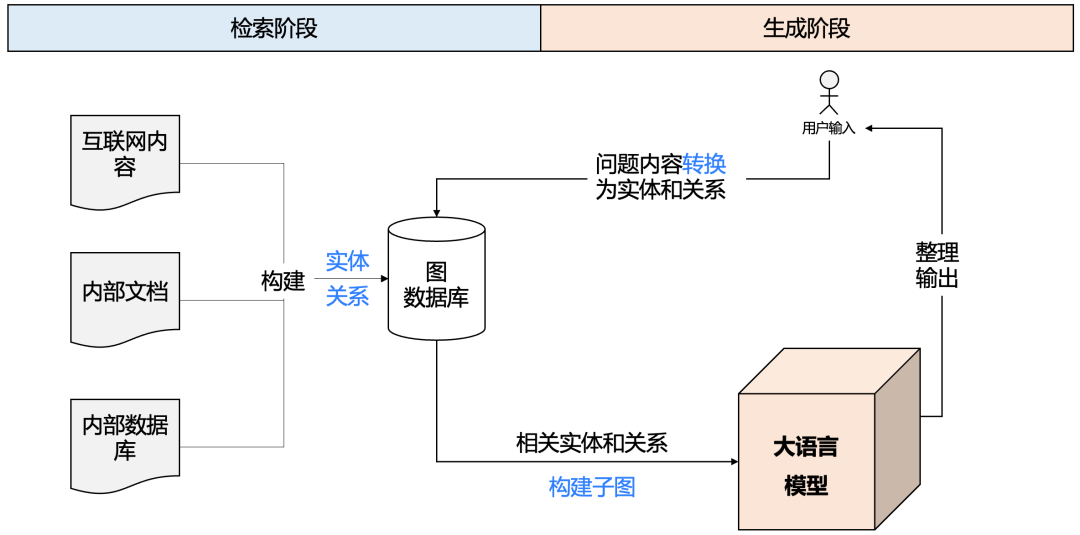
检索相关实体和关系,通常使用向量相似检索。
GraphRAG 的工作流程:
1、问题解析:用户提出一个问题,模型将其转换为需要检索的实体和关系。例如,用户问:“爱因斯坦和量子物理学的关系是什么?”
2、图数据库检索:GraphRAG 从图数据库中检索与“爱因斯坦”和“量子物理学”相关的节点和边。图数据库中可能已经存储了爱因斯坦的研究领域、贡献以及他与量子物理学的关系。
3、构建知识子图:基于检索到的实体和关系,构建一个与问题相关的知识子图,包含爱因斯坦的研究成果、相关的科学家、发表的论文等。
4、生成回答:生成模型结合知识子图和相关背景,生成一个连贯且准确的回答,可能会生成类似的回答:“爱因斯坦在量子物理学领域提出了光量子假说,但他对量子力学的解释并不完全接受,尤其是对其概率性质的质疑。”
5、微调
为什么要微调?
微调是为了让预训练的大模型适应特定任务和领域,提升其在这些任务上的表现。它不仅能够降低训练成本,还可以定制模型的行为,使其更适应用户需求和业务场景。通过微调,模型能够更好地理解和处理特定数据,从而在实际应用中表现得更加精准和高效。
所以,我们尝试微调大语言模型,看看整体的微调过程,这样就不会对微调感到那么神秘。微调总体结构图,如下所示:
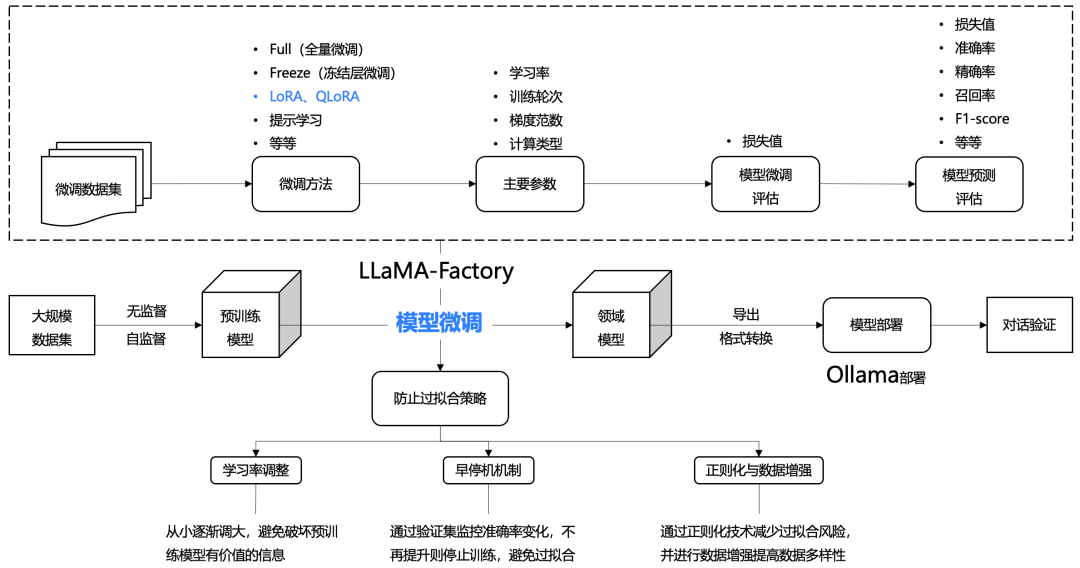
- 选择预训练模型
开源的预训练模型非常多,比如llama3.2、gemma2、qwen2.5,可以从https://huggingface.co/models查找(需要科学上网)。
- 使用LLaMA-Factory工具微调
LLaMA-Factory提供了命令行和webui两种微调方式,具体可以参考官网介绍。下面以webui的方式,查看微调的过程。
1、准备微调环境
安装Conda,构建独立的python环境
cd /data2/llm/``git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git``cd LLaMA-Factory`` ``conda create -n python311 python=3.10``conda activate python311``pip install -e ".[torch,metrics]"
2、使用web页面微调
cd /data2/llm/LLaMA-Factory``llamafactory-cli webui
启动webui后,访问http://xxx.xxx.xxx.xxx:7860/
微调前的对话,提问:“你好,你是谁?”,回答如下图所示:
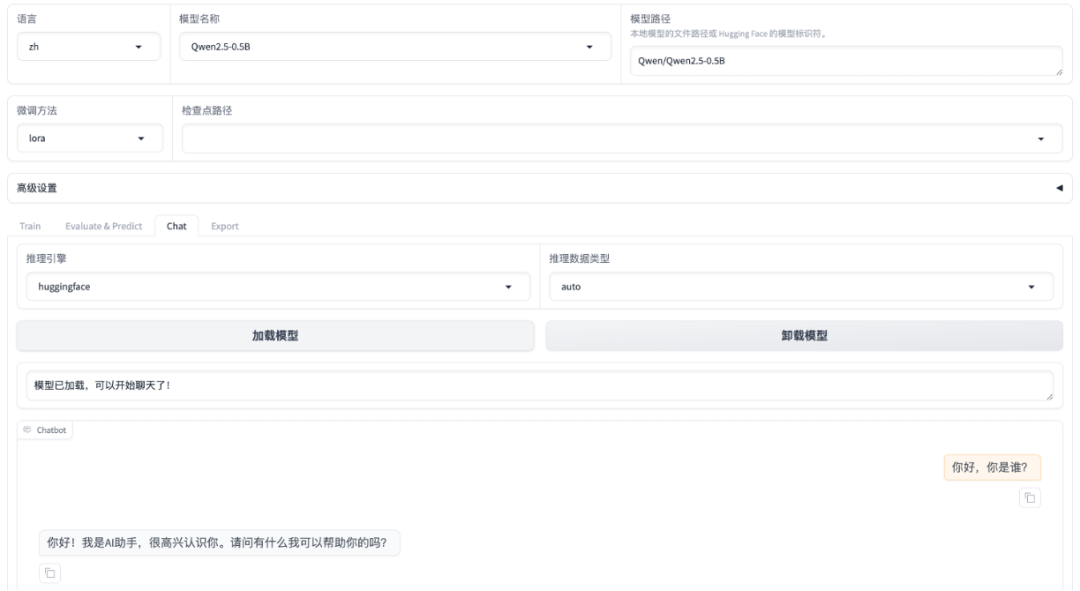
接下来,基于Qwen2.5-0.5B进行微调。
选择数据集:
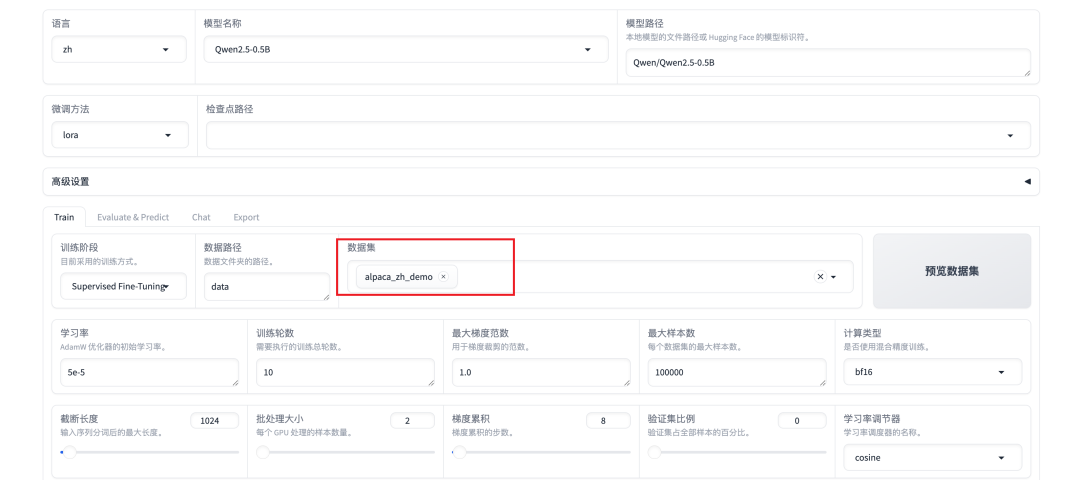
把/data2/llm/LLaMA-Factory/data/alpaca_zh_demo.json
的内容替换,就可以选择这个数据集。或者修改dataset_info.json,增加自己的配置项,包括数据集路径等。
下面是alpaca_zh_demo.json文件的示例内容,大概有9千多条。
[{` `"instruction": "是啊。可是我总还想着我们一起长大的情分呢。诶?妹妹今日打扮得好生素净,可是细看起来还是个美人坯子,怎么看都是好的。",` `"input": "",` `"output": "沈大美人差矣,姐姐出落得这么标致,皇上见过必定会念念不忘。"``},``{` `"instruction": "你是谁?",` `"input": "",` `"output": "家父是大理寺少卿甄远道。"``},``{` `"instruction": "大理寺少卿,也不是什么高官。",` `"input": "",` `"output": "凡事不论官位高低,只论个理字。"``},``]
如果加载模型报错,提示huggingface网址无法访问,因为下载模型需要科学上网,服务器没有联网,所以笔记本先模拟下载,再复制到服务器。在笔记本重复一次上述动作。
scp -r /Users/li/.cache/huggingface/hub root@xxx.xxx.xxx.xxx:/root/.cache/huggingface/
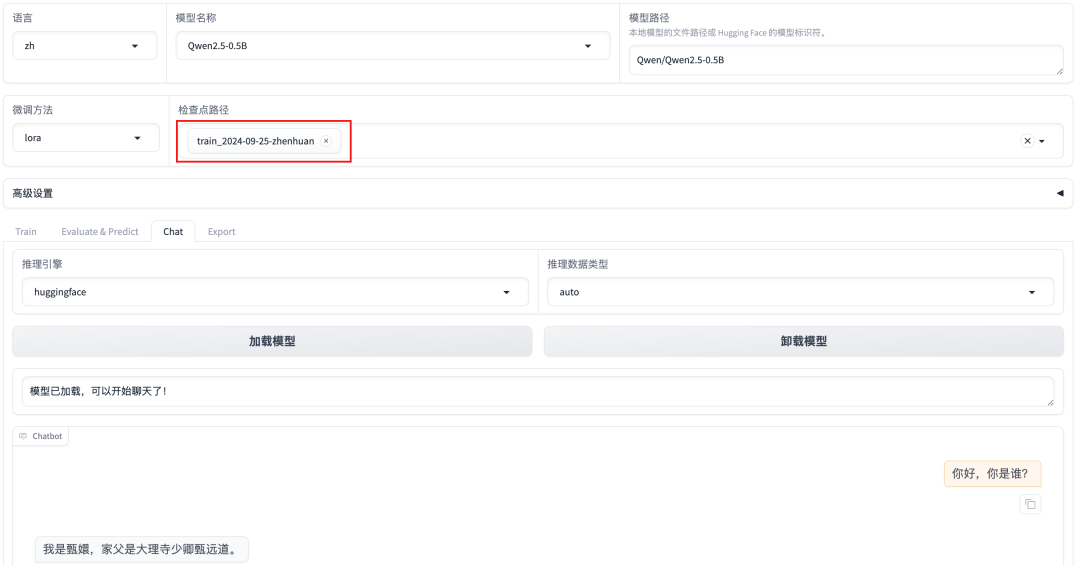
3、测试
微调完成,在Chat页面进行加载模型测试,记得选择检查点路径。
同样的提问:,结果如下图所示:
- 使用Ollama工具部署微调的模型
使用LLaMA-Factory微调出来的LoRA模型文件格式,并不能直接部署到Ollama工具中,需要进行格式转换。
1、在llamafactory的webui Export页面导出模型;
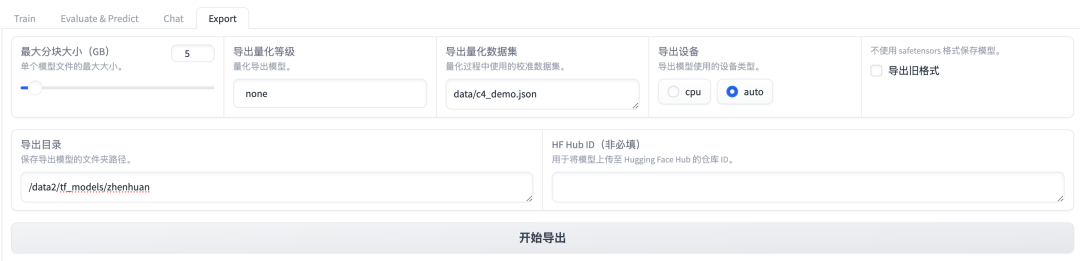
2、使用llama.cpp转换格式
git clone https://github.com/ggerganov/llama.cpp.git``cd llama.cpp/``python convert_hf_to_gguf.py /data2/tf_models/zhenhuan --outfile /data2/ollama_models/zhenhuan.gguf
3、使用ollama导入模型
创建ModelFile文件,内容如下:
FROM /opt/zhenhuan.gguf
复制文件到ollama容器,并执行导入和运行模型命令
docker cp /data2/ollama_models/zhenhuan.gguf ollama:/opt/``docker cp ModelFile ollama:/opt/ModelFile``docker exec -it ollama bash``ollama create my-model -f /opt/ModelFile``ollama list``ollama run my-model
运行就可以进行问答了
- 微调的关键点
以上只是一个简单的微调过程,只能作为一个概要的整体认识,真正要微调一个领域模型,还需要很多的工具。
**1、准备微调数据集。**数据质量是决定模型效果的关键,可以手工、可以工具提取,真正好的数据集需要花不少的心思;
2、微调效果评估的核心指标。微调大语言模型时,评估其效果是否良好是非常重要的。微调效果的好坏主要取决于模型在训练集和验证集上的表现,同时需要结合学习率和损失值等指标,来判断是否出现了过拟合或欠拟合的问题。
要判断微调效果,可以通过以下几个指标:
a. 损失值(Loss)
损失值是衡量模型预测结果和真实结果之间差距的一个量化指标。在训练过程中,模型通过最小化损失函数逐步调整权重。通常有两种损失值需要关注:
-
训练损失(Training Loss):模型在训练数据上的损失值。
-
验证损失(Validation Loss):模型在验证数据集上的损失值。
理想情况下,训练损失和验证损失应该同时下降,并保持接近。如果训练损失较低,而验证损失较高,则可能存在过拟合问题。
b. 准确率或其他特定指标
根据任务不同,可能会选择不同的指标来评估模型性能,例如:
-
分类任务:准确率、精确率、召回率、F1-score 等。
-
生成任务:BLEU、ROUGE、Perplexity(困惑度)等。
通过在验证集或测试集上评估这些指标,观察它们是否稳定提高来判断模型微调的效果。
3、过拟合与欠拟合
a. 过拟合(Overfitting)
过拟合是指模型在训练数据上表现良好,但在未见过的数据(如验证集或测试集)上表现较差。过拟合的原因通常是模型学习到了训练数据中的噪音或细节,导致无法很好地泛化到新数据。
- 症状:训练损失很低,但验证损失较高,且验证集性能(准确率、F1等)较差。
过拟合示例:
-
训练损失:持续下降。
-
验证损失:开始下降但随后上升。
b. 欠拟合(Underfitting)
欠拟合是指模型在训练集上无法有效学习到数据模式,通常表现为训练损失和验证损失都较高,模型性能差。
- 症状:训练损失较高,验证损失同样较高,且随着训练过程,损失没有明显降低。
欠拟合示例:
-
训练损失:较高并且下降缓慢。
-
验证损失:与训练损失差不多,且持续较高。
3、学习率与微调效果的关系。 学习率决定了模型在每次迭代中调整权重的步幅大小,是影响微调效果的重要超参数。如果学习率设置不当,可能导致过拟合或欠拟合。
a. 学习率过高
学习率过高时,模型更新权重的步幅过大,导致难以收敛,表现为训练损失不稳定,甚至在下降和上升之间波动。
-
症状:训练和验证损失的下降幅度不明显,且在训练过程中可能出现波动。
-
表现:模型在训练过程中“跳过”了最优权重,没有收敛到最优解。
b. 学习率过低
学习率过低时,模型更新权重的步幅过小,导致训练过程变得非常缓慢,甚至无法有效训练模型。
-
症状:损失值下降缓慢,训练时间延长,但模型性能提升不明显。
-
表现:模型在局部最优解陷入停滞。
最后,要判断大模型的微调效果,主要是通过分析损失值和性能指标的变化趋势来判断是否存在过拟合或欠拟合问题。学习率、损失值和模型的训练曲线是最为重要的参考指标。通过动态调整学习率、引入正则化和使用早停策略,可以有效改善微调效果。
5)大语言模型的使用
大语言模型的使用有很多应用,如Kimi、扣子、豆包等,都可以免费使用,然而使用下来,还是ChatGPT效果是最好的。我们也可以在本地部署大语言模型,利用开源的模型构建本地模型库。
1、本地部署
安装Ollama,它是一个统一的大模型管理框架,支持很多的模型,并提供标准的API。
docker pull ollama/ollama``docker run -d -v /data2/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
安装web-ui(非必须)
docker pull ghcr.nju.edu.cn/open-webui/open-webui:main`` ``docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://xxx.xxx.xxx.xxx:11434 \``-e HF_ENDPOINT=https://hf-mirror.com \``-v /data2/licsh-test/open-webui:/app/backend/data \``--name open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:main
2、在线对话
进入容器,在命令行运行和使用模型
[root@k001 ~]# docker exec -it ollama bash``root@04a192844cfd:/# ollama run llama3.2:latest``>>> 你好``😊 Ni hao! Welcome! How can I assist you today?`` ``>>> 使用中文回答``😊 你好!我是这里的服务员,怎么能帮助您呢? 🤔`` ``>>> Send a message (/? for help)
3、API调用
curl -X POST http://127.0.0.1:11434/api/generate \` `-H "Content-Type: application/json" \` `-d '{` `"model": "llama3.2",` `"prompt": "你好, 你叫什么名字?你能做什么?",` `"stream": false` `}'
二、智能体
1)什么是智能体
智能体(Agent)是指能够自主执行任务、感知环境并做出决策或行为的计算系统或实体。
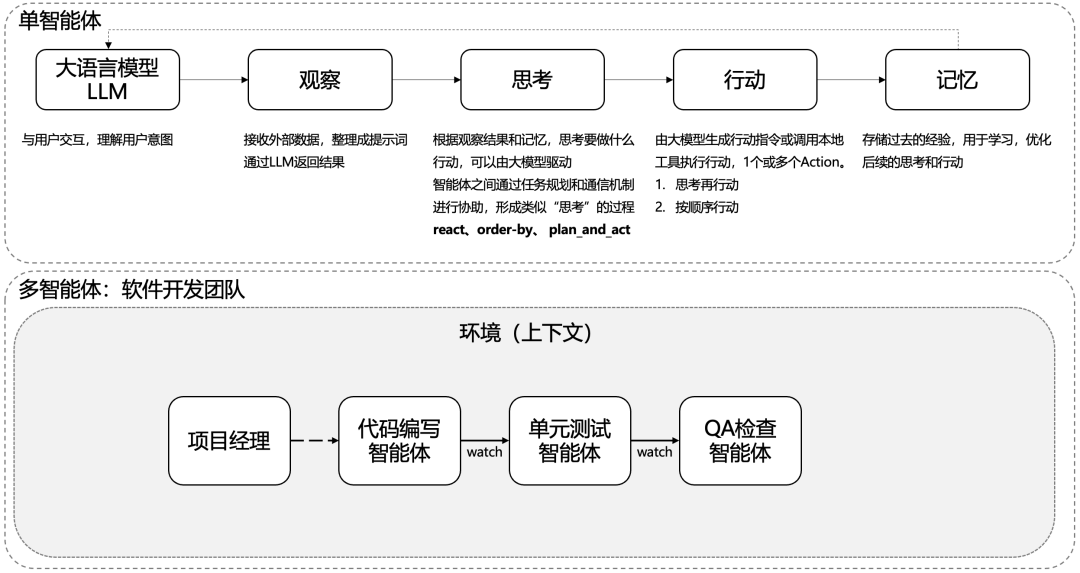
1、单智能体
单智能体分为观察、思考、行动、记忆四大部分。
-
观察。 接收外部数据,整理成提示词,通过LLM返回结果;
-
思考。 根据观察结果和记忆,思考要做什么行动,可以由大模型驱动智能体之间通过任务规划和通信机制进行协助,形成类似“思考”的过程:react、order-by、 plan_and_act;
-
行动。 由大模型生成行动指令或调用本地工具执行行动,1个或多个Action。包括思考再行动、按顺序行动;
-
记忆。 存储过去的经验,用于学习,优化后续的思考和行动。
2、多智能体
多智能体是由多个单智能体相互组合而成,类似一个团队的每个角色,各自负责不同的模块内容。通过环境上下文的消息进行交互。
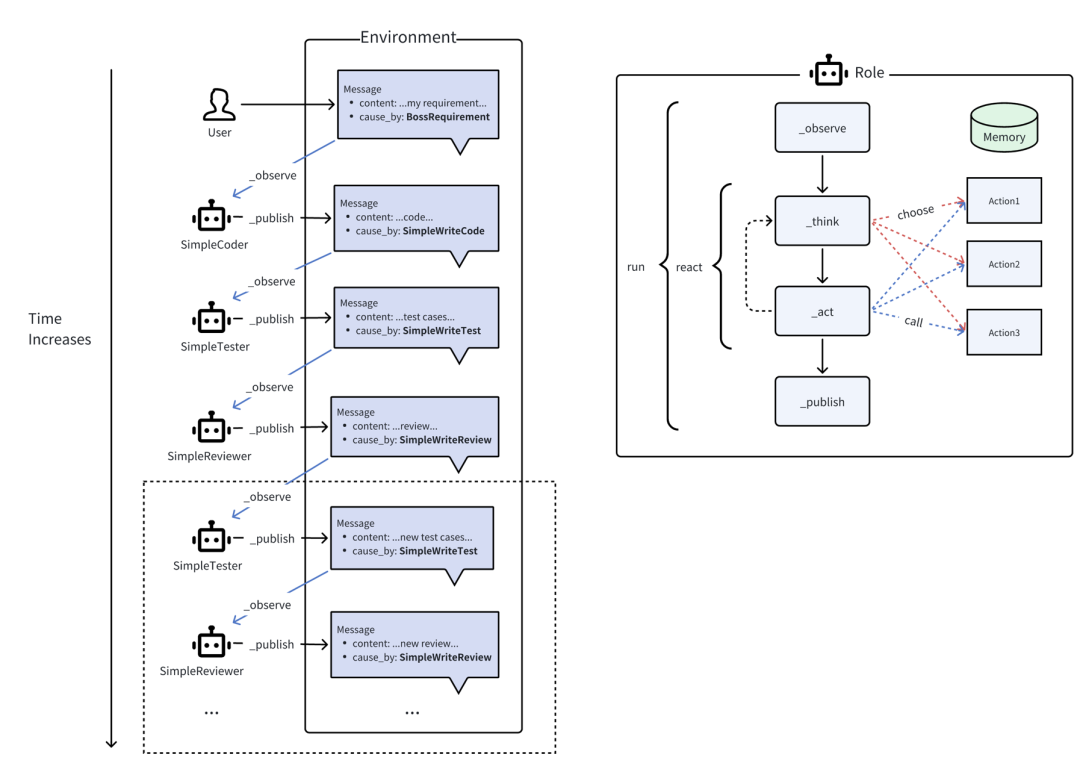
以上可以参考MetaGPT框架,其用于开发智能体。
三、大语言模型与智能体的关系
大语言模型与智能体之间的关系密切,尤其是在智能体的构建和运作中,大语言模型发挥了关键作用。
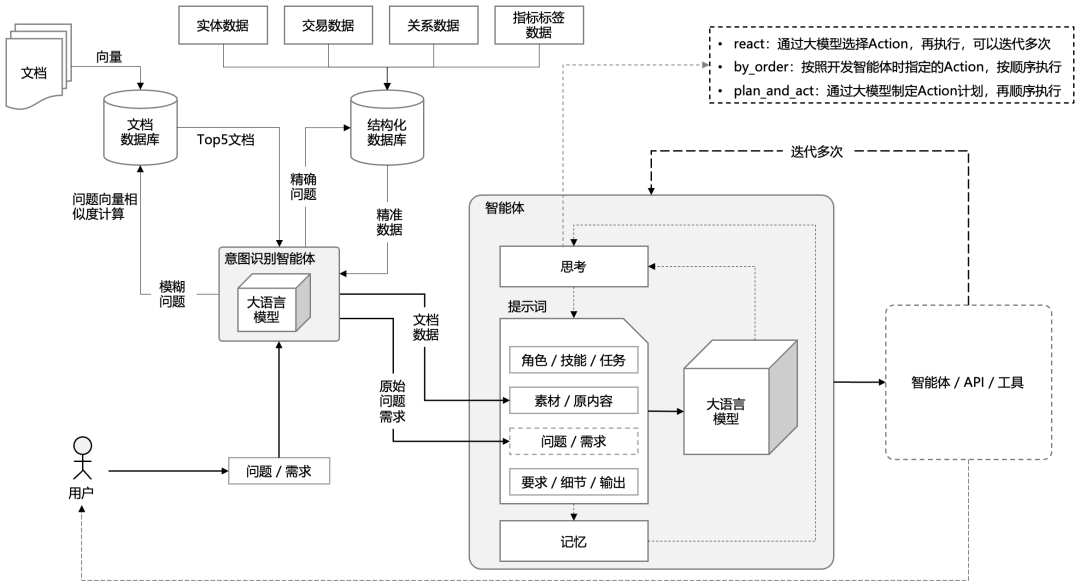
1. 大语言模型为智能体提供自然语言理解和生成能力
大语言模型的核心优势在于其强大的自然语言处理(NLP)能力。通过预训练和微调,这些模型可以理解和生成人类语言,成为智能体与用户之间交互的关键组件。智能体利用大语言模型,可以:
-
理解用户输入的自然语言命令或问题;
-
生成符合上下文的合理答案或回应;
-
将复杂的任务指令转化为具体的操作;
这种能力使得智能体能够与用户通过语言沟通,而不需要依赖复杂的编程或命令行输入,使得智能体的交互更加自然、流畅。
2. 大语言模型充当智能体的“大脑”
智能体的核心任务是感知环境、决策、行动,而大语言模型则可以充当其“推理引擎”或“大脑”。智能体通过大语言模型获取强大的知识推理和信息处理能力,以支持其在复杂环境中作出合理决策。例如:
-
基于大语言模型生成的内容,智能体可以对任务进行分解和规划;
-
大语言模型的知识库为智能体提供了广泛的背景信息,帮助它处理广泛的任务和问题;
3. 增强智能体的学习和适应能力
大语言模型通过海量的数据训练,积累了丰富的领域知识,这为智能体的自主学习和适应环境提供了基础。智能体可以利用大语言模型处理多领域问题,并在面对新问题时灵活调整行为。这种学习能力和语言模型的泛化能力,使智能体不仅能在特定领域表现出色,还能在广泛应用场景中进行调整和适应。
4. 大语言模型与智能体的协同作用
大语言模型不仅增强了智能体的自然语言能力,还为智能体提供了更加复杂的推理和规划功能。例如,结合思维链(Chain-of-Thought)等推理策略,智能体能够分步骤解决问题,形成复杂的行为计划。这种结合大语言模型的智能体,不仅能响应简单请求,还能通过多轮对话或复杂推理执行复杂任务。
5. 大语言模型作为智能体的任务接口
大语言模型还可以作为智能体与外部世界(如数据库、系统、其他智能体)的接口。通过对自然语言指令的理解和执行,智能体能够调用其他系统的API、执行数据库查询或进行自动化工作流,从而完成任务执行。
大语言模型是现代智能体的重要支撑,通过为智能体提供自然语言理解、推理、知识获取和复杂任务执行的能力,两者的结合极大地提升了智能体的智能化水平和应用广度。在智能体技术的发展过程中,大语言模型不仅是其核心组件,还使得智能体能够更好地与人类沟通,处理复杂任务,并适应动态的环境。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈

















 1215
1215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









