






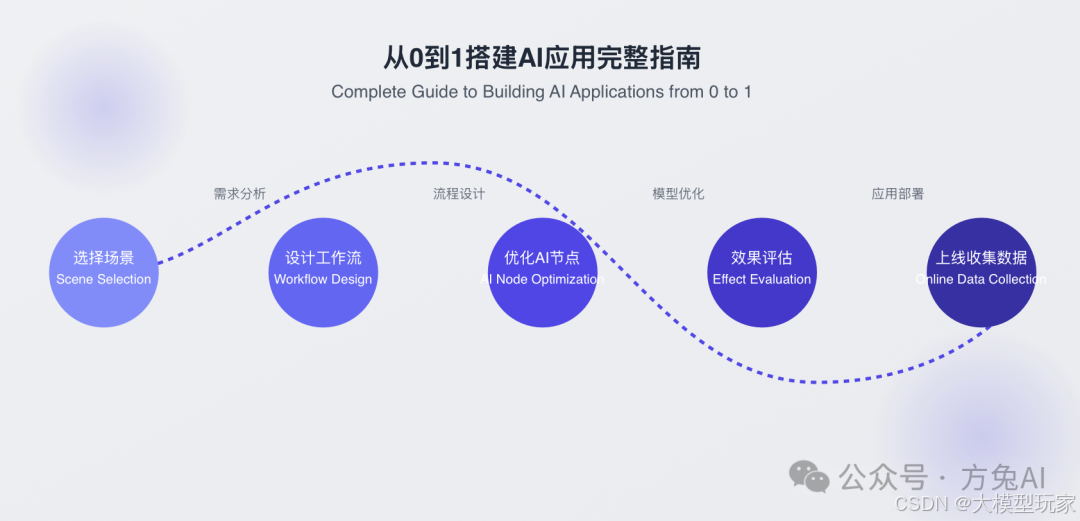
前言
当我学习大模型训练知识时,发现网上很多文章都过于偏重技术实战,充斥着代码和算法公式。对于不懂算法和懂一点Python代码的我来说,看到就会心生胆怯,不得已跳过或者直接放弃阅读,导致学的很慢。所以我想写一篇无代码和公式通俗易懂的讲解大模型的如何训练的文章。
如果将大语言模型比作一个学生,那么训练过程就像是一个"学习"的过程。今天,让我们通过简单的比喻,了解垂直领域大语言模型是如何一步步从"菜鸟"蜕变为"专家"的。
1. 预训练(Pretrain):学习基础知识
就像学生需要先阅读大量教科书获取基础知识,大模型也需要先"阅读"海量文本数据。这个阶段叫预训练(Pretraining)。阅读数据包括:互联网文章、电子图书、百科全书和新闻报道等,比如维基百科、Common Crawl等海量文本数据。让我们举个例子,这样更容易理解,下面是一条预训练数据。

2. 增量预训练(Continue Pretrain):学习专业知识
使用过ChatGPT的朋友都知道,它处理企业场景中额专业任务时准确率不高,本质的原因是它没有垂直领域的知识。所以这个阶段的目标是让模型阅读大量专业知识。模型需要学习领域专业知识、行业术语、专业规范和"行业黑话",才能理解用户问题的含义。
目前有很多开源大模型,所以想要训练一个领域模型可以直接在开源模型的基础上进行Continue Pretrain,难度比从头训练简单了许多。
不同领域需要不同的专业数据,例如:
医疗:医学教材、临床指南、学术论文和诊疗手册等。
法律:法律法规、判例文书、法理解释和专业论文。
金融:金融教材、研究报告、政策文件、市场分析等专业资料。
数据格式与预训练(pretrain)阶段的例子相同。

3. 指令微调( Fine-tune):做练习题
学生需要做大量练习题来掌握知识要点,学会运用知识解决问题。同样,大模型也需要通过大量练习来学习如何解决问题。通过大量的"问答对"数据,模型可以掌握解题规律、生成答案的格式等技能,这个阶段就是微调。微调的方法有很多种,下篇文章会进行详细说明。
训练数据格式:
-
• 医疗问答单轮对话:问:糖尿病的早期症状有哪些?答:主要表现为"三多一少":多饮、多尿、多食、体重下降。建议及时就医检查。
-
• 法律问答单轮对话:问:签订劳动合同需要注意什么?答:主要注意以下几点:合同期限、工作内容、薪资待遇、工作时间。
-
• 保险多轮问答示例:
-
• 问:30岁的人需要哪些保险?答:医疗险,解决生病住院门诊报销风险;重疾险,解决因重大疾病无法工作的收入损失风险。问: 重疾险购买时应该关注哪些问题?答:1.重度疾病、中度疾病、轻度疾病 是否都包含;\n 2.轻、中度 高发疾病是否包含在内;\n 3. ……
4. 人类反馈强化学习(RLHF-Reinforcement Learning from Human Feedback ):老师指导
就像学生在老师指导下不断改进,老师指出学生的错误并给出正确答案,大模型也通过人类标注和评分数据来优化其回答。目的是训练它:专业水准、表达方式、回答质量等方面,同时也训练模型拒绝回答敏感问题或涉及黄赌毒等内容。
数据格式:
{ “messages”: [{ “role”: “user”, “content”: “头疼应该怎么办?” }], “chosen”: { “role”: “assistant”, “content”: “面对头痛问题,建议您按以下步骤处理:\n1. 先观察症状:是否伴随发烧、恶心,持续多久,疼痛位置和性质如何\n2. 可以采取的缓解方法:适当休息、保持空气流通、根据情况使用冷热敷\n3. 如果出现剧烈头痛、持续时间长或伴随其他症状,建议及时就医检查\n\n温馨提示:头痛可能由多种原因引起,建议优先就医诊断,避免盲目服用止痛药。” }, “rejected”: { “role”: “assistant”, “content”: “吃止痛药就好了。” } }
{ “messages”: [{ “role”: “user”, “content”: “房东无故涨房租怎么办?” }], “chosen”: { “role”: “assistant”, “content”: “遇到房东无理涨租,建议您:\n1. 先核实合同条款:检查租赁合同中关于租金调整的约定和合同期限\n2. 采取以下维权方式:\n - 保持冷静,先与房东协商沟通\n - 准备当地租赁市场价格作为参考\n - 保留所有沟通证据(短信、录音等)\n3. 如协商无果,可以:\n - 向住建部门投诉\n - 申请调解\n - 必要时通过法律途径解决\n\n温馨提示:在租约期内,房东不得单方面涨租。” }, “rejected”: { “role”: “assistant”, “content”: “不用给他涨,直接告他去。” } }
{ “messages”: [{ “role”: “user”, “content”: “如何选择合适的重疾险?” }], “chosen”: { “role”: “assistant”, “content”: “选择重疾险需要综合考虑以下因素:\n1. 个人情况评估:\n - 年龄与健康状况\n - 家族病史\n - 经济承受能力\n - 现有保险配置\n2. 产品要素对比:\n - 保障范围(建议选择前症、轻症、中症、重症都覆盖的产品)\n - 赔付次数(单次/多次赔付)\n - 等待期和除外责任\n3. 保额建议:\n 建议保额=(年收入×5-10倍)+预期医疗费用\n\n温馨提示:建议咨询专业保险顾问,根据个人实际情况制定最适合的方案。” }, “rejected”: { “role”: “assistant”, “content”: “买保额最高的就行了。” } }
注释:以上是JSON数据格式。“user”+"content"表示用户问题,“assistant”+"content"表示模型答案,"chosen"是正确回答,"rejected"是错误回答。
5. 不同场景的训练策略
根据不同应用场景,训练策略也需要调整,不需要所有训练阶段都走一遍,因为每一步都有算力、人力、时间成本。
对话类场景:如医生AI助手,需要 Fine-tune → RLHF ,既要专业又要会"说话",需要专业资料、真实对话和人工反馈数据。如果对于专业问题回答效果不佳则可以考虑 Continue Pretrain。
单一任务:如信息提取、产品推荐只需要一次对话即结束了。这类场景做Fine-tune就可以取的不错效果了。
结语
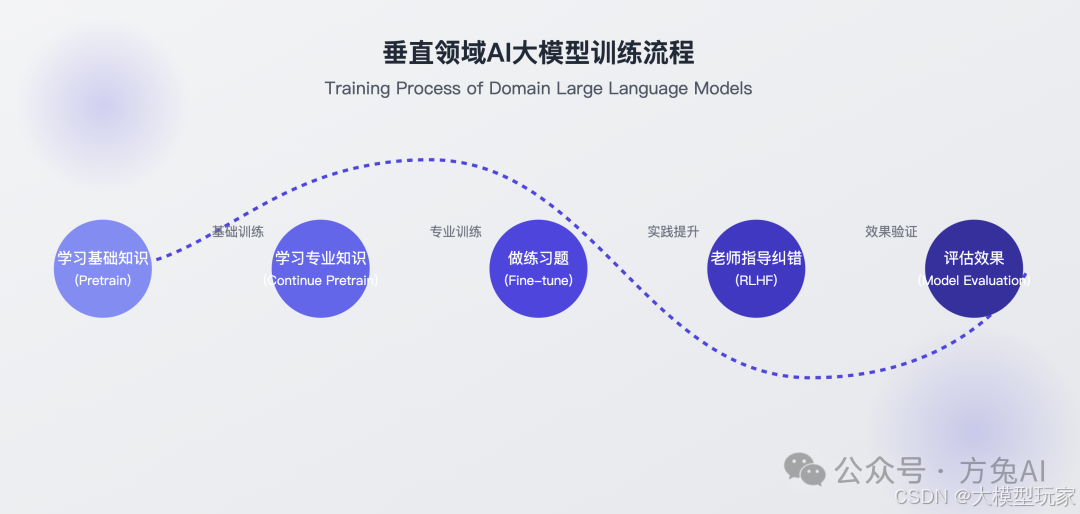
一个 通用模型 长为 垂直模型,需要经过:学习专业知识(Continue Pretrain )→ 做练习题(Fine-tune )→ 老师指导纠错(RLHF)→评估效果(Model Evaluation)。评估标准的设计有很多种,我们后面展开再聊,但有一个认知很重要:评估标准对于客观评价模型能力至关重要,这个阶段就像软件测试一样,决定上线后的质量。
模型训练是一件高成本的事情且不是必须的,如果你是做一个Copilot(助手 ) ,提示词+工作流 是一个高性价比的选择 。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









