







前几个月 Meta HSTU 点燃各大厂商对 LLM4Rec 的热情,一时间,探索推荐领域的 Scaling Law、实现推荐的 ChatGPT 时刻、取代传统推荐模型等一系列话题让人兴奋,然而理想有多丰满,现实就有多骨感,尚未有业界公开真正复刻 HSTU 的辉煌。这里面有很多原因,可能是有太多坑要踩,也有可能是 Meta HSTU 的基线较弱,导致国内已经卷成麻花的推荐领域难以应用 HSTU 产生突破性效果。

然而做起来困难并不代表不去做,总要有真的勇士率先攻克难关迈出一步。字节前几天(2024.9.19 发布 arxiv)公开的工作 ⌜HLLM⌟(分层大语言模型)便是沿着这一方向的进一步探索,论文内也提及了 follow HSTU:


论文题目:
HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling
论文链接:
https://arxiv.org/abs/2409.12740
代码链接:
https://github.com/bytedance/HLLM
这里我针对全文进行一个详细解析,也会有一些疑问,欢迎评论区探讨以及点赞收藏。
1. 背景
传统推荐问题:推荐重要的是建模 user、item feature,主流方法是 ID-based,将 user、item 转为 ID 并创建对应的 embedding table,然而一般都是 embedding 参数很大而模型参数较小,这会导致以下问题:
- 严重依赖 ID feature 在冷启动时表现不好
- 模型较小难以建模复杂且多样的用户兴趣
过往 LLM 探索方向:大致分为三种:
- 利用 LLM 提供一些信息给推荐系统
- 将推荐系统转变为对话驱动的形式
- 修改 LLM 不再只是文本输入/输出,比如直接输入 ID feature 给 LLM
LLM4Rec 挑战:其中一个 issue 是在相同时间 span 情况下,相比 ID-based 方法 LLM 的输入更长,复杂度更高;另一个是相对于传统方法 LLM-based 方法提升并不显著。
三个关键问题:LLM 应用到推荐有三个问题需要评估:
- LLM 预训练权重的真正价值:模型权重蕴含着世界知识,但是如何激活这些知识,只能使用文本输入吗?这也为之后使用 feature 输入埋下伏笔;
- 对推荐任务进行微调是有有必要性?直接使用 pretrain 还是说要进一步微调?
- LLM 是否可以应用在推荐系统中并呈现 scaling law?
由此提出了 Hierarchical Large Language Mode****l(HLLM)架构,训练 Item LLM(用来提取 item feature)和 User LLM (item feature 作为输入,用于预测下一个 item),实验表明在公开数据集上显著超越 ID-based 方法,并呈现了 Scaling Law 特性。在抖音落地,A/B 实验显示在重要指标上增长 0.705%。
2. 方法
2.1 HLLM
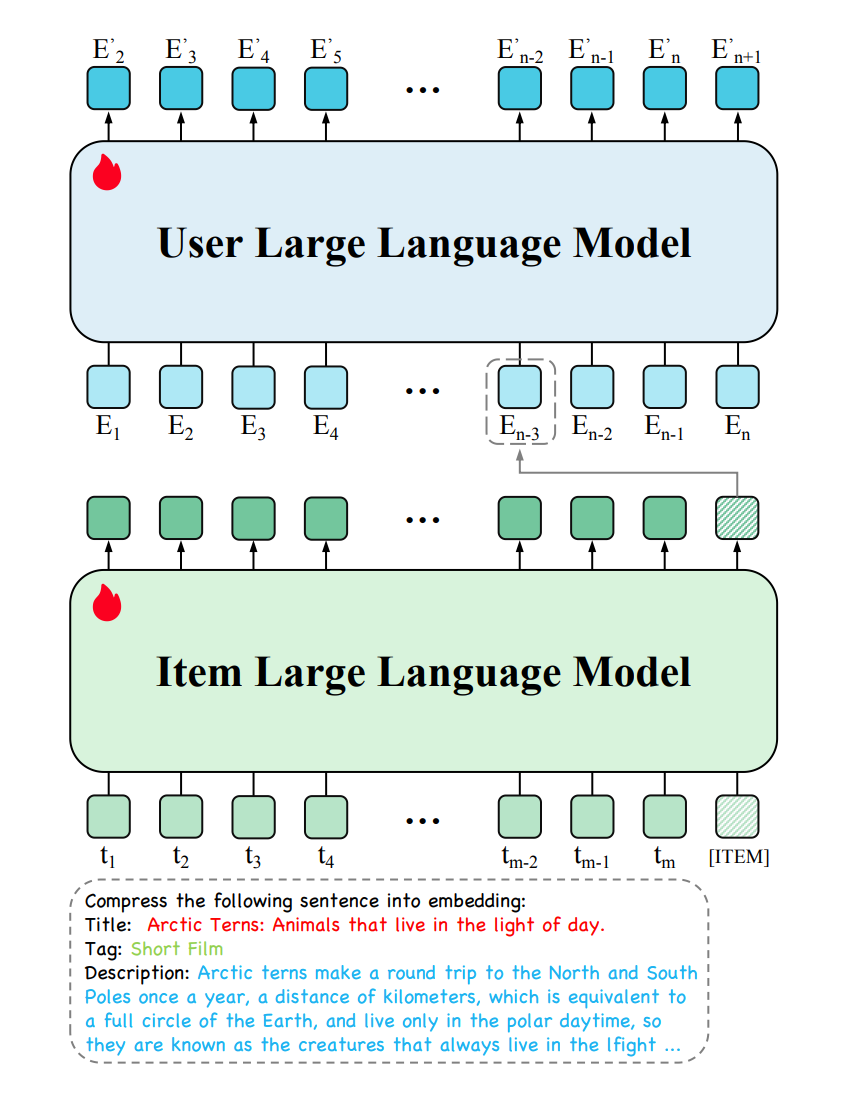
分为 Item LLM 和 User LLM,两者参数并不共享,都是可训练的并通过 next item predict 来进行优化。
可以直接基于已经预训练好的(例如 llama、baichuan&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1614
1614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









