






最近被顶刊TPAMI24上的一篇特征融合文章惊艳到了!
作者提出了一种新型融合方法:FreqFusion,只需几行代码,便能显著涨点!该模型通过自适应滤波和特征重采样,来增强密集图像预测任务中的特征一致性和边界清晰度,在语义分割、目标检测、实例分割和全景分割等任务中都性能卓越!
实际上,特征融合的改进一直是非常热门的研究方向,每年都有多篇顶会产出!主要在于,特征融合在机器学习和数据科学中起着至关重要的作用,它有助于提高模型的性能、鲁棒性和泛化能力,同时降低过拟合风险,并促进计算效率和解释性的提升。
为方便大家紧跟领域前沿,找到更多灵感启发,我给大家准备了11种最新的改进思路和配套源码,全部来自一区顶会,质量有保证!
论文原文+开源代码需要的同学看文末
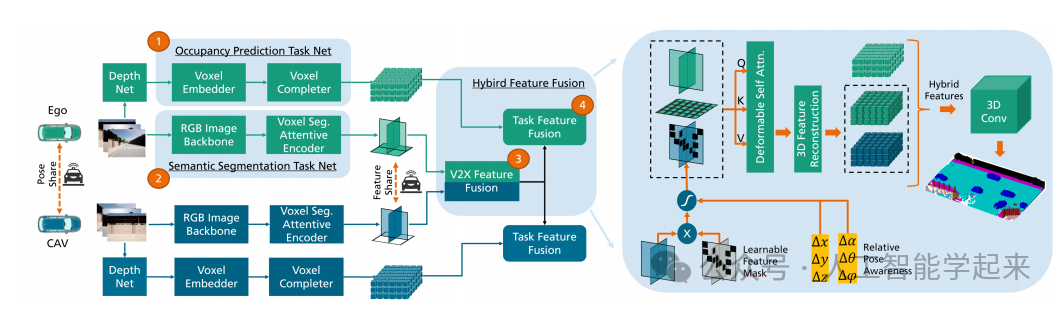
论文:Collaborative Semantic Occupancy Prediction with Hybrid Feature Fusion in Connected Automated Vehicles
内容
该论文提出了一种名为CoHFF(Collaborative Hybrid Feature Fusion)的框架,用于在连接的自动驾驶车辆中进行协作式语义占用预测。该方法通过在车辆之间共享语义和占用任务特征,以及通过车辆到一切(V2X)通信网络交换压缩的正交注意力特征,来改善局部3D语义占用预测。
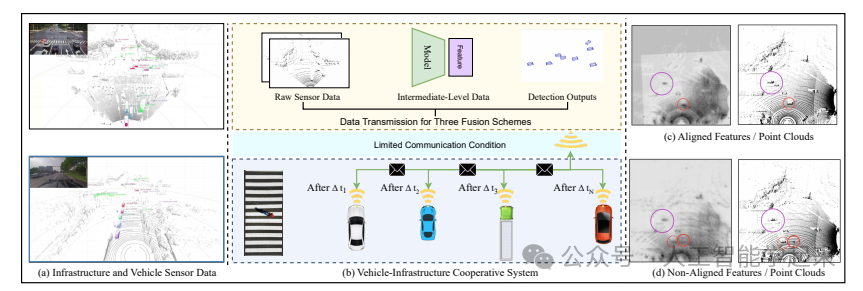
论文:Flow-Based Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
内容
该论文提出了一个名为FFNet(Feature Flow Net)的新型合作检测框架,用于车辆基础设施协同3D(VIC3D)目标检测,该框架通过传输特征流而不是静态图像提取的特征图,利用序列基础设施帧的时间一致性,引入了一种自监督训练方法,使FFNet能够从原始基础设施序列中生成具有特征预测能力的特征流。
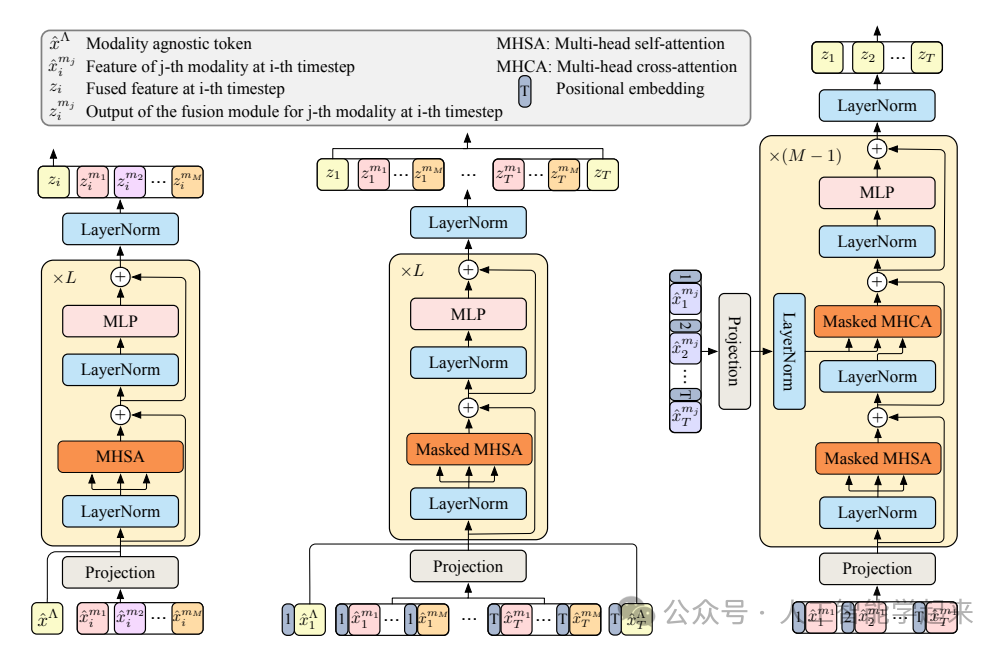
论文:Anticipative Feature Fusion Transformer for Multi-Modal Action Anticipation
内容
该论文介绍了一种名为Anticipative Feature Fusion Transformer (AFFT)的新型多模态特征融合方法,用于动作预测任务,通过在早期阶段统一多模态数据,优于流行的分数融合方法,并在EpicKitchens-100和EGTEA Gaze+数据集上取得了超越以往方法的最新结果。
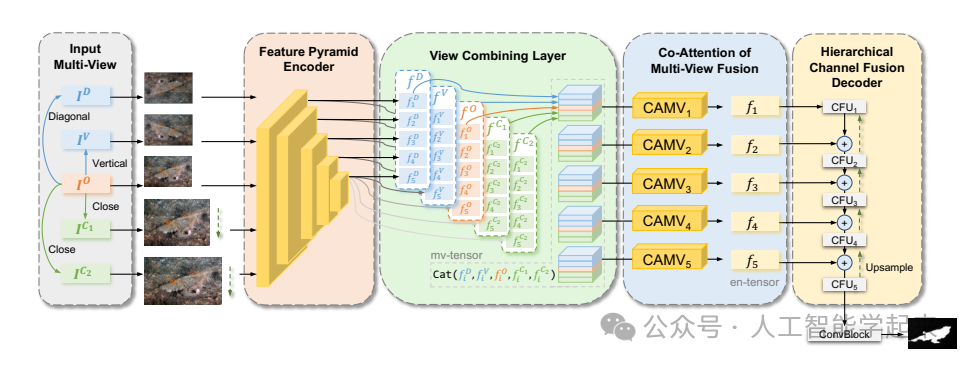
论文:MFFN:Multi-view Feature Fusion Network for Camouflaged Object Detection
内容
该论文提出了一个名为MFFN(Multi-view Feature Fusion Network)的多视图特征融合网络,用于检测在复杂环境中高度隐蔽的对象。该网络通过数据增强生成多种观察方式(多视图),并应用这些多视图特征进行比较和融合,以捕获关键的边界和语义信息,利用不同视图之间的依赖性和交互作用,通过一个两阶段的注意力模块来整合多视图特征,并设计了一个局部-整体模块以迭代方式探索不同特征图之间的通道上下文线索。
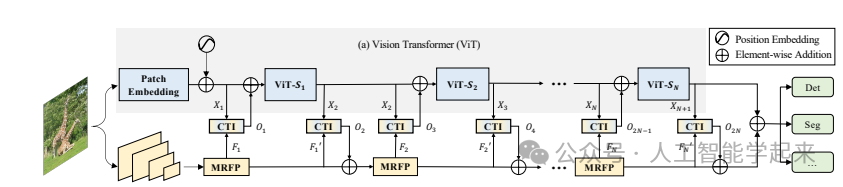
论文:ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions
内容
该论文介绍了一种名为ViT-CoMer的视觉变换器(Vision Transformer),它通过结合卷积神经网络(CNN)的多尺度特征交互来增强密集预测任务的性能,通过注入空间金字塔多感受野卷积特征到ViT架构中,有效缓解了ViT在局部信息交互和单尺度特征表示方面的局限性。
关注下方《人工智能学起来》
回复“11特融”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏

















 3641
3641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









