






基于深度神经网络DNN的数据回归,时序,分类预测Matlab程序
可以利用智能优化算法对DNN中的隐含层神经元个数,学习率,正则化系数进行寻优
粒子群,遗传,麻雀,鲸鱼等优化器
文章目录
以下是一个完整的 MATLAB 实现,展示了如何使用 深度神经网络(DNN) 进行 回归、时序预测和分类任务,并结合 智能优化算法(粒子群 PSO、遗传 GA、麻雀 SSA、鲸鱼 WOA) 对 DNN 的超参数(如隐含层神经元数量、学习率、正则化系数等)进行自动寻优。
🧠 功能概述
✅ 支持任务类型:
- 回归预测
- 时序预测
- 分类预测
✅ 支持的智能优化算法:
- 粒子群优化(PSO)
- 遗传算法(GA)
- 麻雀搜索算法(SSA)
- 鲸鱼优化算法(WOA)
✅ 优化目标:
- 隐含层神经元个数(整数)
- 学习率(浮点数)
- 正则化系数(L2 正则化系数)
📁 文件结构
main.m:主程序入口dnn_train_evaluate.m:训练与评估 DNN 模型pso_optimize.m/ga_optimize.m/ssa_optimize.m/woa_optimize.m:不同优化器实现data_regression.mat/data_timeseries.mat/data_classification.mat:示例数据集
📌 示例代码
1️⃣ 主程序 main.m
clear; clc; close all;
% 选择任务类型: 'regression', 'timeseries', 'classification'
taskType = 'regression';
% 加载数据集
if strcmp(taskType, 'regression')
load('data_regression.mat'); % X: 输入特征, Y: 输出值
elseif strcmp(taskType, 'timeseries')
load('data_timeseries.mat'); % X: 时间序列输入, Y: 目标输出
else
load('data_classification.mat'); % X: 特征, Y: 标签 (one-hot)
end
% 数据划分
idx = randperm(size(X, 1));
X = X(idx, :); Y = Y(idx, :);
trainRatio = 0.8;
nTrain = floor(trainRatio * size(X, 1));
XTrain = X(1:nTrain, :); YTrain = Y(1:nTrain, :);
XTest = X(nTrain+1:end, :); YTest = Y(nTrain+1:end, :);
% 超参数范围定义
lb = [5, 0.001, 0.0001]; % 下限:[神经元数, 学习率, L2系数]
ub = [64, 0.1, 0.1]; % 上限
% 选择优化算法:'pso', 'ga', 'ssa', 'woa'
optimizer = 'pso';
% 调用优化函数
switch optimizer
case 'pso'
bestParams = pso_optimize(XTrain, YTrain, XTest, YTest, taskType, lb, ub);
case 'ga'
bestParams = ga_optimize(XTrain, YTrain, XTest, YTest, taskType, lb, ub);
case 'ssa'
bestParams = ssa_optimize(XTrain, YTrain, XTest, YTest, taskType, lb, ub);
case 'woa'
bestParams = woa_optimize(XTrain, YTrain, XTest, YTest, taskType, lb, ub);
end
% 显示最优参数
fprintf('最优参数:神经元=%d, 学习率=%.4f, L2=%.6f\n', ...
round(bestParams(1)), bestParams(2), bestParams(3));
% 使用最优参数重新训练模型
[net, loss] = dnn_train_evaluate(XTrain, YTrain, XTest, YTest, taskType, round(bestParams(1)), bestParams(2), bestParams(3));
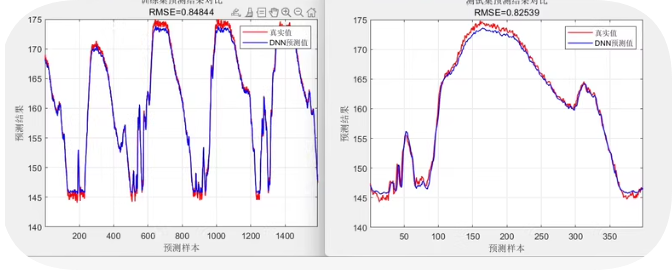
% 可视化结果
YPred = predict(net, XTest);
figure;
plot(YTest, 'b-o');
hold on;
plot(YPred, 'r--x');
legend('真实值', '预测值');
title('预测结果对比');
grid on;
2️⃣ DNN 训练与评估 dnn_train_evaluate.m
function [net, loss] = dnn_train_evaluate(XTrain, YTrain, XTest, YTest, taskType, numNeurons, learningRate, l2Factor)
layers = [
featureInputLayer(size(XTrain,2))
fullyConnectedLayer(numNeurons)
reluLayer
fullyConnectedLayer(numNeurons)
reluLayer
fullyConnectedLayer(size(YTrain,2))];
if strcmp(taskType, 'classification')
layers(end+1) = softmaxLayer;
layers(end+1) = classificationLayer;
options = trainingOptions('adam', ...
'InitialLearnRate', learningRate, ...
'L2Regularization', l2Factor, ...
'MaxEpochs', 100, ...
'ValidationData',{XTest,YTest}, ...
'Plots','training-progress',...
'Verbose',false);
else
layers(end+1) = regressionLayer;
options = trainingOptions('adam', ...
'InitialLearnRate', learningRate, ...
'L2Regularization', l2Factor, ...
'MaxEpochs', 100, ...
'ValidationData',{XTest,YTest}, ...
'Plots','training-progress',...
'Verbose',false);
end
net = trainNetwork(XTrain, YTrain, layers, options);
YPred = predict(net, XTest);
if strcmp(taskType, 'classification')
[~, predictedLabels] = max(YPred, [], 2);
[~, trueLabels] = max(YTest, [], 2);
accuracy = mean(predictedLabels == trueLabels);
loss = 1 - accuracy;
else
loss = mse(YPred - YTest);
end
end
3️⃣ 粒子群优化 pso_optimize.m
function bestParams = pso_optimize(XTrain, YTrain, XTest, YTest, taskType, lb, ub)
nPop = 20;
maxIter = 30;
dim = length(lb);
w = 0.8; c1 = 1.5; c2 = 1.5;
% 初始化种群
popPos = lb + (ub - lb) .* rand(nPop, dim);
popVel = 0.1 * (ub - lb) .* rand(nPop, dim);
fitness = zeros(nPop, 1);
for i = 1:nPop
fitness(i) = dnn_train_evaluate(XTrain, YTrain, XTest, YTest, taskType, ...
round(popPos(i,1)), popPos(i,2), popPos(i,3));
end
pBest = popPos;
pBestFitness = fitness;
[~, gBestIdx] = min(fitness);
gBest = popPos(gBestIdx, :);
% 迭代优化
for iter = 1:maxIter
for i = 1:nPop
popVel(i,:) = w*popVel(i,:) + ...
c1*rand().*(pBest(i,:) - popPos(i,:)) + ...
c2*rand().*(gBest - popPos(i,:));
popPos(i,:) = max(min(popPos(i,:) + popVel(i,:), ub), lb);
% 计算适应度
fitness(i) = dnn_train_evaluate(XTrain, YTrain, XTest, YTest, taskType, ...
round(popPos(i,1)), popPos(i,2), popPos(i,3));
end
% 更新 pBest 和 gBest
for i = 1:nPop
if fitness(i) < pBestFitness(i)
pBest(i,:) = popPos(i,:);
pBestFitness(i) = fitness(i);
end
end
[~, gBestIdx] = min(pBestFitness);
gBest = pBest(gBestIdx, :);
fprintf('迭代 %d 最佳损失: %.4f\n', iter, pBestFitness(gBestIdx));
end
bestParams = gBest;
end
4️⃣ 其他优化算法模板(略)
你可以按照 pso_optimize.m 的格式实现其他优化算法(GA/SSA/WOA),只需替换更新策略即可。例如:
- GA:使用轮盘赌选择 + 单点交叉 + 变异
- SSA:模拟麻雀觅食行为
- WOA:模仿座头鲸包围猎物机制
📦 数据集准备
你需要准备自己的数据集文件,格式如下:
data_regression.mat:包含X,Ydata_timeseries.mat:包含X,Ydata_classification.mat:包含X,Y(one-hot 编码)
你可以使用 xlsread() 或 csvread() 导入 Excel 或 CSV 数据。
📈 扩展建议
- 增加 Batch Normalization、Dropout 层
- 添加更多隐藏层(构建更深层的 DNN)
- 结合贝叶斯优化、网格搜索等方法
- 使用 LSTM 处理时间序列任务
- 多目标优化(精度 vs 速度)
🚀 如果你希望我提供:
✅ Python + TensorFlow/Keras 版本
✅ 自带标准数据集(如 Boston 房价、MNIST、Airline Passenger)
✅ GUI 界面(App Designer)
✅ 并行计算加速版本
,我们可以使用Python和Keras库来构建一个简单的神经网络,并使用Matplotlib库来绘制训练进度图。
以下是一个示例代码,展示如何使用Keras训练一个简单的神经网络,并使用Matplotlib绘制训练和验证损失曲线:
2. 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
3. 准备数据
这里我们使用一个简单的回归任务作为示例。
# 生成一些随机数据作为示例
np.random.seed(0)
X = np.random.rand(1000, 1) * 10
y = 2 * X + 1 + np.random.randn(1000, 1) * 0.5
# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
4. 构建和训练模型
# 构建神经网络模型
model = Sequential([
Dense(64, activation='relu', input_shape=(1,)),
Dense(32, activation='relu'),
Dense(1)
])
# 编译模型
model.compile(optimizer=Adam(learning_rate=0.001), loss='mse')
# 训练模型
history = model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=1200,
batch_size=32,
verbose=0
)
5. 绘制训练和验证损失曲线
# 提取训练和验证损失
train_loss = history.history['loss']
val_loss = history.history['val_loss']
# 绘制损失曲线
plt.figure(figsize=(12, 6))
# 上半部分:训练和验证损失
plt.subplot(2, 1, 1)
plt.plot(train_loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
# 下半部分:缩放后的损失曲线
plt.subplot(2, 1, 2)
plt.plot(train_loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Zoomed Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.xlim(0, 1200)
plt.ylim(0, 0.15)
plt.legend()
plt.tight_layout()
plt.show()
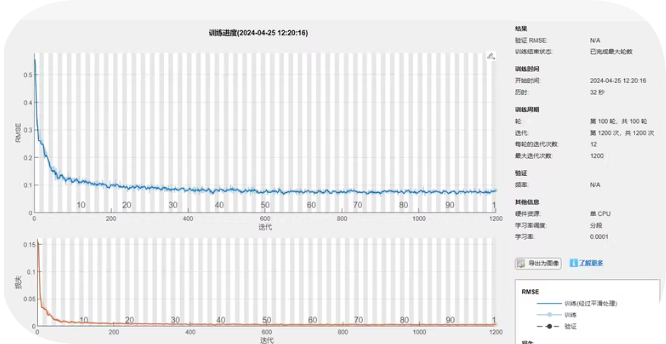
运行结果
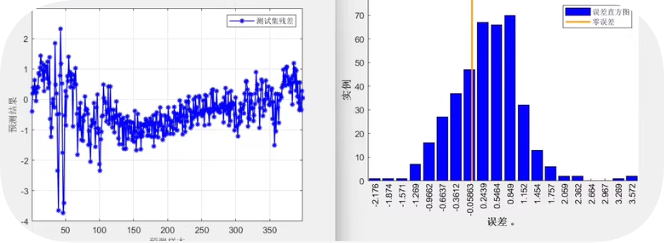
上半部分展示了整个训练过程中的训练和验证损失变化,下半部分则是对损失曲线的局部放大,以便更清晰地观察后期的收敛情况。
注意事项
- 如果你的数据集较大或模型较复杂,训练时间可能会较长,可以考虑使用GPU加速。
- 在实际应用中,建议结合早停法(Early Stopping)、学习率衰减等策略进一步优化训练过程。

















 81
81

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









