






像GPT-4这样的大型语言模型(LLM),虽然能生成强大且通用的自然语言,但也严重受限于训练数据的边界。为解决这一问题,近期业界热议基于RAG(检索增强生成)的系统——但究竟什么是RAG?它能做什么?为何值得关注?
本文将深入解析:
-
• RAG的核心原理
-
• 如何实现基于RAG的LLM应用(附完整代码示例)
什么是RAG?
检索增强生成(Retrieval Augmented Generation, RAG)是一种自然语言处理技术,它使ChatGPT等大型语言模型(LLM)能够生成超出其训练数据范围的自定义输出。没有RAG的LLM应用,就如同要求ChatGPT总结一封邮件却不提供邮件原文作为上下文。
RAG系统由两大核心组件构成:检索器和生成器。
检索器负责从知识库中搜索与输入最相关的信息片段,生成器则基于预定义的提示模板,利用检索结果构造提示词序列,最终生成与输入连贯且相关的响应。优秀的RAG系统是优秀检索器与生成器协同工作的产物——这也是当前大多数LLM评测指标专注于评估检索器或生成器的根本原因。
以下是RAG架构的示意图:
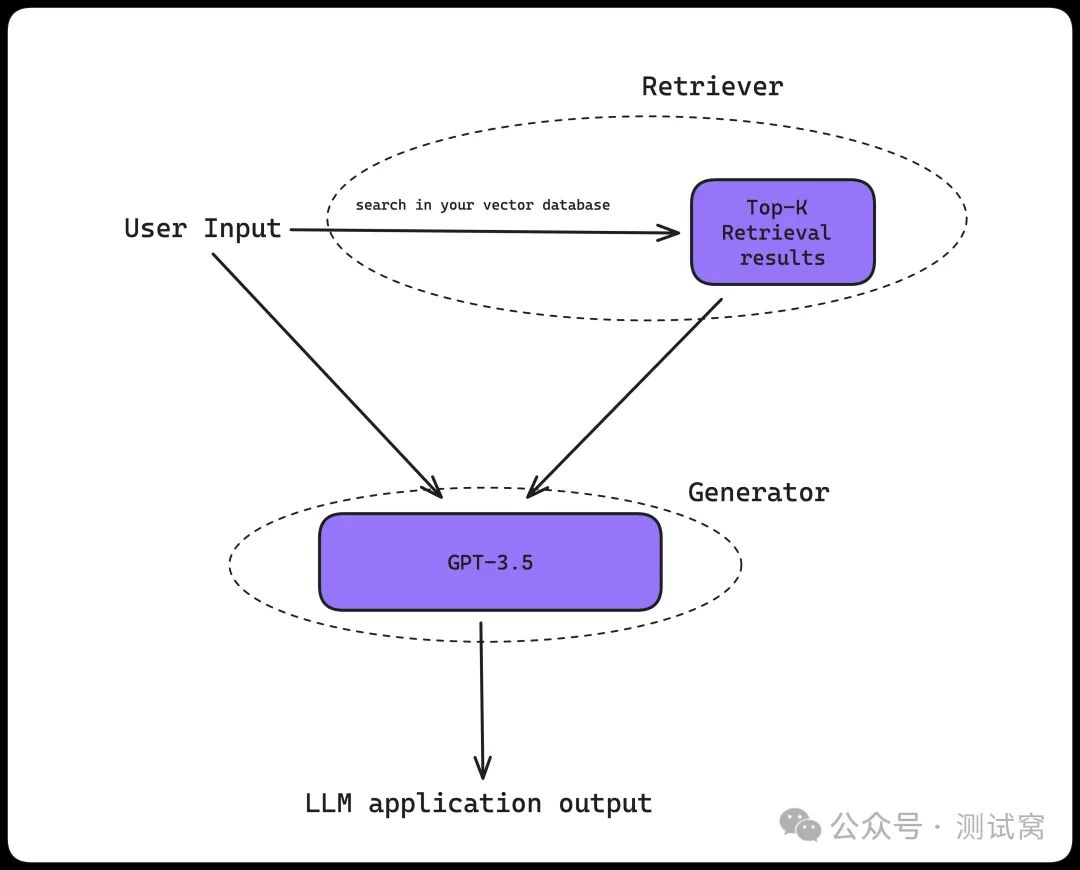
一个典型的RAG架构
在多数场景中,知识库由存储于向量数据库(如ChromaDB)中的向量嵌入(Vector Embeddings)构成。检索器的工作流程如下:
-
1. 在运行时将用户输入编码为高维向量(如使用OpenAI的
text-embedding-3-small模型) -
2. 在向量空间中检索与输入向量最相关的Top-K结果(注:K为可调超参数,通常取5-10)
-
3. 根据余弦相似度或欧氏距离对结果进行排序(距离越小,相关性越高)
检索结果随后被处理成提示词序列,传递至生成器——即你选用的LLM(如GPT-4、LlaMA 2等)。

一个检索器
对于技术上想了解的更加深入的用户,下面是检索器用于提取高相关性结果的常用模型及其原理:
-
1. 神经网络嵌入模型(如OpenAI/Cohere的嵌入模型) :
通过将文档映射到多维向量空间,基于向量位置邻近度对文档排序。该方法能理解输入文本与文档库之间的语义关联及相关性。 -
2. 最佳匹配25(BM25) :
一种提升文本检索精度的概率检索模型。通过结合词频(term frequency)和逆文档频率(inverse document frequency),量化词项重要性,确保常见词与罕见词均影响相关性排序。 -
3. 词频-逆文档频率(TF-IDF) :
计算词项在单个文档中的重要性(相对于整个语料库)。通过对比词项在文档中的出现频率与其在语料库中的稀缺性,生成全面的相关性排序。 -
4. 混合搜索(Hybrid Search) :
为不同方法(如神经网络嵌入、BM25、TF-IDF)分配差异化权重,优化搜索结果的相关性。
应用场景
检索增强生成(RAG)通过结合文本检索与生成能力提升响应质量,已在多个领域实现广泛应用。基于Confident公司与多家企业合作开发LLM应用的经验,以下是排在前四的应用场景:
-
1. 客户支持/用户引导聊天机器人
-
• 从内部文档中检索数据,生成个性化回复。
-
-
2. 数据提取
-
• 从PDF等文档中提取关键信息。
-
-
3. 销售支持
-
• 从LinkedIn个人资料及邮件历史中检索数据,生成个性化外联消息。
-
-
4. 内容创作与优化
-
• 基于历史对话数据生成建议回复。
-
在接下来的章节中,我们将构建一个通用问答(QA)机器人,你可通过调整以下两个核心组件,将其功能定制为前文所述的任意场景。
项目配置
我们将基于你的专属知识库,打造一个智能问答(QA)聊天机器人。本文暂不涉及知识库的索引构建(后续会单独详解),重点聚焦机器人核心功能的实现。
我们将使用Python,ChromaDB作为向量数据库,OpenAI负责生成文本向量嵌入及对话补全,整个项目将基于你指定的维基百科页面构建聊天机器人。
准备工作
第一步,新建项目目录并安装必要依赖库:
mkdir rag-llm-app
cd rag-llm-app
python3 -m venv venv
source venv/bin/activate你的控制台现在应该是这样:
(venv)
安装依赖
pip install openai chromadb 新建 main.py 文件(项目的核心入口):
touch main.py 获取API密钥
-
1. 访问 OpenAI平台获取API密钥(如果还没有)。
-
2. 在终端中设置环境变量:
export OPENAI_API_KEY="你的OpenAI_API密钥" 构建基于RAG的LLM应用
首先创建一个检索器类(Retriever) ,用于根据用户问题从ChromaDB中检索最相关的数据。
操作步骤:
-
1. 打开
main.py文件 -
2. 粘贴以下代码:
import chromadb
from chromadb.utils import embedding_functions
import openai
client = chromadb.Client()
client.heartbeat()
class Retriver:
def __init__(self):
pass
def get_retrieval_results(self, input, k):
openai_ef = embedding_functions.OpenAIEmbeddingFunction(api_key="your-openai-api-key", model_name="text-embedding-ada-002")
collection = client.get_collection(name="my_collection", embedding_function=openai_ef)
retrieval_results = collection.query(
query_texts=[input],
n_results=k,
)
return retrieval_results["documents"][0]此处的 openai_ef 是 ChromaDB 内部使用的嵌入函数,用于将输入文本转化为向量。当用户向聊天机器人发送问题时,系统会通过 OpenAI 的 text-embedding-ada-002 模型生成该问题的向量嵌入,随后在 ChromaDB 的 collection 向量空间(已包含你的知识库数据,本教程默认你已完成数据索引)中执行向量相似性搜索。此过程可检索出与输入最相关的 Top K 条结果。
在定义完检索器后,粘贴以下代码创建生成器:
class Generator:
def __init__(self, openai_model="gpt-4"):
self.openai_model = openai_model
self.prompt_template = """
You're a helpful assistant with a thick country accent. Answer the question below and if you don't know the answer, say you don't know.
{text}
"""
def generate_response(self, retrieval_results):
prompts = []
for result in retrieval_results:
prompt = self.prompt_template.format(text=result)
prompts.append(prompt)
prompts.reverse()
response = openai.ChatCompletion.create(
model=self.openai_model,
messages=[{"role": "assistant", "content": prompt} for prompt in prompts],
temperature=0,
)
return response["choices"][0]["message"]["content"]在 generate_response 方法中,我们基于检索器提供的 retrieval_results构建了多级提示模板。这些提示被发送至 OpenAI 接口,驱动大模型生成最终回答。通过RAG 架构,你的问答机器人能够融合检索结果与生成能力,输出高度定制化的响应!
现在将所有组件整合,形成完整流程:
class Chatbot:
def __init__(self):
self.retriver = Retriver()
self.generator = Generator()
def answer(self, input):
retrieval_results = self.retriver.get_retrieval_results(input)
return self.generator.generate_response(retrieval_results)
# Creating an instance of the Chatbot class
chatbot = Chatbot()
while True:
user_input = input("You: ") # Taking user input from the CLI
response = chatbot.answer(user_input)
print(f"Chatbot: {response}")你已成功构建首个基于 RAG(检索增强生成) 的聊天机器人。
总结
通过本文,你已掌握:
-
1. RAG的核心原理:融合检索与生成能力提升模型表现
-
2. RAG的典型应用场景:客户支持、数据提取、销售支持等
-
3. RAG应用开发全流程:从向量数据库搭建到生成逻辑集成
不过你可能已发现,自主构建RAG应用涉及复杂工程(如数据索引、检索优化),这并非易事。幸运的是,现有开源框架(如 LangChain 和 LlamaIndex)能大幅简化开发流程,助你快速实现本文演示的所有功能。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 251
251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









