






10月7日,发布在arxiv上的一篇名为Strong Model Collapse的论文,由Meta 、纽约大学和加州大学洛杉矶分校的研究人员共同发表的研究表明在训练大型神经网络(如 ChatGPT 和 Llama)时,由于训练语料库中包含合成数据而导致的模型性能严重下降的现象,即模型崩溃(Model Collapse)。
文章主要探讨了在大规模神经网络训练中出现的一种严重性能下降现象——模型崩溃(model collapse)。作者使用监督回归设置并证明了即使只有极小比例的人工数据也会导致模型崩溃,并且随着训练集规模增大,性能并没有得到提高。此外,作者还研究了增加模型大小是否加剧或缓解模型崩溃的问题。通过理论和实验验证,作者发现较大的模型可能会放大模型崩溃,但在超过插值阈值后,它们可能有助于减轻崩溃的影响。这些结果对于理解大规模神经网络训练中的问题具有重要意义。
研究背景
模型崩溃是指当 AI 模型的训练数据中包含大量由其他模型生成的合成数据时,模型性能会出现严重退化。这种现象会导致模型在后续训练周期中逐渐过拟合到合成数据的模式上,这些模式可能无法充分代表现实世界数据的丰富性和多样性。随着模型越来越依赖于前代 AI 生成的扭曲分布,而不是学习现实世界的准确表示,其泛化到现实世界数据的能力受到损害。
方法描述
该论文提出了一种基于合成数据的方法来提高深度学习模型在真实数据上的性能。具体来说,该方法通过使用两个独立的数据集D1和D2,其中D1是真实数据集,D2是合成数据集,来估计真实数据分布与合成数据分布之间的差异,并利用这些信息来调整模型参数以提高其性能。
1.数据分布: 论文考虑了真实数据分布 D1 和合成数据分布 D2,其中合成数据是从与真实数据分布不同的分布中生成的。
2.模型构建:
论文使用了两种模型进行实验:
- 经典的线性模型(例如岭回归)。
- 通过随机投影近似的神经网络模型,这允许研究者通过调整随机投影的输出维度来研究模型大小对模型崩溃现象的影响。
3.实验设置: 实验在不同的数据混合比例下进行,以观察模型在不同比例的合成数据和真实数据混合时的表现。
4.性能评估: 使用测试误差作为主要的性能评估指标,测试误差是在真实数据分布上评估的,即使模型是在混合数据上训练的。
论文实验
文章主要介绍了模型训练中使用合成数据对模型性能的影响,并通过一系列的对比实验证明了这一影响的存在。具体来说,作者进行了以下两个方面的实验:
第一个实验是关于高维线性回归和随机投影模型在高斯数据上的实验。在这个实验中,作者研究了模型大小(即特征维度)和比例(即合成数据的比例)对模型性能的影响。
实验结果如下图1所示,训练数据总量为n = 500,横轴表示训练数据仅在真实数据上完成,纵轴表示训练是在合成数据和真实输出的混合数据上完成的,从左到右三张图分别显示了不同合成数据的结果。在散点图上,方形点对应于非常高质量的合成数据(即来自接近真实数据分布的分布),菱形对应于高质量的合成数据,三角形对应于低质量,而星形对应于非常低质量的合成数据。色标是参数化率ψ=m / n的对数,其中m捕获的是模型的大小。
图1最左边的图对应于合成数据比真实数据少得多的情况(n= 50个合成数据对n= 450个真实数据)。对于高质量和低质量的合成数据(正方形),最佳的折衷是通过更大的模型。对于较低质量的数据,边界从左到右向上移动;较大的模型不再是应对模型崩溃的最佳模型,最佳模型大小是中等的。
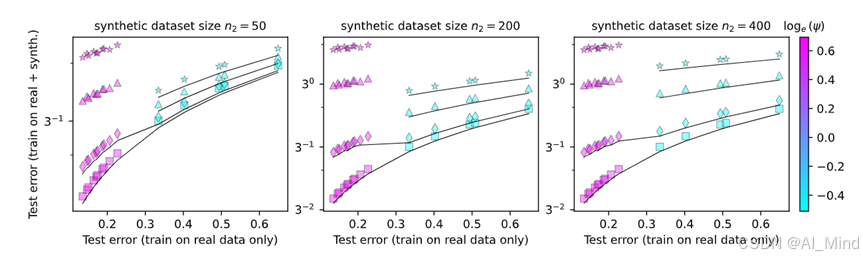 图1:理解模型大小在模型崩溃中的作用
图1:理解模型大小在模型崩溃中的作用
下图2中c^2平方表示合成数据的质量,数值越低,表示合成数据质量越高,p^2代表合成数据占总数据的比重。对于不同级别的数据质量c,图中显示了测试误差作为各种混合比的模型大小的函数(较暗的曲线对应于合成数据的较高分数),误差条对应于5次独立运行。
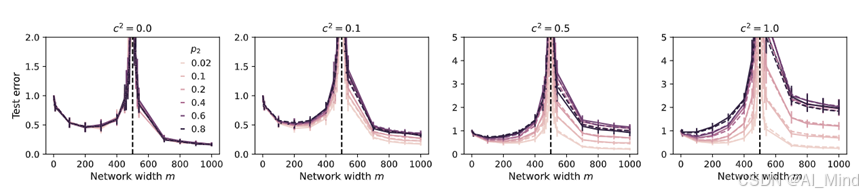 图2:模型大小(网络宽度m)对模型崩溃的影响
图2:模型大小(网络宽度m)对模型崩溃的影响
结果表明,随着模型大小的增加,模型性能会有所提高,但同时也会出现更严重的模型崩溃现象。此外,当合成数据比例较低时,模型性能受到的影响较小,而当合成数据比例较高时,模型性能会明显下降。
第二个实验是关于神经网络在MNIST数据集上以及语言建模任务中的实验。在这个实验中,作者将真实数据与合成数据混合在一起进行训练,并观察模型性能的变化。p2代表合成数据占总数据的比重,结果显示,在这些复杂场景下,合成数据仍然会对模型性能产生显著的影响,而且随着合成数据比例的增加,模型性能会更加恶化。
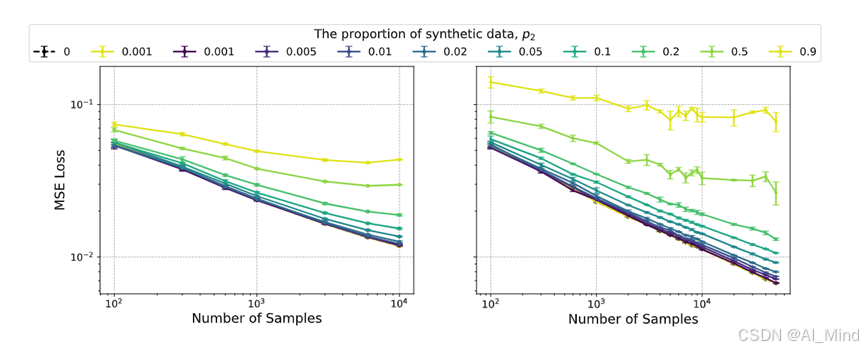 总的来说,本文的实验结果表明,在模型训练过程中使用合成数据可能会导致模型性能下降,特别是在合成数据比例较高的情况下。因此,在实际应用中需要谨慎使用合成数据,并且需要根据具体情况来确定合成数据的比例和质量。
总的来说,本文的实验结果表明,在模型训练过程中使用合成数据可能会导致模型性能下降,特别是在合成数据比例较高的情况下。因此,在实际应用中需要谨慎使用合成数据,并且需要根据具体情况来确定合成数据的比例和质量。
实验验证:
理论结果通过在语言模型和用于图像的前馈神经网络上的实验得到了验证。实验表明,即使训练数据集中只有很小比例的合成数据(例如,仅占总训练数据集的1%),也可能导致模型崩溃。此外,实验还探讨了模型大小对模型崩溃的影响,发现在某些情况下,更大的模型可能会加剧模型崩溃。
结论:
论文通过实验得出结论,模型崩溃是一个普遍存在的现象,即使在训练数据中只包含少量合成数据时也是如此。此外,论文还讨论了如何通过策略性地混合真实数据和合成数据来减轻模型崩溃,但指出这些策略在实践中可能并不可行。

















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









