







这篇博客讲现在很流行的两种网络模型,ResNet和DenseNet,其实可以把DenseNet看做是ResNet的特例
文章地址:
[1]Deep Residual Learning for Image Recognition,CVPR2015
[2]Densely Connected Convolutional Networks,CVPR2016
本篇博客不讲论文的内容,只讲主要思想和我自己的理解,细节问题请自行看论文
Introduction
When it comes to neural network design, the trend in the past few years has pointed in one direction: deeper. 但是问题是:
Is learning better networks as easy as stacking more layers ??
让我们看看在ImageNet上分类winner的网络的深度:
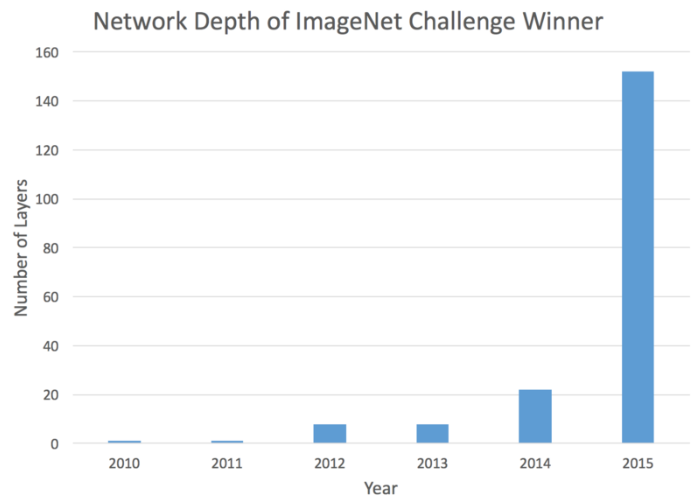
是不是我们通过简单的stack的方式把网络的深度增加就可以提高performance??
答案是NO,存在两个原因
- vanishing/exploding gradients
- degradation problem
Residual
其实思想很简单:
Instead of hoping each few stacked layers directly fit a desired underlying mapping, we explicitly let these layers fit a residual mapping. Formally, denoting the desired underlying mapping as H(x),we let the stacked nonlinear layers fit another mapping of F(x): H(x)-x. The original mapping is recast into F(x)+x.
那么学习到的F(x)就是残差.
Shortcut Connections
思想起源于HighWay Nets,shortcut的好处是:
a few intermediate layers are directly connected to auxiliary classifiers for addressing vanishing/exploding gradients.
通过shortcut的方式(Residual)进行stack的nets(ResNet),可以在加深layers上获得更好的效果
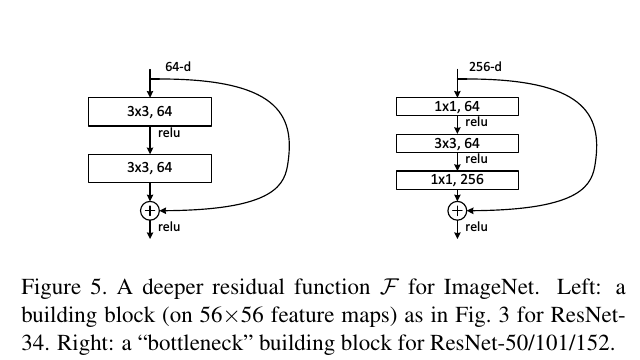
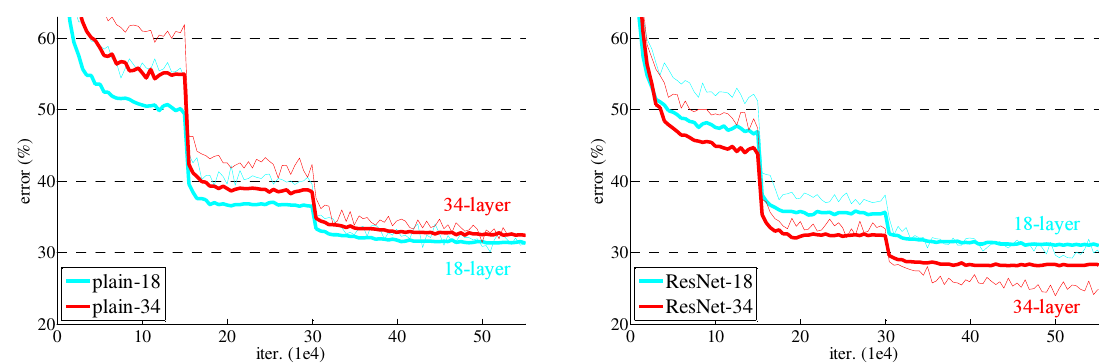
对比在ImageNet上的效果:
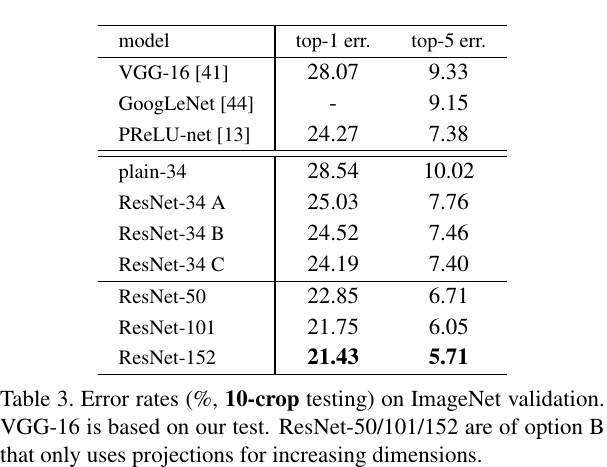
再来个表格对比,更加明显:
DenseNet
一个词概括网络的结构特点就是Dense,一句话概括的话:
For each layer, the feature maps of all preceding layers are treated as separate inputs whereas its own feature maps are passed on as inputs to all subsequent layers.
结构如下所示:
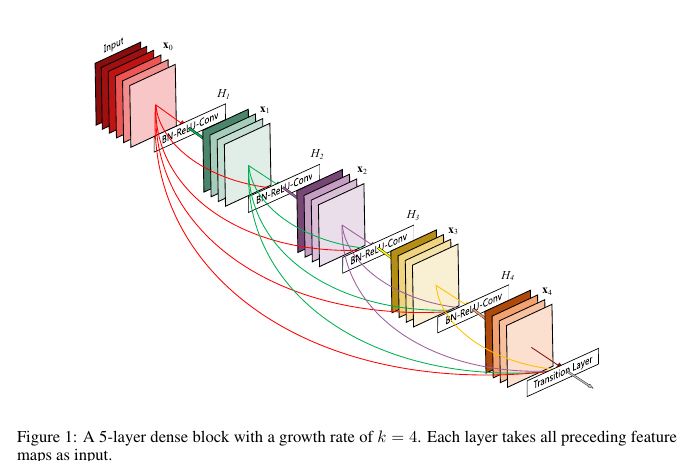
和ResNet相比,最大的区别在于:
Never combine features through summation before they are passed into a layer, instead we provide them all as separate inputs.
对于此网络来说,很明显number of connections适合depth成平方的关系,所以问题是当depth很大的时候是不是已经无法训练了?? 作者是这么说的:
Although the number of connections grows quadratically with depth, the topology encourages heavy feature reuse.
对比ResNet来说:
Prior work has shown that there is great redundancy within the feature maps of the individual layers in ResNets. In DenseNets, all layers have direct access to every feature map from all preceding layers, which means that there is no need to re-learn redundant feature maps. Consequently, DenseNet layers are very narrow (on the order of 12 feature maps per layer) and only add a small set of feature maps to the “collective knowledge” of the whole network.
在Cifar 10等上做分类的网络模型是:

结果:
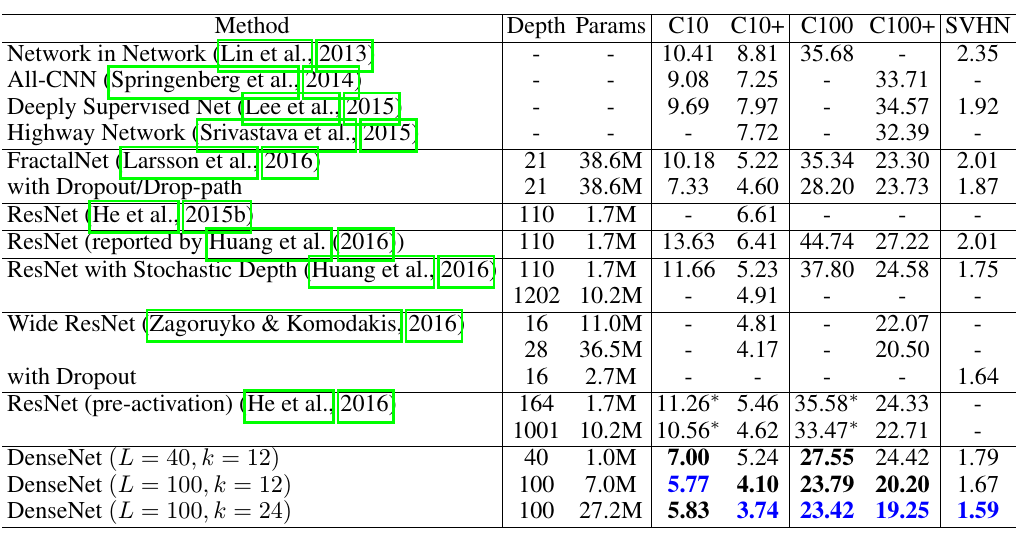
Conclusion
其实无论是ResNet还是DenseNet,核心的思想都是HighWay Nets的思想:
就是skip connection,对于某些的输入不加选择的让其进入之后的layer(skip),从而实现信息流的整合,避免了信息在层间传递的丢失和梯度消失的问题(还抑制了某些噪声的产生).














 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









